一、低级语言与高级语言
1、低级语言
低级语言(Low-level Language)是接近计算机硬件的编程语言,是计算机可以直接执行或接近直接执行的语言。
常见的低级语言包括:
机器语言
- 计算机可以直接执行的二进制代码(即:机器码),由 0 和 1 组成。每一个机器指令对应于特定的处理器操作。
汇编语言
- 汇编语言是机器语言的符号化表示,使用助记符和符号代替机器语言的二进制代码,相较于机器语言更易读(但仍然复杂)。
- 汇编语言需要通过汇编器(Assembler)转换成机器语言才能被计算机执行。
由于直接操作硬件,所以低级语言的性能较高,但其通常与特定的硬件平台相关,导致代码移植性差。
2、高级语言
高级语言(High-level Language)是指接近人类自然语言的编程语言,使代码更容易编写、阅读和维护。
高级语言编写的代码不能直接执行,必须先通过编译器或解释器转换成低级语言(机器语言,即机器码)才能被计算机执行。
高级语言提供了对底层硬件的抽象,使开发者无需关心底层细节,高级语言在经过重新编译或解释后,通常可以在不同平台上运行。
常见的高级语言包括:
- 编译型语言:C、C++、Java、Go、Rust 等。
- 解释型语言:Python、JavaScript、Ruby、PHP 等。
二、编译型语言和解释型语言
高级语言主要有两种:编译型语言、解释型语言。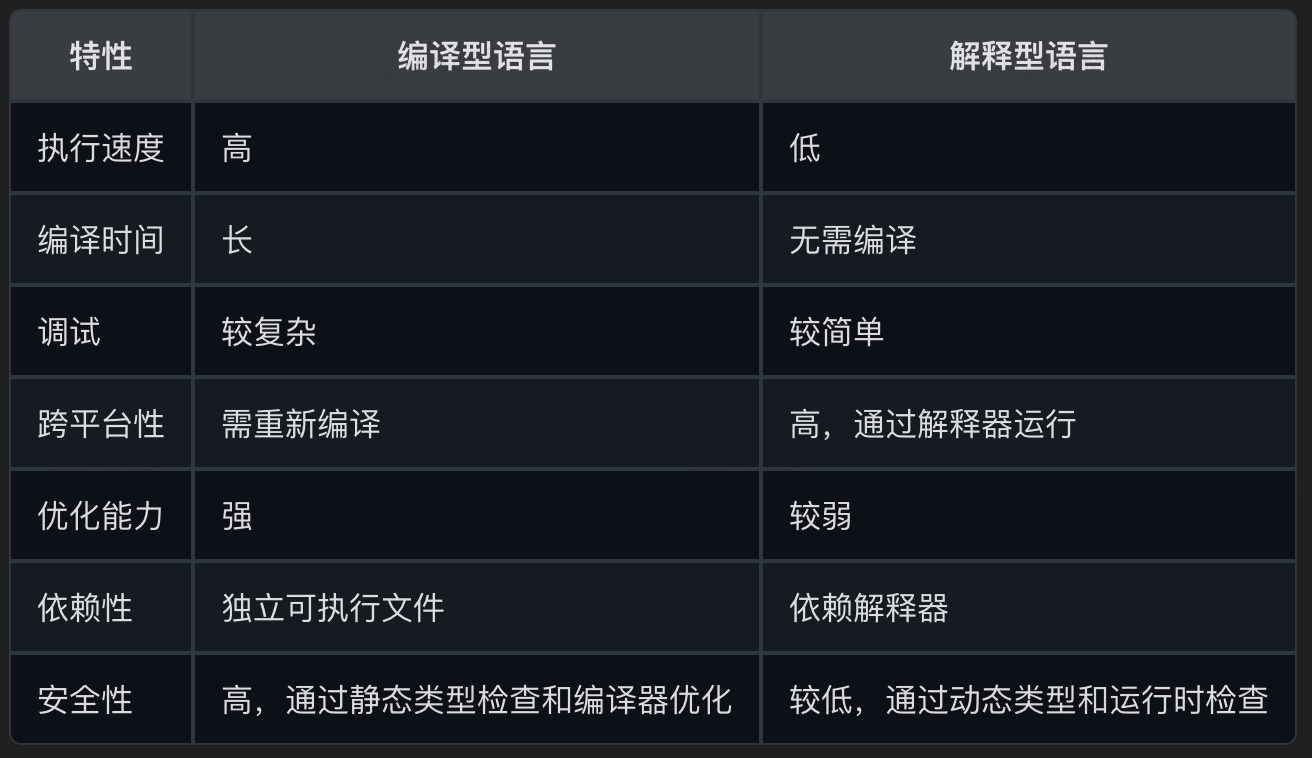
1、编译型语言
在编译型语言写的程序执行之前,需要一个专门的编译过程,把源代码编译成机器语言的文件,即:先编译再执行。
常见的编译型语言有:C、C++、Java、Go、Rust 等。
编译型语言优缺点如下:
- 优点
- 高性能:编译后的机器代码直接在硬件上运行,执行速度快,性能高。
- 优化能力强:编译器可以进行各种优化(如循环展开、内联展开等),以提高代码效率。
- 安全性:编译过程可以进行类型检查和其他静态分析,提前发现潜在的错误。
- 独立性:编译后的可执行文件不依赖于源代码和编译器,可以在没有开发环境的机器上运行。
- 缺点
- 编译时间长:编译过程可能耗时较长,特别是大型项目。
- 调试复杂:编译后的机器代码不易调试,调试信息可能不完整。
- 跨平台性差:编译后的可执行文件通常与特定平台相关,不同平台需要重新编译。
2、解释型语言
解释型语言又称直译式语言、脚本语言,解释型语言不需要事先编译,解释器直接将源代码解释成机器码并立即执行,所以只要某一平台提供了相应的解释器即可运行该程序。
常见的解释型语言有:Python、JavaScript、Ruby、PHP 等。
解释型语言优缺点如下:
- 优点
- 即时性:不需要预先编译,源代码可以直接运行,适合快速开发和调试。
- 跨平台性强:源代码通过解释器运行,可以在不同平台上执行相同的代码。
- 灵活性高:通常具有动态类型和灵活的语法,适合快速迭代和原型开发。
- 缺点
- 性能较低:解释执行的开销较大,执行速度通常比编译型语言慢。
- 依赖解释器:需要解释器才能运行源代码,增加了部署和运行时的依赖。
- 安全性较低:由于动态类型和运行时检查,潜在的错误可能在运行时才发现。
解释型语言的执行流程与编译型语言不同,解释型语言通过解释器逐行解释和执行源代码,不需要预先编译成目标机器代码。解释型语言执行流程如下图:
三、OC 的编译流程
1、概述
iOS 开发常用的语言是 Objective-C 和 Swift,两者都是编译型语言,所以 iOS 代码的执行,都需要经过编译器编译的流程,这里主要看 OC 的编译流程。
无论是高级语言还是低级语言,最终都是在计算机的中央处理器(CPU)上执行的,OC 代码想要被执行,必须先使用编译器将其编译成能在 CPU 上直接执行的机器码,现代编译器工作的主要流程如下:
前端,OC 使用 Clang 作为编译器前端
- 为 LLVM 提供了预处理,词法分析,语法分析,语义分析、错误处理、生成 LLVM IR 等各种各样的功能。在这个过程中,也会对代码进行检查,如果发现出错的或需要警告的会标注出来。
中间端
- 使用优化器(Optimizer)对 LLVM IR 进行优化,优化的目标是提高代码的执行效率和减少代码的体积。
后端,OC 使用 LLVM 作为编译器后端
- 针对不同的架构,生成对应的机器码。
2、LLVM IR
上面提到了 LLVM IR,LLVM IR 是什么呢?
LLVM IR (Intermediate Representation)直译过来是“中间描述”,它是整个编译过程中生成的区别于源码和机器码的一种中间代码。IR 提供了独立于任何特定机器架构的源语,因此它是 LLVM 优化和进行代码生成的关键,也是 LLVM 有别于其他编译器的最大特点。LLVM 的核心功能都是围绕的 IR 建立的,它是 LLVM 编译过程中前端的输出,后端的输入。
LLVM IR 的存在意味着 LLVM 可以作为多种语言的后端,这样 LLVM 就能够提供和语言无关的优化,同时还能够方便的针对多种 CPU 代码生成。
编译器的架构分为前端、优化器和后端。传统编译器(如 BASIC)的前端和后端没有完全分离,耦合在了一起,因而如果要支持一门新的语言或硬件平台,需要做大量的工作。而 LLVM 和传统编译器最大的不同点在于,前端输入的任何语言,在经过编译器前端处理后,生成的中间码都是 IR 格式的。这样做的优点是如果需要支持一种新的编程语言,那么我们只需要实现一种新的前端。如果我们需要支持一种新的硬件设备,那我们只需要实现一个新的后端。
LLVM IR 的三种格式:
- 内存中的编译中间语言
- 硬盘上存储的可读中间格式(以 .ll 结尾)
- 硬盘上存储的二进制中间语言(以 .bc 结尾)
这三种中间格式是完全等价的。
什么是 Bitcode?
Bitcode 其实就是前面提到的 LLVM IR 三种格式中的第三种,即存储在磁盘上的二进制文件(以 .bc 结尾)。
之所以要把 Bitcode 拿出来单独说,是因为 Apple 单独对 Bitcode 进行了额外的优化。从 Xcode 7 开始,Apple 支持在提交 App 编译产物的同时提交 App 的 Bitcode (非强制),并且之后对提交了 Bitcode 的 App 都单独进行了云端编译打包。也就是说,即便在提交时已经将本地编译好的 ipa 提交到 App Store,Apple 最终还是会使用 Bitcode 在云端再次打包,并且最终用户下载到手机上的版本也是由 Apple 在云端编译出来的版本,而非开发人员在本地编译的版本。
这里有一篇文章《Xcode 7 Bitcode的工作流程及安全性评估》,揭示了360团队如何通过一个小 trick 来验证 Apple 审核人员安装的 App 是直接由本地编译出来的版本还是云端通过 Bitcode 编译出来的版本。
测试方式大致是从网上找个两个完全不同的应用,将其中一个的 Bitcode 嵌入到另一个的 MachO 中,并提交到 AppStore,两个应用 UI 上完全不一样。根据被拒信息中截图发现审核人员审核的是从 Bitcode 编译出来的程序。
为什么需要 Bitcode?
Apple 之所以这么做,一是因为 Apple 可以在云端编译过程中做一些额外的针对性优化工作,而这些额外的优化是本地环境所无法实现的。二是 Apple 可以为安装 App 的目标设备进行二进制优化,减少安装包的下载大小。
比如我们在本地编译生成的 ipa 是同时包含了多个 CPU 架构的(armv7、arm64 ),对于 iPhone X 而言 armv7 的架构文件就是无用文件。而 Apple 可以在云端为不同的设备编译出对应 CPU 架构的 ipa ,这样 iPhone X 下载到的 App 就只包含了所需的 arm64 架构文件。
而且,由于 Bitcode 是无关设备架构的,它可以被转化为任何被支持的 CPU 架构,包括现在还没被发明的 CPU 架构。以后如果苹果新出了一款新手机并且 CPU 也是全新设计的,在苹果后台服务器一样可以从这个 App 的 Bitcode 开始编译转化为新 CPU 上的可执行程序,可供新手机用户下载运行这个 App ,而无需开发人员重新在本地编译打包上传。
为什么要废弃 Bitcode?
从 Xcode 14 开始,App Store 不再接受来自 Xcode 14 的 Bitcode 提交,并且不再支持构建部署目标早于 iOS 11 以下的 APP(前一个版本的 Xcode 最低支持到 iOS 9),也不再支持构建 armv7、armv7s 以及 i386 架构的项目。
从 2015 年发布 Xcode 7 支持 Bitcode,到 2022 年发布 Xcode 14 正式废弃 Bitcode,大概经过了 7 年。Apple 为什么要废弃 Bitcode 呢?最根本的原因是 Apple 旗下产品实现了 CPU 架构的统一,随着 M 系列 MacBook 发布,旗下主流产品 iPhone、MacBook 都统一成了 ARM 架构,Bitcode 自然就发挥不了太大的作用了。
并且,如果 Bitcode 对生态要求较高,如果 APP 要支持 Bitcode,就需要保证其所有依赖都支持 Bitcode,否则 Bitcode 无法使用。所以,废弃 Bitcode,还有助于简化开发和发布流程,使得开发者可以更专注于应用本身的开发和优化,而不是处理中间表示和编译的问题。
3、详细编译流程
现代编译器工作流程如下:
现代编译器通常采用模块化设计,将前端和后端分离,以便于维护和扩展。在 iOS 开发中,Objective-C 语言使用 Clang 作为编译器前端(Swift 采用 Swift 作为编译器前端),使用 LLVM 作为编译器后端。
(1)编译器前端(Clang)
预处理
- 处理宏定义、展开头文件、条件编译、删除注释等。
- 生成预处理后的源代码。
词法分析
- 将预处理后的源代码转换为一系列词法单元(tokens)。
- 词法分析器通过模式匹配(通常使用正则表达式)识别词法单元。
- 将预处理后的源代码转换为一系列词法单元(tokens)。
语法分析
- 语法分析器解析 tokens,构建成能被计算机理解的树状结构:抽象语法树 AST(Abstract Syntax Tree)。
语义分析
- 对抽象语法树进行语义检查,确保源代码的语义正确。
- 生成和维护符号表,记录标识符的信息(如类型、作用域、存储位置等)。
中间代码生成
- CodeGen(实现代码生成器)遍历抽象语法树 AST,生成 LLVM IR 中间码。
至此前端工作完成,把 LLVM IR 中间码输入到优化器。
(2)编译器中间端
中间端主要是借助优化器(Optimizer)对中间表示进行各种优化。
以下是优化器的几个主要目标和作用:
减少包体
- 代码压缩:优化器可以通过删除不必要的代码(如死代码)和简化代码结构来减少代码体积。
- 内联展开:内联函数调用有时会增加代码体积,但在某些情况下,优化器可以通过内联展开减少函数调用的开销,从而整体上减少代码体积。
提高执行效率
- 循环优化:优化器可以通过循环展开、循环分割和循环合并等技术来提高循环的执行效率。
- 常量传播:将编译时已知的常量值传播到代码中,减少运行时的计算开销。
- 强度削减:将高开销的操作(如乘法、除法)替换为低开销的操作(如加法、移位)。
改善内存使用
- 寄存器分配:优化器会尽量将变量分配到寄存器中,以减少内存访问的次数,提高程序运行速度。
- 内存访问优化:通过优化内存访问模式(如缓存友好的数据布局),减少缓存未命中次数,提高内存访问效率。
平衡优化
- 空间与时间的权衡:优化器需要在代码体积和执行效率之间找到平衡。例如,内联展开可能会增加代码体积,但可以减少函数调用的开销,提高执行效率。
- 不同优化级别:编译器通常提供不同的优化级别(如 -O1、-O2、-O3、-Os),开发者可以根据需求选择适合的优化级别。-Os 专注于减少代码体积,而 -O3 专注于提高执行效率。
平台特定优化
- 目标架构优化:优化器可以根据目标硬件平台的特性进行特定的优化,例如利用特定 CPU 指令集、优化缓存使用等。
- 特定应用场景优化:针对特定应用场景进行优化,例如嵌入式系统中的低功耗优化、实时系统中的实时性优化等。
在 Xcode 中可以设置优化级别: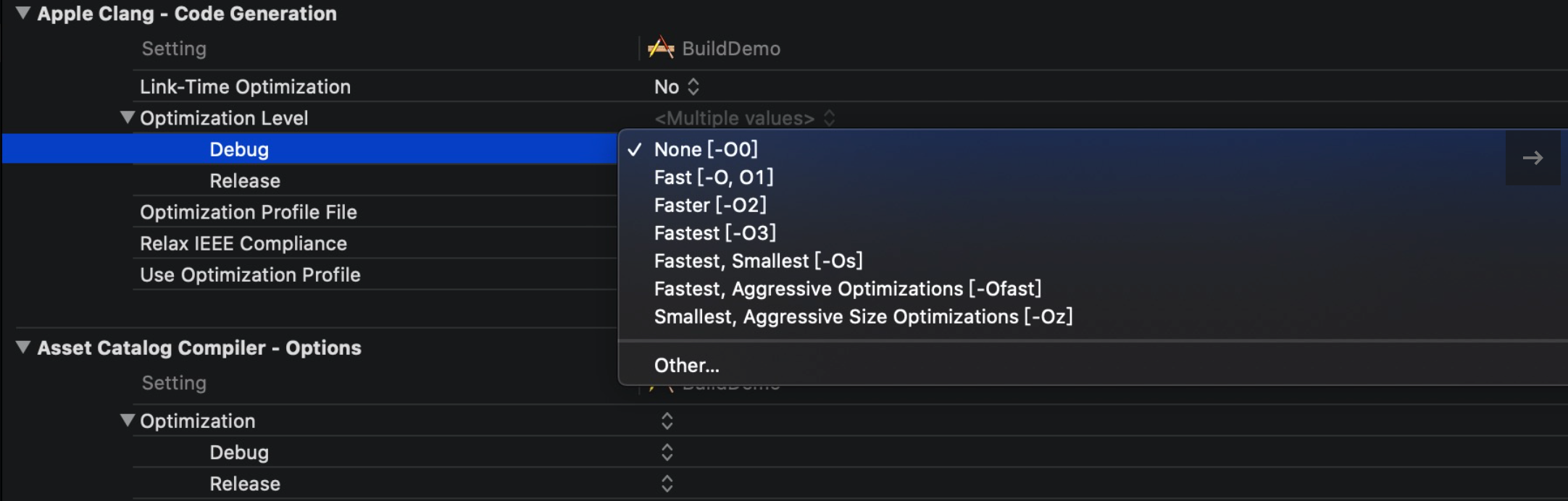
- -O0
- 无优化:这是默认的优化级别,编译器不会进行任何优化。主要用于调试,因为它保留了源代码和生成代码之间的一一对应关系,便于调试和错误定位。
- -O1
- 基本优化:应用一些基本的优化策略,旨在提高代码的执行效率而不会显著增加编译时间。例如,常量传播、死代码消除和简单的循环优化等。
- -O2
- 标准优化:应用更多的优化策略,进一步提高代码的执行效率。除了 -O1 中的优化,还包括更多的循环优化、内联展开、寄存器分配等。
- -O3
- 高级优化:应用最激进的优化策略,旨在最大化代码的执行效率。除了 -O2 中的优化,还包括更复杂的优化技术,如自动矢量化、函数内联和更高级的循环优化。这可能会显著增加编译时间和生成代码的体积。
- -Os
- 优化代码体积:专注于减少生成代码的体积,同时尽可能保持较高的执行效率。适用于对代码体积有严格要求的应用,如嵌入式系统。
- -Oz
- 极限优化代码体积:进一步减少代码体积,甚至可能牺牲一些执行性能。适用于对代码体积有极端要求的场景。
(3)编译器后端(LLVM)
目标代码生成
- LLVM 对 IR 进行优化后,会针对不同架构生成不同的目标代码,最后以汇编代码的格式输出。
汇编
- 汇编器以汇编代码作为输入,将汇编代码转换为机器代码,最后输出目标文件(object file)。该阶段会创建 .o 格式的目标文件。
链接
- 链接器将多个 .o 文件和库文件(如 .dylib、.a、.tbd)链接在一起,生成最终的可执行文件(Mach-O 文件)。
- 链接过程包括静态链接和动态链接:
- 静态链接:在编译链接期间,将目标文件和静态库一起链接形成可执行文件。
- 动态链接:链接过程推迟到运行时进行,将动态库链接到可执行文件中。
-

- 本文章采用 知识共享署名 4.0 国际许可协议 进行许可,完整转载、部分转载、图片转载时均请注明原文链接。