一、概述
dispatch_async 是用于将任务异步提交到指定调度队列的函数。它允许调用者线程继续执行,而不必等待任务的完成。
dispatch_async 特点:
- 会开启新线程
dispatch_async 提交的任务不会阻塞调用者线程。调用者线程可以继续执行后续代码,而任务会被异步地添加到队列中。- 无论将任务提交到并发队列还是串行队列,都会开启新线程。
- 主队列除外,提交到主队列的任务,会在主线程执行。
- 串行队列在有任务需要执行时,只会开启一个线程去执行任务。
- 任务顺序
- 串行队列
- 在串行队列上,
dispatch_async 提交的任务会按照提交的顺序依次执行,确保任务之间的顺序性。
- 并发队列
- 在并发队列上,
dispatch_async 提交的任务可以并行执行,具体执行顺序取决于系统的线程调度。
使用示例:
1
2
3
4
5
6
7
8
| dispatch_queue_t queue = dispatch_queue_create("com.lixkit.concurrentQueue", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
});
dispatch_async(queue, ^{
});
|
二、dispatch_async
dispatch_async 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| void
dispatch_async(dispatch_queue_t dq, dispatch_block_t work)
{
dispatch_continuation_t dc = _dispatch_continuation_alloc();
uintptr_t dc_flags = DC_FLAG_CONSUME;
dispatch_qos_t qos;
qos = _dispatch_continuation_init(dc, dq, work, 0, dc_flags);
_dispatch_continuation_async(dq, dc, qos, dc->dc_flags);
}
|
上述主要逻辑如下:
- 获取
continuation 对象
_dispatch_continuation_alloc
- 初始化
continuation 对象(为 continuation 中各成员赋值)
_dispatch_continuation_init
- 提交
continuation 到指定的队列
_dispatch_continuation_async
接下来,基于源码分别看下这几部分逻辑。
三、 _dispatch_continuation_alloc
_dispatch_continuation_alloc 函数用于获取 continuation 对象,continuation 对象是对任务的包装,其中存储了任务、优先级、上下文等信息。
continuation 是 dispatch_continuation_t 类型,dispatch_continuation_t 是一个指向 dispatch_continuation_s 结构体的指针,dispatch_continuation_s 的定义如下:
1
2
3
| typedef struct dispatch_continuation_s {
DISPATCH_CONTINUATION_HEADER(continuation);
} *dispatch_continuation_t;
|
将其涉及的宏完全展开后,结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| typedef struct dispatch_continuation_s {
union {
const void *__ptrauth_objc_isa_pointer do_vtable;
uintptr_t dc_flags;
};
union {
pthread_priority_t dc_priority;
int dc_cache_cnt;
uintptr_t dc_pad;
};
struct dispatch_continuation_s *volatile do_next;
struct voucher_s *dc_voucher;
dispatch_function_t dc_func;
void *dc_ctxt;
void *dc_data;
void *dc_other;
} *dispatch_continuation_t;
|
从 dispatch_continuation_s 结构可以看出,dispatch_continuation_s 是一个链表结构,其中的 do_next 则是指向下一个 continuation。
_dispatch_continuation_alloc 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| static inline dispatch_continuation_t
_dispatch_continuation_alloc(void)
{
dispatch_continuation_t dc =
_dispatch_continuation_alloc_cacheonly();
if (unlikely(!dc)) {
return _dispatch_continuation_alloc_from_heap();
}
return dc;
}
|
该函数主要逻辑为先从缓存中读取 continuation 对象,如果缓存不存在,再去新建一个 continuation 对象。
这里重点看下 continuation 缓存读取的逻辑,根据上述源码可知,缓存的读取是调用 _dispatch_continuation_alloc_cacheonly 函数获取的,该函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| static inline dispatch_continuation_t
_dispatch_continuation_alloc_cacheonly(void)
{
dispatch_continuation_t dc = (dispatch_continuation_t)
_dispatch_thread_getspecific(dispatch_cache_key);
if (likely(dc)) {
_dispatch_thread_setspecific(dispatch_cache_key, dc->do_next);
}
return dc;
}
|
前面提到 continuation 是一个链表结构,而其中 do_next 则是指向当前节点的下一个节点。
可以看到,上述主要逻辑是先从线程从当前线程存储空间中获取一个缓存的 continuation。如果取到,则将缓存更新为 continuation 的下个节点对象 do_next。
对于缓存不存在时新建的那个 continuation,也会在使用完释放时存入缓存:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| static inline void
_dispatch_continuation_free(dispatch_continuation_t dc)
{
dc = _dispatch_continuation_free_cacheonly(dc);
}
static inline dispatch_continuation_t
_dispatch_continuation_free_cacheonly(dispatch_continuation_t dc)
{
_dispatch_thread_setspecific(dispatch_cache_key, dc);
return NULL;
}
|
_dispatch_continuation_alloc 函数主要逻辑如下:
- 从当前线程存储空间中获取一个缓存的
continuation 对象 dc。
- 如果读取成功,则将当前线程缓存的
continuation 对象设置为 dc 的下一个对象(dc->do_next)。
- 如果缓存没有读取到,则创建新的
continuation。
- 这个新建的
continuation 在使用完成后,设置成线程缓存的 continuation。
结合上述源码可以知道,每个线程都利用 continuation 链表实现了一个 continuation 缓存池,continuation 不再使用后将会放入缓存池待下次使用,这么设计有下面两个好处:
- 通过重用这些对象,可以减少频繁创建和销毁对象的开销,提高性能。
- 每个线程维护自己的缓存,可以减少多线程同时分配内存时的锁竞争。
四、_dispatch_continuation_init
_dispatch_continuation_init 函数用于初始化 continuation 对象,该函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| static inline dispatch_qos_t
_dispatch_continuation_init(dispatch_continuation_t dc,
dispatch_queue_class_t dqu, dispatch_block_t work,
dispatch_block_flags_t flags, uintptr_t dc_flags)
{
void *ctxt = _dispatch_Block_copy(work);
dc_flags |= DC_FLAG_BLOCK | DC_FLAG_ALLOCATED;
if (unlikely(_dispatch_block_has_private_data(work))) {
dc->dc_flags = dc_flags;
dc->dc_ctxt = ctxt;
return _dispatch_continuation_init_slow(dc, dqu, flags);
}
dispatch_function_t func = _dispatch_Block_invoke(work);
if (dc_flags & DC_FLAG_CONSUME) {
func = _dispatch_call_block_and_release;
}
return _dispatch_continuation_init_f(dc, dqu, ctxt, func, flags, dc_flags);
}
|
上述逻辑,会先调用 _dispatch_block_has_private_data 函数检查 block 是否包含私有数据,关于 _dispatch_block_has_private_data 函数,《GCD 底层原理 3 - dispatch_sync》 中有解释,我们常规使用传入的 block 是不包含私有数据的。所以最终会执行 _dispatch_continuation_init_f 函数。
_dispatch_continuation_init_f 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| static inline dispatch_qos_t
_dispatch_continuation_init_f(dispatch_continuation_t dc,
dispatch_queue_class_t dqu, void *ctxt, dispatch_function_t f,
dispatch_block_flags_t flags, uintptr_t dc_flags)
{
pthread_priority_t pp = 0;
dc->dc_flags = dc_flags | DC_FLAG_ALLOCATED;
dc->dc_func = f;
dc->dc_ctxt = ctxt;
if (!(flags & DISPATCH_BLOCK_HAS_PRIORITY)) {
pp = _dispatch_priority_propagate();
}
_dispatch_continuation_voucher_set(dc, flags);
return _dispatch_continuation_priority_set(dc, dqu, pp, flags);
}
|
可以看出,该函数主要是为 continuation 各成员进行赋值,例如 dc_flags、dc_func、dc_voucher、dc_priority 等。
该函数中涉及到对 _dispatch_priority_propagate、_dispatch_continuation_voucher_set、_dispatch_continuation_priority_set 的函数调用,接下来分别分析下三个函数的实现逻辑。
1、_dispatch_priority_propagate
先看下 _dispatch_continuation_init_f 函数源码中优先级 pp 的赋值,从源码可知调用该函数时,传入的 flags 参数值是 0,所以最终会调用 _dispatch_priority_propagate 函数,该函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| static inline pthread_priority_t
_dispatch_priority_propagate(void)
{
return _dispatch_priority_compute_propagated(0,
DISPATCH_PRIORITY_PROPAGATE_CURRENT);
}
static inline pthread_priority_t
_dispatch_priority_compute_propagated(pthread_priority_t pp,
unsigned int flags)
{
if (flags & DISPATCH_PRIORITY_PROPAGATE_CURRENT) {
pp = _dispatch_get_priority();
}
pp = _pthread_priority_strip_all_flags(pp);
if (!(flags & DISPATCH_PRIORITY_PROPAGATE_FOR_SYNC_IPC) &&
pp > _dispatch_qos_to_pp(DISPATCH_QOS_USER_INITIATED)) {
return _dispatch_qos_to_pp(DISPATCH_QOS_USER_INITIATED);
}
return pp;
}
static inline pthread_priority_t
_dispatch_get_priority(void)
{
pthread_priority_t pp = (uintptr_t)
_dispatch_thread_getspecific(dispatch_priority_key);
return pp;
}
|
结合函数调用时的参数值,总结上述主要逻辑如下:
- 从当前线程存储空间中获取当前线程优先级,并赋值给
pp。
- 移除优先级中的所有标志位,只保留纯粹的优先级值。
- 如果优先级高于
USER_INITIATED 级别,则限制为 USER_INITIATED。
这里的优先级 pp 是 pthread_priority_t 类型,它和 Qos 什么关系呢?
pthread_priority_t 和 QoS (Quality of Service) 有密切的关系。在 GCD 中,它们用于表示任务的优先级和服务质量。它们之间的关系如下:
pthread_priority_t 是一个更底层的表示,它包含了 QoS 信息以及其他一些标志位。QoS 是一个更高级的抽象,它定义了几个离散的优先级级别,如 USER_INTERACTIVE、USER_INITIATED、UTILITY 等。pthread_priority_t 可以通过位操作来包含 QoS 信息。通常,QoS 值被编码在 pthread_priority_t 的高位字节中。- 可以使用一些宏或函数在
pthread_priority_t 和 QoS 之间进行转换,例如:1
2
3
4
|
dispatch_qos_t qos = _dispatch_qos_from_pp(pthread_priority);
pthread_priority_t pp = _dispatch_qos_to_pp(qos);
|
pthread_priority_t 除了包含 QoS 信息外,还可以包含其他标志,如相对优先级、覆盖标志等。- 在实际使用中,通常会使用
QoS 级别来设置任务优先级,而系统内部会将其转换为 pthread_priority_t 来进行更细粒度的调度控制。
可以通过一个简单示例,打印下默认 Qos:
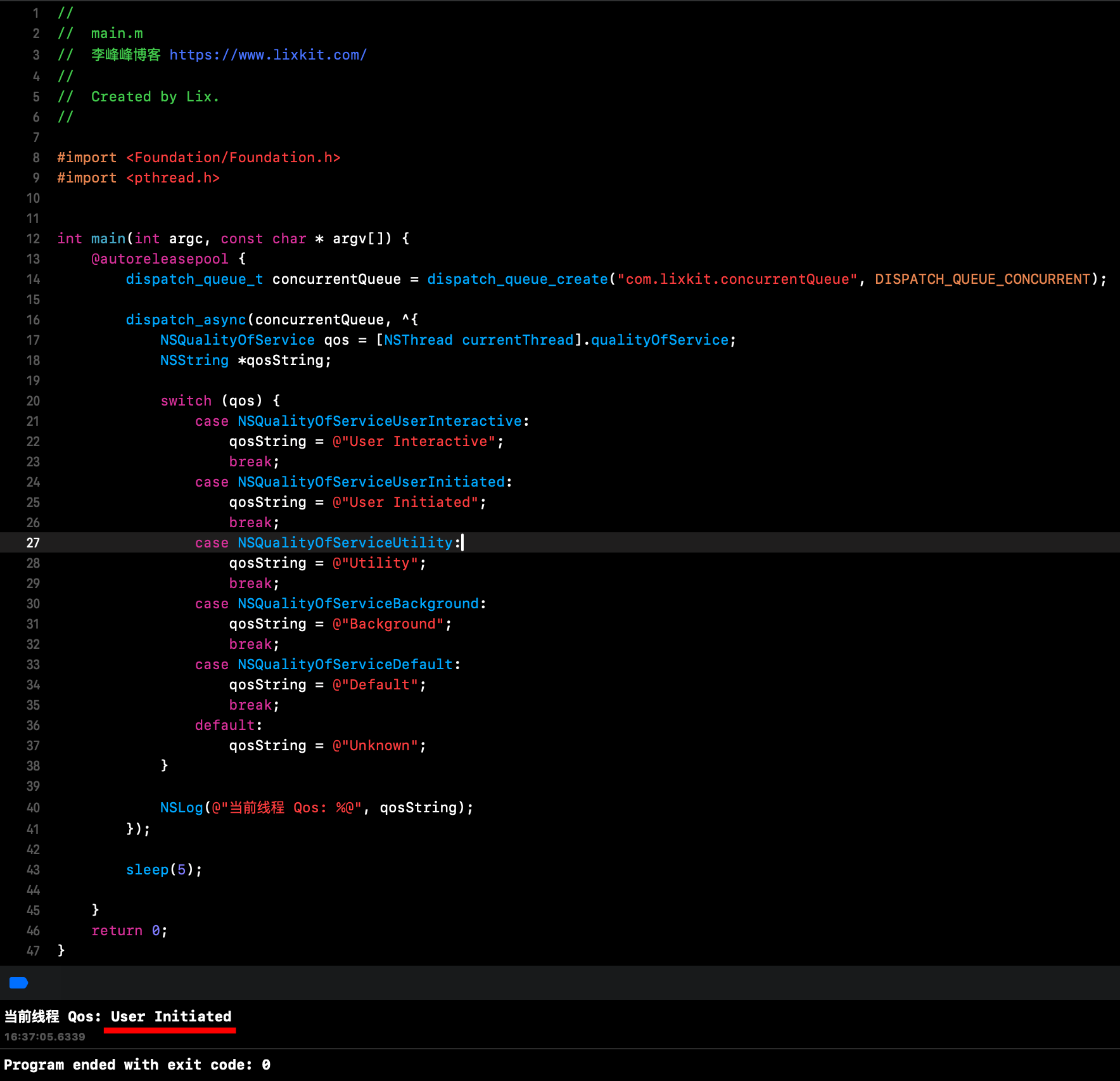
可以看到,默认 Qos 是 USER_INITIATED。
2、_dispatch_continuation_voucher_set
_dispatch_continuation_init_f 函数中,会调用 _dispatch_continuation_voucher_set 函数为 continuation 的 dc_voucher 赋值,根据前述 dispatch_continuation_s 结构可知,dc_voucher 是 voucher_s 类型。
完全展开后的 voucher_s 结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| typedef struct voucher_s {
struct voucher_vtable_s *__ptrauth_objc_isa_pointer os_obj_isa;
int volatile os_obj_ref_cnt;
int volatile os_obj_xref_cnt;
struct voucher_hash_entry_s {
uintptr_t vhe_next;
uintptr_t vhe_prev_ptr;
} v_list;
mach_voucher_t v_kvoucher;
mach_voucher_t v_ipc_kvoucher;
voucher_t v_kvbase;
firehose_activity_id_t v_activity;
uint64_t v_activity_creator;
firehose_activity_id_t v_parent_activity;
unsigned int v_kv_has_importance:1;
#if VOUCHER_ENABLE_RECIPE_OBJECTS
size_t v_recipe_extra_offset;
mach_voucher_attr_recipe_size_t v_recipe_extra_size;
#endif
} voucher_s;
|
voucher_s 不是本次源码分析的重点,且涉及内容较多,不再逐个字段分析。
_dispatch_continuation_voucher_set 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| static inline void
_dispatch_continuation_voucher_set(dispatch_continuation_t dc,
dispatch_block_flags_t flags)
{
voucher_t v = NULL;
dispatch_assert(!(flags & DISPATCH_BLOCK_HAS_VOUCHER));
if (!(flags & DISPATCH_BLOCK_NO_VOUCHER)) {
v = _voucher_copy();
}
dc->dc_voucher = v;
_dispatch_voucher_debug("continuation[%p] set", dc->dc_voucher, dc);
_dispatch_voucher_ktrace_dc_push(dc);
}
|
其中,_voucher_copy 函数用于复制当前线程的 voucher,其相关实现逻辑如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
static inline voucher_t
_voucher_copy(void)
{
voucher_t voucher = _voucher_get();
if (voucher) _voucher_retain(voucher);
return voucher;
}
static inline voucher_t
_voucher_get(void)
{
return _dispatch_thread_getspecific(dispatch_voucher_key);
}
|
根据源码可知,上述核心逻辑为读取当前线程的 voucher,并赋值给 dc_voucher。
3、_dispatch_continuation_priority_set
该函数主要是为 continuation 的 dc_priority 赋值,并返回对应 QoS,函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| static inline dispatch_qos_t
_dispatch_continuation_priority_set(dispatch_continuation_t dc,
dispatch_queue_class_t dqu,
pthread_priority_t pp, dispatch_block_flags_t flags)
{
dispatch_qos_t qos = DISPATCH_QOS_UNSPECIFIED;
#if HAVE_PTHREAD_WORKQUEUE_QOS
dispatch_queue_t dq = dqu._dq;
if (likely(pp)) {
bool enforce = (flags & DISPATCH_BLOCK_ENFORCE_QOS_CLASS);
bool is_floor = (dq->dq_priority & DISPATCH_PRIORITY_FLAG_FLOOR);
bool dq_has_qos = (dq->dq_priority & DISPATCH_PRIORITY_REQUESTED_MASK);
if (enforce) {
pp |= _PTHREAD_PRIORITY_ENFORCE_FLAG;
qos = _dispatch_qos_from_pp_unsafe(pp);
} else if (!is_floor && dq_has_qos) {
pp = 0;
} else {
qos = _dispatch_qos_from_pp_unsafe(pp);
}
}
dc->dc_priority = pp;
#else
(void)dc; (void)dqu; (void)pp; (void)flags;
#endif
return qos;
}
|
五、_dispatch_continuation_async
在前面完成 continuation 的初始化之后,将会调用 _dispatch_continuation_async 函数将初始化好的 continuation 异步提交到指定的队列。
_dispatch_continuation_async 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| static inline void
_dispatch_continuation_async(dispatch_queue_class_t dqu,
dispatch_continuation_t dc, dispatch_qos_t qos, uintptr_t dc_flags)
{
#if DISPATCH_INTROSPECTION
if (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {
_dispatch_trace_item_push(dqu, dc);
}
#else
(void)dc_flags;
#endif
return dx_push(dqu._dq, dc, qos);
}
|
上述实现中,重点是对 dx_push 这个宏的调用,其他的都是日志、调试相关。
dx_push 宏定义如下:
1
| #define dx_push(x, y, z) dx_vtable(x)->dq_push(x, y, z)
|
可以知道,这里是访问队列虚表的 dq_push 函数进行调用。结合在另篇文章《GCD 底层原理 2 - dispatch_queue》 中的内容可知,串行队列、并发队列的虚表如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
const struct dispatch_lane_vtable_s _dispatch_queue_serial_vtable = {
._os_obj_xref_dispose = _dispatch_xref_dispose,
._os_obj_dispose = _dispatch_dispose,
._os_obj_vtable = {
.do_kind = "queue_serial",
.do_type = DISPATCH_QUEUE_SERIAL_TYPE,
.do_dispose = _dispatch_lane_dispose,
.do_debug = _dispatch_queue_debug,
.do_invoke = _dispatch_lane_invoke,
.dq_activate = _dispatch_lane_activate,
.dq_wakeup = _dispatch_lane_wakeup,
.dq_push = _dispatch_lane_push,
},
};
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
const struct dispatch_lane_vtable_s _dispatch_queue_concurrent_vtable = {
._os_obj_xref_dispose = _dispatch_xref_dispose,
._os_obj_dispose = _dispatch_dispose,
._os_obj_vtable = {
.do_kind = "queue_concurrent",
.do_type = DISPATCH_QUEUE_CONCURRENT_TYPE,
.do_dispose = _dispatch_lane_dispose,
.do_debug = _dispatch_queue_debug,
.do_invoke = _dispatch_lane_invoke,
.dq_activate = _dispatch_lane_activate,
.dq_wakeup = _dispatch_lane_wakeup,
.dq_push = _dispatch_lane_concurrent_push,
},
}
|
所以,前面对 dx_push 的调用:
- 串行队列调用的是
_dispatch_lane_push 函数。
- 并发队列调用的是
_dispatch_lane_concurrent_push 函数。
接下来,分别看下将任务提交到串行队列、并发队列的逻辑。
1、提交到串行队列
(1)_dispatch_lane_push
dispatch_async 将任务提交到串行队列时,调用 dx_push 实际调用的是 _dispatch_lane_push 函数,该函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
| void
_dispatch_lane_push(dispatch_lane_t dq, dispatch_object_t dou,
dispatch_qos_t qos)
{
dispatch_wakeup_flags_t flags = 0;
struct dispatch_object_s *prev;
if (unlikely(_dispatch_object_is_waiter(dou))) {
return _dispatch_lane_push_waiter(dq, dou._dsc, qos);
}
dispatch_assert(!_dispatch_object_is_global(dq));
qos = _dispatch_queue_push_qos(dq, qos);
prev = os_mpsc_push_update_tail(os_mpsc(dq, dq_items), dou._do, do_next);
if (unlikely(os_mpsc_push_was_empty(prev))) {
_dispatch_retain_2_unsafe(dq);
flags = DISPATCH_WAKEUP_CONSUME_2 | DISPATCH_WAKEUP_MAKE_DIRTY;
} else if (unlikely(_dispatch_queue_need_override(dq, qos))) {
_dispatch_retain_2_unsafe(dq);
flags = DISPATCH_WAKEUP_CONSUME_2;
}
os_mpsc_push_update_prev(os_mpsc(dq, dq_items), prev, dou._do, do_next);
if (flags) {
return dx_wakeup(dq, qos, flags);
}
}
|
该函数的参数 dq 是 dispatch_lane_t 类型,在另篇文章《GCD 底层原理 2 - dispatch_queue》 中分析了 dispatch_lane_t 结构:
1
2
3
4
5
6
7
8
9
| struct dispatch_lane_s {
struct dispatch_object_s *dq_items_head;
struct dispatch_object_s *dq_items_tail;
dispatch_unfair_lock_s dq_sidelock;
};
|
其中,将源码中的:
1
| prev = os_mpsc_push_update_tail(os_mpsc(dq, dq_items), dou._do, do_next);
|
宏完全展开后,源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| prev = ({
__typeof__(__c11_atomic_load((__typeof__(*(&(dq)->dq_items_head)) _Atomic *)(&(dq)->dq_items_head), memory_order_relaxed)) _tl = (dou._do);
__c11_atomic_store((__typeof__((*(_tl)).do_next) _Atomic *)(&(_tl)->do_next), NULL, memory_order_relaxed);
_dispatch_thread_setspecific(dispatch_enqueue_key, (void *) (&(dq)->dq_items_tail));
atomic_exchange_explicit((__typeof__(*(&(dq)->dq_items_tail)) _Atomic *)(&(dq)->dq_items_tail), _tl, memory_order_release);
})
|
可以看出,这部分逻辑将任务作为节点添加到队列的尾部,并将 dq_items_tail 指向这个新节点(continuation),prev 为之前的尾部指针,可以理解为上一个节点。
将源码中的:
1
| os_mpsc_push_update_prev(os_mpsc(dq, dq_items), prev, dou._do, do_next);
|
宏完全展开后,源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| ({
__typeof__(atomic_load_explicit(_os_atomic_c11_atomic(&(dq)->dq_items_head), memory_order_relaxed)) _prev = (prev);
if (likely(_prev)) {
(void)atomic_store_explicit(_os_atomic_c11_atomic(&(_prev)->do_next), dou._do, memory_order_relaxed);
} else {
(void)atomic_store_explicit(_os_atomic_c11_atomic(&(dq)->dq_items_head), dou._do, memory_order_relaxed);
}
_dispatch_clear_enqueuer();
})
|
这部分逻辑是将上一步返回的 prev 的 do_next 指向当前任务节点。
这里入队的操作,为什么分成两部分去做呢?
从入队宏命名上,也可以看出这是 MPSC 队列,MPSC 是 “Multiple Producer, Single Consumer” 的缩写,表示多生产者单消费者队列。这是一种并发数据结构,允许多个生产者线程向队列中添加数据,而只有一个消费者线程从队列中提取数据。
MPSC 队列的特性:
- 多生产者
- 多个生产者线程可以同时向队列中添加数据。这需要在并发环境下确保数据的一致性和正确性。
- 单消费者
- 只有一个消费者线程从队列中提取数据。这简化了消费者端的同步问题,因为不需要处理多个消费者之间的竞争。
os_mpsc_push_update_tail 和 os_mpsc_push_update_prev 是配合使用的,它们共同完成了将新节点添加到多生产者单消费者(MPSC)队列的操作。这两个宏的作用:
os_mpsc_push_update_tail
- 这个函数主要负责更新队列的尾指针。
- 它将新节点添加到队列的末尾,并返回之前的尾节点。
- 但是,它并不会更新之前尾节点的
do_next 指针。
os_mpsc_push_update_prev
- 这个函数负责更新前一个节点(之前的尾节点)的
do_next 指针,使其指向新节点。
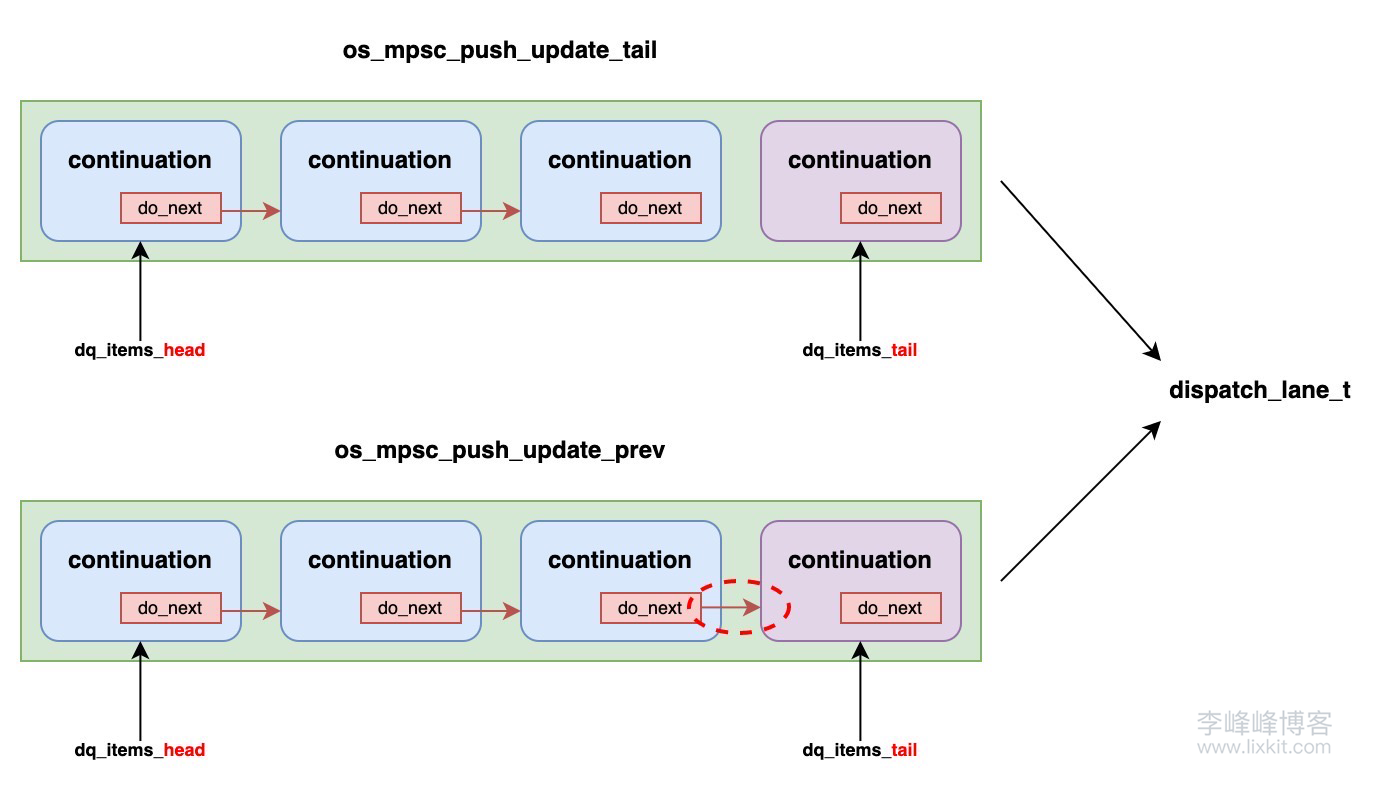
将一个复杂的原子操作(同时更新尾指针和前一个节点的 do_next 指针)分解为两个简单的原子操作。简单的原子操作通常比复杂的原子操作更高效,尤其是在高并发情况下。
从这里也可以看出,管理任务的队列 dispatch_lane_t,是使用单向链表实现的。
总结 _dispatch_lane_push 函数核心逻辑:
- 将任务作为节点添加到队列的尾部,并将
dq_items_tail 指向这个新节点(continuation),并返回 prev(之前的尾部节点)。
- 其他关键参数配置。
prev 的 do_next 指向当前任务节点。- 调用
dx_wakeup 唤醒队列。
其中,dx_wakeup 宏定义如下:
1
| #define dx_wakeup(x, y, z) dx_vtable(x)->dq_wakeup(x, y, z)
|
所以对于串行队列,这里实际调用的是 _dispatch_lane_wakeup 函数
(2)_dispatch_lane_wakeup
_dispatch_lane_wakeup 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
| void
_dispatch_queue_wakeup(dispatch_queue_class_t dqu, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags, dispatch_queue_wakeup_target_t target)
{
dispatch_queue_t dq = dqu._dq;
uint64_t old_state, new_state, enqueue = DISPATCH_QUEUE_ENQUEUED;
dispatch_assert(target != DISPATCH_QUEUE_WAKEUP_WAIT_FOR_EVENT);
if (target && !(flags & DISPATCH_WAKEUP_CONSUME_2)) {
_dispatch_retain_2(dq);
flags |= DISPATCH_WAKEUP_CONSUME_2;
}
if (unlikely(flags & DISPATCH_WAKEUP_BARRIER_COMPLETE)) {
dispatch_assert(dx_metatype(dq) == _DISPATCH_SOURCE_TYPE);
qos = _dispatch_queue_wakeup_qos(dq, qos);
return _dispatch_lane_class_barrier_complete(upcast(dq)._dl, qos,
flags, target, DISPATCH_QUEUE_SERIAL_DRAIN_OWNED);
}
if (target) {
if (target == DISPATCH_QUEUE_WAKEUP_MGR) {
enqueue = DISPATCH_QUEUE_ENQUEUED_ON_MGR;
}
qos = _dispatch_queue_wakeup_qos(dq, qos);
os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, release, {
new_state = _dq_state_merge_qos(old_state, qos);
if (flags & DISPATCH_WAKEUP_CLEAR_ACTIVATING) {
if (_dq_state_is_activating(old_state)) {
new_state &= ~DISPATCH_QUEUE_ACTIVATING;
}
}
if (likely(!_dq_state_is_suspended(new_state) &&
!_dq_state_is_enqueued(old_state) &&
(!_dq_state_drain_locked(old_state) ||
enqueue != DISPATCH_QUEUE_ENQUEUED_ON_MGR))) {
new_state |= enqueue;
}
if (flags & DISPATCH_WAKEUP_MAKE_DIRTY) {
new_state |= DISPATCH_QUEUE_DIRTY;
} else if (new_state == old_state) {
os_atomic_rmw_loop_give_up(goto done);
}
});
#if HAVE_PTHREAD_WORKQUEUE_QOS
} else if (qos) {
os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, relaxed, {
if (!_dq_state_drain_locked(old_state) &&
!_dq_state_is_enqueued(old_state)) {
os_atomic_rmw_loop_give_up(goto done);
}
new_state = _dq_state_merge_qos(old_state, qos);
if (_dq_state_is_base_wlh(old_state) &&
!_dq_state_is_suspended(old_state) &&
!_dq_state_is_enqueued_on_manager(old_state)) {
new_state |= enqueue;
}
if (new_state == old_state) {
os_atomic_rmw_loop_give_up(goto done);
}
});
target = DISPATCH_QUEUE_WAKEUP_TARGET;
#endif
} else {
goto done;
}
if (likely((old_state ^ new_state) & enqueue)) {
dispatch_queue_t tq;
if (target == DISPATCH_QUEUE_WAKEUP_TARGET) {
os_atomic_thread_fence(dependency);
tq = os_atomic_load_with_dependency_on2o(dq, do_targetq,
(long)new_state);
} else {
tq = target;
}
dispatch_assert(_dq_state_is_enqueued(new_state));
return _dispatch_queue_push_queue(tq, dq, new_state);
}
#if HAVE_PTHREAD_WORKQUEUE_QOS
if (unlikely((old_state ^ new_state) & DISPATCH_QUEUE_MAX_QOS_MASK)) {
if (_dq_state_should_override(new_state)) {
return _dispatch_queue_wakeup_with_override(dq, new_state,
flags);
}
}
#endif
done:
if (likely(flags & DISPATCH_WAKEUP_CONSUME_2)) {
return _dispatch_release_2_tailcall(dq);
}
}
|
将上述代码进行精简,最终会走该函数走进 _dispatch_queue_push_queue 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| void
_dispatch_queue_wakeup(dispatch_queue_class_t dqu, dispatch_qos_t qos,
dispatch_wakeup_flags_t flags, dispatch_queue_wakeup_target_t target)
{
uint64_t old_state, new_state, enqueue = DISPATCH_QUEUE_ENQUEUED;
if (target) {
new_state |= enqueue;
}
if (likely((old_state ^ new_state) & enqueue)) {
return _dispatch_queue_push_queue(tq, dq, new_state);
}
}
|
_dispatch_queue_push_queue 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| static inline void
_dispatch_queue_push_queue(dispatch_queue_t tq, dispatch_queue_class_t dq,
uint64_t dq_state, dispatch_wakeup_flags_t flags)
{
dispatch_assert(flags & DISPATCH_EVENT_LOOP_CONSUME_2);
#if DISPATCH_USE_KEVENT_WORKLOOP
if (likely(_dq_state_is_base_wlh(dq_state))) {
_dispatch_trace_runtime_event(worker_request, dq._dq, 1);
return _dispatch_event_loop_poke((dispatch_wlh_t)dq._dq, dq_state,DISPATCH_EVENT_LOOP_CONSUME_2);
}
#endif
_dispatch_trace_item_push(tq, dq);
return dx_push(tq, dq,_dq_state_max_qos(dq_state));
}
|
根据在另篇文章《GCD 底层原理 2 - dispatch_queue》 提到的串行队列 dq_state 为:
1
| dq_state = (DISPATCH_QUEUE_STATE_INIT_VALUE(dq_width) | DISPATCH_QUEUE_ROLE_BASE_WLH)
|
所以这里会调用 _dispatch_event_loop_poke 函数,该函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| void
_dispatch_event_loop_poke(dispatch_wlh_t wlh, uint64_t dq_state, uint32_t flags)
{
if (wlh == DISPATCH_WLH_MANAGER) {
dispatch_kevent_s ke = (dispatch_kevent_s){
.ident = 1,
.filter = EVFILT_USER,
.fflags = NOTE_TRIGGER,
.udata = (dispatch_kevent_udata_t)DISPATCH_WLH_MANAGER,
};
return _dispatch_kq_deferred_update(DISPATCH_WLH_ANON, &ke);
} else if (wlh && wlh != DISPATCH_WLH_ANON) {
#if DISPATCH_USE_KEVENT_WORKLOOP
dispatch_queue_t dq = (dispatch_queue_t)wlh;
dispatch_assert(_dq_state_is_base_wlh(dq_state));
if(unlikely(_dq_state_is_enqueued_on_manager(dq_state))) {
dispatch_assert(!(flags & DISPATCH_EVENT_LOOP_OVERRIDE));
dispatch_assert(flags & DISPATCH_EVENT_LOOP_CONSUME_2);
_dispatch_trace_item_push(&_dispatch_mgr_q, dq);
return dx_push(_dispatch_mgr_q._as_dq, dq, 0);
}
dispatch_deferred_items_t ddi = _dispatch_deferred_items_get();
if (ddi && ddi->ddi_wlh == wlh) {
return _dispatch_kevent_workloop_poke_self(ddi, dq_state, flags);
}
return _dispatch_kevent_workloop_poke(wlh, dq_state, flags);
#else
(void)dq_state; (void)flags;
#endif
}
DISPATCH_INTERNAL_CRASH(wlh, "Unsupported wlh configuration");
}
|
根据函数中判断条件可知,这里会执行 _dispatch_kevent_workloop_poke 函数。
_dispatch_kevent_workloop_poke 这个函数名中,有一个 workloop,这个 workloop 是什么呢?
接下来先看下什么是 Workqueue 与 Workloop。
(3)Workqueue 与 Workloop
GCD 通过 Workqueue 和 Workloop 两种机制实现了灵活的任务管理。
Workqueue
Workqueue 是 XNU 内核提供的基于线程池的任务调度机制,旨在高效地管理并发任务。它是 GCD 的底层实现之一,能够动态调整线程池的大小以适应当前的任务负载。
Workqueue 特点:
- 线程池管理
Workqueue 使用线程池来执行任务,线程可以被多个任务复用,从而减少线程创建和销毁的开销。
- 并发任务调度
- 适合处理大量并发任务,任务之间没有严格的顺序要求。
- 动态扩展
- 根据任务的数量和优先级,
Workqueue 可以动态增加或减少线程池中的线程。
其中,线程池的管理是通过 pthread_workqueue 相关接口与内核进行交互的,pthread_workqueue 是 pthread 的扩展,专门用于高效的任务调度和线程管理。GCD 通过调用 pthread_workqueue 接口,将任务分发到内核的 Workqueue,内核的 Workqueue 接收到任务后,会从线程池中分配线程来执行任务。

Workqueue 在 GCD 中一个很重要的应用场景就是并发队列的异步派发,关于这一点后续内容会分析。
Workloop
Workloop 是基于 Workqueue 构建的更高级抽象。Workqueue 提供了线程池和并发任务调度的基础设施,而 Workloop 在此基础上增加了任务顺序性和事件驱动支持,专注于管理任务的顺序性和事件驱动,能够更好地支持串行任务和基于事件的任务调度。
任务被提交到串行队列后,GCD 会将任务分配到 Workloop,Workloop 会按照任务的提交顺序依次执行任务。
简单总结一下:
Workqueue
- 基于线程池的任务调度机制,适合处理并发任务。
- 通过动态调整线程池的大小和优先级,最大化利用系统资源。
- 主要用于 GCD 的并发队列。
Workloop
- 基于事件驱动的任务调度机制,专注于任务的顺序性和上下文切换。
- 支持事件监听和优先级调度,适合处理串行任务和事件驱动任务。
- 主要用于 GCD 的串行队列。
(4)_dispatch_kevent_workloop_poke
该函数源码实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| static void
_dispatch_kevent_workloop_poke(dispatch_wlh_t wlh, uint64_t dq_state,
uint32_t flags)
{
uint32_t kev_flags = KEVENT_FLAG_IMMEDIATE | KEVENT_FLAG_ERROR_EVENTS;
dispatch_kevent_s ke;
int action;
dispatch_assert(_dq_state_is_enqueued_on_target(dq_state));
dispatch_assert(!_dq_state_is_enqueued_on_manager(dq_state));
action = _dispatch_event_loop_get_action_for_state(dq_state);
_dispatch_kq_fill_workloop_event(&ke, action, wlh, dq_state);
if (_dispatch_kq_poll(wlh, &ke, 1, &ke, 1, NULL, NULL, kev_flags)) {
_dispatch_kevent_workloop_drain_error(&ke, 0);
__builtin_unreachable();
}
if (!(flags & DISPATCH_EVENT_LOOP_OVERRIDE)) {
return _dispatch_release_tailcall((dispatch_queue_t)wlh);
}
if (flags & DISPATCH_EVENT_LOOP_CONSUME_2) {
return _dispatch_release_2_tailcall((dispatch_queue_t)wlh);
}
}
|
这里又看到了熟悉的 _dispatch_kq_poll 函数,在《GCD 底层原理 3 - dispatch_sync》 中也针对这个函数做过分析,有需要可以参考这篇文章里 _dispatch_kq_poll 相关内容。
该函数内部调用了 _dispatch_kq_fill_workloop_event,从这一点也可以看出串行队列是基于 Workloop 的。
_dispatch_kq_fill_workloop_event 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| static void
_dispatch_kq_fill_workloop_event(dispatch_kevent_t ke, int which,
dispatch_wlh_t wlh, uint64_t dq_state)
{
dispatch_queue_t dq = (dispatch_queue_t)wlh;
dispatch_qos_t qos = _dq_state_max_qos(dq_state);
pthread_priority_t pp = 0;
uint32_t fflags = 0;
uint64_t mask = 0;
uint16_t action = 0;
switch (which) {
case DISPATCH_WORKLOOP_ASYNC:
case DISPATCH_WORKLOOP_ASYNC_FROM_SYNC:
case DISPATCH_WORKLOOP_ASYNC_QOS_UPDATE:
dispatch_assert(_dq_state_is_base_wlh(dq_state));
dispatch_assert(_dq_state_is_enqueued_on_target(dq_state));
action = EV_ADD | EV_ENABLE;
mask |= DISPATCH_QUEUE_ROLE_MASK;
mask |= DISPATCH_QUEUE_ENQUEUED;
mask |= DISPATCH_QUEUE_MAX_QOS_MASK;
fflags |= NOTE_WL_IGNORE_ESTALE;
fflags |= NOTE_WL_UPDATE_QOS;
if (_dq_state_in_uncontended_sync(dq_state)) {
fflags |= NOTE_WL_DISCOVER_OWNER;
mask |= DISPATCH_QUEUE_UNCONTENDED_SYNC;
}
pp = _dispatch_kevent_workloop_priority(dq, which, qos);
break;
case DISPATCH_WORKLOOP_ASYNC_LEAVE_FROM_SYNC:
case DISPATCH_WORKLOOP_ASYNC_LEAVE_FROM_TRANSFER:
fflags |= NOTE_WL_IGNORE_ESTALE;
case DISPATCH_WORKLOOP_ASYNC_LEAVE:
dispatch_assert(!_dq_state_is_enqueued_on_target(dq_state));
action = EV_ADD | EV_DELETE | EV_ENABLE;
mask |= DISPATCH_QUEUE_ENQUEUED;
break;
case DISPATCH_WORKLOOP_RETARGET:
action = EV_ADD | EV_DELETE | EV_ENABLE;
fflags |= NOTE_WL_END_OWNERSHIP;
break;
default:
DISPATCH_INTERNAL_CRASH(which, "Invalid transition");
}
*ke = (dispatch_kevent_s){
.ident = (uintptr_t)wlh,
.filter = EVFILT_WORKLOOP,
.flags = action,
.fflags = fflags | NOTE_WL_THREAD_REQUEST,
.qos = (__typeof__(ke->qos))pp,
.udata = (uintptr_t)wlh,
.ext[EV_EXTIDX_WL_ADDR] = (uintptr_t)&dq->dq_state,
.ext[EV_EXTIDX_WL_MASK] = mask,
.ext[EV_EXTIDX_WL_VALUE] = dq_state,
};
_dispatch_kevent_wlh_debug(_dispatch_workloop_actions[which], ke);
}
|
该函数最终创建的 ke 中有个 NOTE_WL_THREAD_REQUEST 配置,该配置的作用是请求内核分配一个线程去处理当前任务。
再次进入 _dispatch_kq_poll 这个函数,其精简后的实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| static int
_dispatch_kq_poll(dispatch_wlh_t wlh, dispatch_kevent_t ke, int n,
dispatch_kevent_t ke_out, int n_out, void *buf, size_t *avail,
uint32_t flags)
{
dispatch_once_f(&_dispatch_kq_poll_pred, &kq_initialized, _dispatch_kq_init);
if (unlikely(wlh == NULL)) {
} else if (wlh == DISPATCH_WLH_ANON) {
} else {
r = kevent_id((uintptr_t)wlh, ke, n, ke_out, n_out, buf, avail, flags);
}
return r;
}
|
这部分主要逻辑如下:
- 初始化,会调用一次
_dispatch_kq_init。
- 进行
kevent_id 系统调用。
其中,_dispatch_kq_init 的执行逻辑中,会调用到 _dispatch_root_queues_init_once 函数,执行路径如下:
1
2
3
4
5
6
7
| _dispatch_kq_init
⬇️
_dispatch_kevent_workqueue_init
⬇️
_dispatch_root_queues_init
⬇️
_dispatch_root_queues_init_once
|
精简后的 _dispatch_root_queues_init_once 实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| static void
_dispatch_root_queues_init_once(void *context DISPATCH_UNUSED)
{
struct pthread_workqueue_config cfg = {
.version = PTHREAD_WORKQUEUE_CONFIG_VERSION,
.flags = 0,
.workq_cb = 0,
.kevent_cb = 0,
.workloop_cb = 0,
.queue_serialno_offs = dispatch_queue_offsets.dqo_serialnum,
.queue_label_offs = dispatch_queue_offsets.dqo_label,
};
if (unlikely(!_dispatch_kevent_workqueue_enabled)) {
} else if (wq_supported & WORKQ_FEATURE_WORKLOOP) {
cfg.workq_cb = _dispatch_worker_thread2;
cfg.kevent_cb = (pthread_workqueue_function_kevent_t) _dispatch_kevent_worker_thread;
cfg.workloop_cb = (pthread_workqueue_function_workloop_t) _dispatch_workloop_worker_thread;
r = pthread_workqueue_setup(&cfg, sizeof(cfg));
} else if (wq_supported & WORKQ_FEATURE_KEVENT) {
} else {
DISPATCH_INTERNAL_CRASH(wq_supported, "Missing Kevent WORKQ support");
}
}
|
上述关键逻辑如下:
- 配置
workqueue 回调函数
workq_cb = _dispatch_worker_thread2
- 配置
workloop 回调函数
workloop_cb = _dispatch_workloop_worker_thread
- 调用
pthread_workqueue_setup 进行上述配置
前面已经分析过,串行队列是基于 Workloop,最终会执行 workloop 回调函数 workloop_cb。
当前面 kevent_id 系统调用执行完成后,内核会进行线程的的创建和分配。之后将会从内核态切换到用户态的 start_wqthread 函数,start_wqthread 函数中,会继续调用 _pthread_wqthread 函数,_pthread_wqthread 负责管理线程生命周期,并从工作队列中提取任务交由上面配置回调函数执行。
由于串行队列是基于 Workloop 的,所以 _pthread_wqthread 会将任务交给 workloop 回调函数 workloop_cb 执行,即 _dispatch_workloop_worker_thread 函数。
_dispatch_workloop_worker_thread 函数中,会先调用 _dispatch_root_queue_drain_deferred_wlh 函数,再调用 _dispatch_lane_invoke 函数:
1
2
3
4
5
6
7
8
9
| start_wqthread
⬇️
_pthread_wqthread
⬇️
_dispatch_workloop_worker_thread
⬇️
_dispatch_root_queue_drain_deferred_wlh
⬇️
_dispatch_lane_invoke
|
相关调用堆栈如下:

(5)_dispatch_root_queue_drain_deferred_wlh
该函数精简后的逻辑如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| static void
_dispatch_root_queue_drain_deferred_wlh(dispatch_deferred_items_t ddi
DISPATCH_PERF_MON_ARGS_PROTO)
{
dispatch_queue_t dq = ...;
dispatch_invoke_context_s dic = ...;
dispatch_invoke_flags_t flags = DISPATCH_INVOKE_WORKER_DRAIN |
DISPATCH_INVOKE_REDIRECTING_DRAIN | DISPATCH_INVOKE_WLH;
if (_dispatch_queue_drain_try_lock_wlh(dq, &dq_state)) {
dx_invoke(dq, &dic, flags);
}
}
|
其中获取 drain 锁的的函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
| static inline bool
_dispatch_queue_drain_try_lock_wlh(dispatch_queue_t dq, uint64_t *dq_state)
{
uint64_t old_state, new_state;
uint64_t lock_bits = _dispatch_lock_value_for_self() | DISPATCH_QUEUE_WIDTH_FULL_BIT | DISPATCH_QUEUE_IN_BARRIER;
os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, acquire, {
new_state = old_state;
if (unlikely(_dq_state_is_suspended(old_state))) {
new_state &= ~DISPATCH_QUEUE_ENQUEUED;
}
else if (unlikely(_dq_state_drain_locked(old_state))) {
if (_dq_state_in_uncontended_sync(old_state)) {
new_state |= DISPATCH_QUEUE_RECEIVED_SYNC_WAIT;
} else {
os_atomic_rmw_loop_give_up(break);
}
}
else {
new_state &= DISPATCH_QUEUE_DRAIN_PRESERVED_BITS_MASK;
new_state |= lock_bits;
}
});
if (unlikely(!_dq_state_is_base_wlh(old_state) || !_dq_state_is_enqueued_on_target(old_state) || _dq_state_is_enqueued_on_manager(old_state))) {
#if DISPATCH_SIZEOF_PTR == 4
old_state >>= 32;
#endif
DISPATCH_INTERNAL_CRASH(old_state, "Invalid wlh state");
}
if (dq_state) *dq_state = new_state;
return !_dq_state_is_suspended(old_state) && !_dq_state_drain_locked(old_state);
}
|
上述获取 drain 锁的主要逻辑如下:
- 如果队列未被挂起,并且未被锁定,可以获取锁,返回值为
true。
- 此时会同时设置一系列标志位
lock_bits:
tid & DLOCK_OWNER_MASK
- 设置了该标志位后,
_dq_state_drain_locked 会返回 true
DISPATCH_QUEUE_WIDTH_FULL_BITDISPATCH_QUEUE_IN_BARRIER
- 如果队列被挂起,或者已被锁定,无法获取锁,返回值为
false。
其中,函数的返回值是队列是否未挂起且未被锁定,上面已经提到,是否被锁定,取决于是否设置了 tid & DLOCK_OWNER_MASK 标志位。在后续调用的 _dispatch_queue_drain_try_unlock 函数(后面分析会提到)中,会清除锁定标志位,使队列重新变成未锁定状态。
而当我们显示调用了 GCD 的 dispatch_suspend 时候,会使队列变成挂起状态。dispatch_suspend 不是本次分析的重点,所以在获取 drain 锁的逻辑里,我们只需要关注队列是否被锁定即可。
所以,_dispatch_root_queue_drain_deferred_wlh 函数核心逻辑是先尝试获取锁,如果获取成功,则调用 dx_invoke 开始执行任务。如果获取锁失败,代表当前串行队列中的任务正在其他线程被执行。
根据 dx_invoke 宏的定义:
1
| #define dx_invoke(x, y, z) dx_vtable(x)->do_invoke(x, y, z)
|
结合前面提到的串行队列虚表可知,这里实际是调用 _dispatch_lane_invoke 函数。
(6)_dispatch_lane_invoke
_dispatch_lane_invoke 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| void
_dispatch_lane_invoke(dispatch_lane_t dq, dispatch_invoke_context_t dic,
dispatch_invoke_flags_t flags)
{
_dispatch_queue_class_invoke(dq, dic, flags, 0, _dispatch_lane_invoke2);
}
static inline void
_dispatch_queue_class_invoke(dispatch_queue_class_t dqu,
dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags,
dispatch_invoke_flags_t const_restrict_flags,
_dispatch_queue_class_invoke_handler_t invoke)
{
if (likely(flags & DISPATCH_INVOKE_WLH)) {
owned = DISPATCH_QUEUE_SERIAL_DRAIN_OWNED | DISPATCH_QUEUE_ENQUEUED;
} else {
owned = _dispatch_queue_drain_try_lock(dq, flags);
}
if (likely(owned)) {
tq = invoke(dq, dic, flags, &owned);
if (unlikely(tq != DISPATCH_QUEUE_WAKEUP_NONE && tq != DISPATCH_QUEUE_WAKEUP_WAIT_FOR_EVENT)) {
} else if (!_dispatch_queue_drain_try_unlock(dq, owned, tq == DISPATCH_QUEUE_WAKEUP_NONE)) {
}
}
if (tq) {
return _dispatch_queue_invoke_finish(dq, dic, tq, owned);
}
return _dispatch_release_2_tailcall(dq);
}
|
上述主要逻辑如下:
- 调用
_dispatch_lane_invoke2 函数执行任务。
- 调用
_dispatch_queue_drain_try_unlock 解锁。
- 这里解锁后,会使下次调用
_dispatch_root_queue_drain_deferred_wlh 时可以成功获取到 drain 解锁。
接下来看下 _dispatch_lane_invoke2 函数的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| static inline dispatch_queue_wakeup_target_t
_dispatch_lane_invoke2(dispatch_lane_t dq, dispatch_invoke_context_t dic,
dispatch_invoke_flags_t flags, uint64_t *owned)
{
dispatch_queue_t otq = dq->do_targetq;
dispatch_queue_t cq = _dispatch_queue_get_current();
if (unlikely(cq != otq)) {
return otq;
}
if (dq->dq_width == 1) {
return _dispatch_lane_serial_drain(dq, dic, flags, owned);
}
return _dispatch_lane_concurrent_drain(dq, dic, flags, owned);
}
|
在之前的文章里已经提到,串行队列的 dq_width 为 1,所以这里会继续调用 _dispatch_lane_serial_drain 函数。
(7)_dispatch_lane_serial_drain
_dispatch_lane_serial_drain 函数 函数实现如下:
1
2
3
4
5
6
7
8
| dispatch_queue_wakeup_target_t
_dispatch_lane_serial_drain(dispatch_lane_class_t dqu,
dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags,
uint64_t *owned)
{
flags &= ~(dispatch_invoke_flags_t)DISPATCH_INVOKE_REDIRECTING_DRAIN;
return _dispatch_lane_drain(dqu._dl, dic, flags, owned, true);
}
|
可以看到,这里最继续执行 _dispatch_lane_drain 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
|
DISPATCH_ALWAYS_INLINE
static dispatch_queue_wakeup_target_t
_dispatch_lane_drain(dispatch_lane_t dq, dispatch_invoke_context_t dic,
dispatch_invoke_flags_t flags, uint64_t *owned_ptr, bool serial_drain)
{
dispatch_queue_t orig_tq = dq->do_targetq;
dispatch_thread_frame_s dtf;
struct dispatch_object_s *dc = NULL, *next_dc;
uint64_t dq_state, owned = *owned_ptr;
if (unlikely(!dq->dq_items_tail)) return NULL;
_dispatch_thread_frame_push(&dtf, dq);
if (serial_drain || _dq_state_is_in_barrier(owned)) {
owned = DISPATCH_QUEUE_IN_BARRIER;
} else {
owned &= DISPATCH_QUEUE_WIDTH_MASK;
}
dc = _dispatch_queue_get_head(dq);
goto first_iteration;
for (;;) {
dispatch_assert(dic->dic_barrier_waiter == NULL);
dc = next_dc;
if (unlikely(!dc)) {
if (!dq->dq_items_tail) {
break;
}
dc = _dispatch_queue_get_head(dq);
}
if (unlikely(_dispatch_needs_to_return_to_kernel())) {
_dispatch_return_to_kernel();
}
if (unlikely(serial_drain != (dq->dq_width == 1))) {
break;
}
if (unlikely(!(flags & DISPATCH_INVOKE_DISABLED_NARROWING) &&
_dispatch_queue_drain_should_narrow(dic))) {
break;
}
if (likely(flags & DISPATCH_INVOKE_WORKLOOP_DRAIN)) {
dispatch_workloop_t dwl = (dispatch_workloop_t)_dispatch_get_wlh();
if (unlikely(_dispatch_queue_max_qos(dwl) > dwl->dwl_drained_qos)) {
break;
}
}
first_iteration:
dq_state = os_atomic_load(&dq->dq_state, relaxed);
if (unlikely(_dq_state_is_suspended(dq_state))) {
break;
}
if (unlikely(orig_tq != dq->do_targetq)) {
break;
}
if (serial_drain || _dispatch_object_is_barrier(dc)) {
if (!serial_drain && owned != DISPATCH_QUEUE_IN_BARRIER) {
if (!_dispatch_queue_try_upgrade_full_width(dq, owned)) {
goto out_with_no_width;
}
owned = DISPATCH_QUEUE_IN_BARRIER;
}
if (_dispatch_object_is_sync_waiter(dc) &&
!(flags & DISPATCH_INVOKE_THREAD_BOUND)) {
dic->dic_barrier_waiter = dc;
goto out_with_barrier_waiter;
}
next_dc = _dispatch_queue_pop_head(dq, dc);
} else {
if (owned == DISPATCH_QUEUE_IN_BARRIER) {
os_atomic_xor2o(dq, dq_state, owned, release);
owned = dq->dq_width * DISPATCH_QUEUE_WIDTH_INTERVAL;
} else if (unlikely(owned == 0)) {
if (_dispatch_object_is_waiter(dc)) {
_dispatch_queue_reserve_sync_width(dq);
} else if (!_dispatch_queue_try_acquire_async(dq)) {
goto out_with_no_width;
}
owned = DISPATCH_QUEUE_WIDTH_INTERVAL;
}
next_dc = _dispatch_queue_pop_head(dq, dc);
if (_dispatch_object_is_waiter(dc)) {
owned -= DISPATCH_QUEUE_WIDTH_INTERVAL;
_dispatch_non_barrier_waiter_redirect_or_wake(dq, dc);
continue;
}
if (flags & DISPATCH_INVOKE_REDIRECTING_DRAIN) {
owned -= DISPATCH_QUEUE_WIDTH_INTERVAL;
_dispatch_continuation_redirect_push(dq, dc,
_dispatch_queue_max_qos(dq));
continue;
}
}
_dispatch_continuation_pop_inline(dc, dic, flags, dq);
}
if (owned == DISPATCH_QUEUE_IN_BARRIER) {
owned += dq->dq_width * DISPATCH_QUEUE_WIDTH_INTERVAL;
}
if (dc) {
owned = _dispatch_queue_adjust_owned(dq, owned, dc);
}
*owned_ptr &= DISPATCH_QUEUE_ENQUEUED | DISPATCH_QUEUE_ENQUEUED_ON_MGR;
*owned_ptr |= owned;
_dispatch_thread_frame_pop(&dtf);
return dc ? dq->do_targetq : NULL;
out_with_no_width:
*owned_ptr &= DISPATCH_QUEUE_ENQUEUED | DISPATCH_QUEUE_ENQUEUED_ON_MGR;
_dispatch_thread_frame_pop(&dtf);
return DISPATCH_QUEUE_WAKEUP_WAIT_FOR_EVENT;
out_with_barrier_waiter:
if (unlikely(flags & DISPATCH_INVOKE_DISALLOW_SYNC_WAITERS)) {
DISPATCH_INTERNAL_CRASH(0,
"Deferred continuation on source, mach channel or mgr");
}
_dispatch_thread_frame_pop(&dtf);
return dq->do_targetq;
}
|
_dispatch_lane_drain 函数主要逻辑就是按照先进先出的顺序,逐个执行串行队列中的各个任务。
2、提交到并发队列
再回头看下 _dispatch_continuation_async 函数:
1
2
3
4
5
6
7
8
9
| static inline void
_dispatch_continuation_async(dispatch_queue_class_t dqu,
dispatch_continuation_t dc, dispatch_qos_t qos, uintptr_t dc_flags)
{
return dx_push(dqu._dq, dc, qos);
}
|
前面已经提到,对于并发队列,dx_push 实际调用的是 _dispatch_lane_concurrent_push 函数。
(1)_dispatch_lane_concurrent_push
该函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| void
_dispatch_lane_concurrent_push(dispatch_lane_t dq, dispatch_object_t dou,
dispatch_qos_t qos)
{
if (unlikely(_dispatch_queue_is_cooperative(dq) &&
!_dispatch_object_supported_on_cooperative_queue(dou))) {
DISPATCH_CLIENT_CRASH(dou._do,
"Cannot target the cooperative root queue - not implemented");
}
if (dq->dq_items_tail == NULL &&
!_dispatch_object_is_waiter(dou) &&
!_dispatch_object_is_barrier(dou) &&
_dispatch_queue_try_acquire_async(dq)) {
return _dispatch_continuation_redirect_push(dq, dou, qos);
}
_dispatch_lane_push(dq, dou, qos);
}
|
在该函数的 if 判断条件里,dq->dq_items_tail 一定是 NULL(具体原因后续会分析)。并且根据其他几个判断条件可知,这里会调用 _dispatch_continuation_redirect_push 函数:
1
2
3
4
5
6
7
8
9
10
11
12
| static void
_dispatch_continuation_redirect_push(dispatch_lane_t dl,
dispatch_object_t dou, dispatch_qos_t qos)
{
dispatch_queue_t dq = dl->do_targetq;
dx_push(dq, dou, qos);
}
|
可以发现,这里又调用了熟悉的 dx_push 宏,但是传入的并不是我们创建的并发队列,而是并发队列的 do_targetq。
在之前的文章《GCD 底层原理 2 - dispatch_queue》 中已经分析了,结论是并发队列和串行队列都是从根队列数组 _dispatch_root_queues 中取出的对应的根队列(root queue)。创建并发队列时,返回的是 _dispatch_root_queues 数组 index = 9 的元素(DISPATCH_ROOT_QUEUE_IDX_DEFAULT_QOS),即:
1
2
3
4
5
6
7
8
9
| [DISPATCH_ROOT_QUEUE_IDX_DEFAULT_QOS] = {
DISPATCH_GLOBAL_OBJECT_HEADER(queue_global),
.dq_state = DISPATCH_ROOT_QUEUE_STATE_INIT_VALUE,
.do_ctxt = _dispatch_root_queue_ctxt(DISPATCH_ROOT_QUEUE_IDX_DEFAULT_QOS),
.dq_atomic_flags = DQF_WIDTH(DISPATCH_QUEUE_WIDTH_POOL),
.dq_priority = _dispatch_priority_make_fallback(DISPATCH_QOS_DEFAULT),
.dq_label = "com.apple.root.default-qos",
.dq_serialnum = 13,
},
|
所以这里调用 dx_push 时传入的实际上是对应的 root queue。而对于 root queue,其 dx_push 对应的函数是 _dispatch_root_queue_push,所以对于后续往队列 push 任务,都是在对应的 root queue 上的,而不是在当然任务 dq 上的。这也是 _dispatch_lane_concurrent_push 里的判断条件 dq->dq_items_tail 为 NULL 的原因。
(2)_dispatch_root_queue_push
该函数精简后的实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
| void
_dispatch_root_queue_push(dispatch_queue_global_t rq, dispatch_object_t dou,
dispatch_qos_t qos)
{
if (_dispatch_root_queue_push_needs_override(rq, qos)) {
return _dispatch_root_queue_push_override(rq, dou, qos);
}
_dispatch_root_queue_push_inline(rq, dou, dou, 1);
}
|
其中 _dispatch_root_queue_push_needs_override、_dispatch_root_queue_push_override 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
static inline bool
_dispatch_root_queue_push_needs_override(dispatch_queue_global_t rq,
dispatch_qos_t qos)
{
dispatch_qos_t fallback = _dispatch_priority_fallback_qos(rq->dq_priority);
if (fallback) {
return qos && qos != fallback;
}
dispatch_qos_t rqos = _dispatch_priority_qos(rq->dq_priority);
return rqos && qos > rqos;
}
DISPATCH_NOINLINE
static void
_dispatch_root_queue_push_override(dispatch_queue_global_t orig_rq,
dispatch_object_t dou, dispatch_qos_t qos)
{
uintptr_t flags = 0;
if (orig_rq->dq_priority & DISPATCH_PRIORITY_FLAG_OVERCOMMIT) {
flags |= DISPATCH_QUEUE_OVERCOMMIT;
} else if (_dispatch_queue_is_cooperative(orig_rq)) {
flags |= DISPATCH_QUEUE_COOPERATIVE;
}
dispatch_queue_global_t rq = _dispatch_get_root_queue(qos, flags);
dispatch_continuation_t dc = dou._dc;
if (_dispatch_object_is_redirection(dc)) {
dc->dc_func = (void *)orig_rq;
} else {
dc = _dispatch_continuation_alloc();
dc->do_vtable = DC_VTABLE(OVERRIDE_OWNING);
、 dc->dc_ctxt = dc;
dc->dc_other = orig_rq;
dc->dc_data = dou._do;
dc->dc_priority = DISPATCH_NO_PRIORITY;
dc->dc_voucher = DISPATCH_NO_VOUCHER;
}
_dispatch_root_queue_push_inline(rq, dc, dc, 1);
}
|
可以看到,最终会调用到 _dispatch_root_queue_push_inline 函数。
(3)_dispatch_root_queue_push_inline
该函数实现如下:
1
2
3
4
5
6
7
8
9
| static inline void
_dispatch_root_queue_push_inline(dispatch_queue_global_t dq,
dispatch_object_t _head, dispatch_object_t _tail, int n)
{
struct dispatch_object_s *hd = _head._do, *tl = _tail._do;
if (unlikely(os_mpsc_push_list(os_mpsc(dq, dq_items), hd, tl, do_next))) {
return _dispatch_root_queue_poke_and_wakeup(dq, n, 0);
}
}
|
将其中涉及到的宏展开后实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| static inline void
_dispatch_root_queue_push_inline(dispatch_queue_global_t dq,
dispatch_object_t _head, dispatch_object_t _tail, int n)
{
struct dispatch_object_s *hd = _head._do, *tl = _tail._do;
__typeof__(atomic_load_explicit((__typeof__(*(&_os_mpsc_head(dq, dq_items))) _Atomic *)(&_os_mpsc_head(dq, dq_items)), memory_order_relaxed)) _token;
_token = os_mpsc_push_update_tail((dq, dq_items), tl, do_next);
os_mpsc_push_update_prev((dq, dq_items), _token, hd, do_next);
if ((_token) == NULL) {
return _dispatch_root_queue_poke_and_wakeup(dq, n, 0);
}
}
|
这里又看到了前面总结过的 MPSC 队列操作。
总结该函数逻辑如下:
- 通过
MPSC 队列操作将任务插入队列尾部。
- 分配线程去处理队列中的任务。
- 调用
_dispatch_root_queue_poke_and_wakeup 函数
其中,_dispatch_root_queue_poke_and_wakeup 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| void
_dispatch_root_queue_poke_and_wakeup(dispatch_queue_global_t dq, int n, int floor)
{
#if !DISPATCH_USE_INTERNAL_WORKQUEUE
#if DISPATCH_USE_PTHREAD_POOL
if (likely(dx_type(dq) == DISPATCH_QUEUE_GLOBAL_ROOT_TYPE ||
dx_type(dq) == DISPATCH_QUEUE_COOPERATIVE_ROOT_TYPE))
#endif
{
int old_pending, new_pending;
os_atomic_rmw_loop2o(dq, dgq_pending, old_pending, new_pending, release, {
new_pending = old_pending ?: n;
});
if (old_pending > 0) {
_dispatch_root_queue_debug("worker thread request still pending "
"for global queue: %p", dq);
return;
}
}
#endif
return _dispatch_root_queue_poke_slow(dq, n, floor);
}
|
该函数主要逻辑是调用 _dispatch_root_queue_poke_slow 函数,且第二个参数 n = 1。
(4) _dispatch_root_queue_poke_slow
精简后的 _dispatch_root_queue_poke_slow 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| static void
_dispatch_root_queue_poke_slow(dispatch_queue_global_t dq, int n, int floor)
{
int remaining = n;
_dispatch_root_queues_init();
if (dx_type(dq) == DISPATCH_QUEUE_GLOBAL_ROOT_TYPE)
{
r = _pthread_workqueue_addthreads(remaining,
_dispatch_priority_to_pp_prefer_fallback(dq->dq_priority));
return;
}
}
|
其中,_dispatch_root_queues_init 函数实现如下:
1
2
3
4
5
6
| static inline void
_dispatch_root_queues_init(void)
{
dispatch_once_f(&_dispatch_root_queues_pred, NULL,
_dispatch_root_queues_init_once);
}
|
这里又调用了 _dispatch_root_queues_init_once 函数,关于该函数在前面串行队列部分已经分析过,函数中关键逻辑如下:
- 配置
workqueue 回调函数
workq_cb = _dispatch_worker_thread2
- 配置
workloop 回调函数
workloop_cb = _dispatch_workloop_worker_thread
而且前面也已经分析过,并发队列是基于 workqueue 的,从 _dispatch_root_queue_poke_slow 函数实现也可以看到,函数逻辑中没有涉及到像串行队列那样的 workloop 的配置。所以在 _dispatch_root_queue_poke_slow 函数中,调用 _pthread_workqueue_addthreads 完成线程的分配之后,会执行 workqueue 回调函数 _dispatch_worker_thread2。
_pthread_workqueue_addthreads 函数有两个参数:
而上面调用 _pthread_workqueue_addthreads 函数时,传入的 numthreads 参数为 1,表示请求分配一个线程去处理任务。
按照经验来看,dispatch_async + 并发队列,是会分配多个线程去处理各个任务的。为什么这一步却只请求一个线程去处理任务呢?后面会分析原因。
(5)_dispatch_worker_thread2
该函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| static void
_dispatch_worker_thread2(pthread_priority_t pp)
{
dispatch_queue_global_t dq;
dispatch_invoke_flags_t invoke_flags = 0;
uintptr_t rq_flags = 0;
if (cooperative) {
rq_flags |= DISPATCH_QUEUE_COOPERATIVE;
invoke_flags |= DISPATCH_INVOKE_COOPERATIVE_DRAIN;
} else {
rq_flags |= (overcommit ? DISPATCH_QUEUE_OVERCOMMIT : 0);
}
dq = _dispatch_get_root_queue(_dispatch_qos_from_pp(pp), rq_flags);
invoke_flags |= DISPATCH_INVOKE_WORKER_DRAIN | DISPATCH_INVOKE_REDIRECTING_DRAIN;
_dispatch_root_queue_drain(dq, dq->dq_priority, invoke_flags);
}
|
在该函数中,主要是调用了 _dispatch_root_queue_drain 函数去执行具体任务。
(6)_dispatch_root_queue_drain
_dispatch_root_queue_drain 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| static void
_dispatch_root_queue_drain(dispatch_queue_global_t dq,
dispatch_priority_t pri, dispatch_invoke_flags_t flags)
{
_dispatch_queue_set_current(dq);
struct dispatch_object_s *item;
dispatch_invoke_context_s dic = { };
while (likely(item = _dispatch_root_queue_drain_one(dq))) {
_dispatch_continuation_pop_inline(item, &dic, flags, dq);
}
_dispatch_queue_set_current(NULL);
}
|
该函数核心逻辑如下:
- 将当前线程与队列关联。
- 确保任务执行期间,GCD 能正确识别当前线程所属队列,防止线程池中的线程后续任务调度混乱。
- 使用
while 循环,按照 FIFO 顺序取出一个任务 item。
- 取任务调用的
_dispatch_root_queue_drain_one 函数。
while 循环中,弹出并执行的上一步取出的任务 item。
- 调用
_dispatch_continuation_pop_inline 函数。
- 所有任务处理完成后,将当前线程与队列取消关联。
这里需要重点看下 _dispatch_root_queue_drain_one 函数,这是实现多线程并发执行的关键。
(7)_dispatch_root_queue_drain_one
该函数内部实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| static inline struct dispatch_object_s *
_dispatch_root_queue_drain_one(dispatch_queue_global_t dq)
{
struct dispatch_object_s *head, *next;
start:
head = os_atomic_xchg2o(dq, dq_items_head,
DISPATCH_ROOT_QUEUE_MEDIATOR, relaxed);
if (unlikely(head == NULL)) {
if (unlikely(!os_atomic_cmpxchg2o(dq, dq_items_head,
DISPATCH_ROOT_QUEUE_MEDIATOR, NULL, relaxed))) {
goto start;
}
if (unlikely(dq->dq_items_tail)) {
if (__DISPATCH_ROOT_QUEUE_CONTENDED_WAIT__(dq,
_dispatch_root_queue_head_tail_quiesced)) {
goto start;
}
}
_dispatch_root_queue_debug("no work on global queue: %p", dq);
return NULL;
}
if (unlikely(head == DISPATCH_ROOT_QUEUE_MEDIATOR)) {
if (likely(__DISPATCH_ROOT_QUEUE_CONTENDED_WAIT__(dq,
_dispatch_root_queue_mediator_is_gone))) {
goto start;
}
return NULL;
}
next = head->do_next;
if (unlikely(!next)) {
os_atomic_store2o(dq, dq_items_head, NULL, relaxed);
if (os_atomic_cmpxchg2o(dq, dq_items_tail, head, NULL, release)) {
goto out;
}
next = os_mpsc_get_next(head, do_next, &dq->dq_items_tail);
}
os_atomic_store2o(dq, dq_items_head, next, relaxed);
_dispatch_root_queue_poke(dq, 1, 0);
out:
return head;
}
|
该函数核心逻辑有两部分:
- 按照
FIFO 顺序取一个任务并返回,交由外面 _dispatch_continuation_pop_inline 函数取执行任务。
- 调用
_dispatch_root_queue_poke 函数。
- 该函数内部会再次调用
_dispatch_root_queue_poke_slow 函数。
_dispatch_root_queue_poke 函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| void
_dispatch_root_queue_poke(dispatch_queue_global_t dq, int n, int floor)
{
if (!_dispatch_queue_class_probe(dq)) {
return;
}
#if !DISPATCH_USE_INTERNAL_WORKQUEUE
#if DISPATCH_USE_PTHREAD_POOL
if (likely(dx_type(dq) == DISPATCH_QUEUE_GLOBAL_ROOT_TYPE ||
dx_type(dq) == DISPATCH_QUEUE_COOPERATIVE_ROOT_TYPE))
#endif
{
if (unlikely(!os_atomic_cmpxchg2o(dq, dgq_pending, 0, n, release))) {
_dispatch_root_queue_debug("worker thread request still pending "
"for global queue: %p", dq);
return;
}
}
#endif
return _dispatch_root_queue_poke_slow(dq, n, floor);
}
|
可以看到,这里再次调用了 _dispatch_root_queue_poke_slow 函数,上面已经提到 _dispatch_root_queue_poke_slow 会请求分配 1 个线程去执行任务。
这个“循环”的执行链路如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
| _dispatch_root_queue_poke_slow
⬇️
_pthread_workqueue_addthreads // 申请分配 1 个线程去执行任务
⬇️
_dispatch_worker_thread2
⬇️
_dispatch_root_queue_drain // 调用 _dispatch_root_queue_drain_one 取出 1 个任务并执行
⬇️
_dispatch_root_queue_drain_one
⬇️
_dispatch_root_queue_poke_slow // 新一轮循环,申请 1 个线程执行 1 个任务
⬇️
......
|
这里就是 dispatch_async + 并发队列的多线程并发执行的关键逻辑了:每次申请 1 个线程去执行 1 个任务,在从队列取任务的同时,同时去申请新的线程执行下个任务,这样就达到了多个线程并发执行任务的目的。而具体哪个任务先执行,则取决于的线程调度先后。
这里用到了“任务窃取优化”:
新创建的线程立即进入 _dispatch_root_queue_drain 循环,尝试从队列中窃取任务执行。提高多核 CPU 利用率,减少任务排队时间。
(8)_dispatch_continuation_pop_inline
这里再回头简单看下上一步取出的任务,是如何执行的。执行时调用的是 _dispatch_continuation_pop_inline 函数,该函数实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| static inline void
_dispatch_continuation_pop_inline(dispatch_object_t dou,
dispatch_invoke_context_t dic, dispatch_invoke_flags_t flags,
dispatch_queue_class_t dqu)
{
dispatch_pthread_root_queue_observer_hooks_t observer_hooks =
_dispatch_get_pthread_root_queue_observer_hooks();
if (observer_hooks) observer_hooks->queue_will_execute(dqu._dq);
flags &= _DISPATCH_INVOKE_PROPAGATE_MASK;
if (_dispatch_object_has_vtable(dou)) {
if (dx_type(dou._do) == DISPATCH_SWIFT_JOB_TYPE) {
dx_invoke(dou._dsjc, NULL,
_dispatch_invoke_flags_to_swift_invoke_flags(flags));
} else {
dx_invoke(dou._dq, dic, flags);
}
} else {
_dispatch_continuation_invoke_inline(dou, flags, dqu);
}
if (observer_hooks) observer_hooks->queue_did_execute(dqu._dq);
}
|
上面主要逻辑是判断传入的任务是否有虚函数表,如果有的话调用 dx_invoke 宏执行任务,否则调用 _dispatch_continuation_invoke_inline 宏执行任务。
由于传进来的任务,是前面包装好的 continuation,是没有虚函数表的,所以这里会继续调用 _dispatch_continuation_invoke_inline 函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| static inline void
_dispatch_continuation_invoke_inline(dispatch_object_t dou,
dispatch_invoke_flags_t flags, dispatch_queue_class_t dqu)
{
dispatch_continuation_t dc = dou._dc, dc1;
dispatch_invoke_with_autoreleasepool(flags, {
uintptr_t dc_flags = dc->dc_flags;
_dispatch_continuation_voucher_adopt(dc, dc_flags);
if (!(dc_flags & DC_FLAG_NO_INTROSPECTION)) {
_dispatch_trace_item_pop(dqu, dou);
}
if (dc_flags & DC_FLAG_CONSUME) {
dc1 = _dispatch_continuation_free_cacheonly(dc);
} else {
dc1 = NULL;
}
if (unlikely(dc_flags & DC_FLAG_GROUP_ASYNC)) {
_dispatch_continuation_with_group_invoke(dc);
} else {
_dispatch_client_callout(dc->dc_ctxt, dc->dc_func);
_dispatch_trace_item_complete(dc);
}
if (unlikely(dc1)) {
_dispatch_continuation_free_to_cache_limit(dc1);
}
});
_dispatch_perfmon_workitem_inc();
}
|
上述核心逻辑如下:
- 使用
autoreleasepool 包裹调度项的执行,确保在执行过程中管理内存。
- 判断是否是
dispatch_group 任务组。
- 如果是
dispatch_group 任务组,调用 _dispatch_continuation_with_group_invoke 执行。
- 如果是普通任务,调用
_dispatch_client_callout 执行任务。
- 释放
continuation,存到线程的 continuation 缓存池。
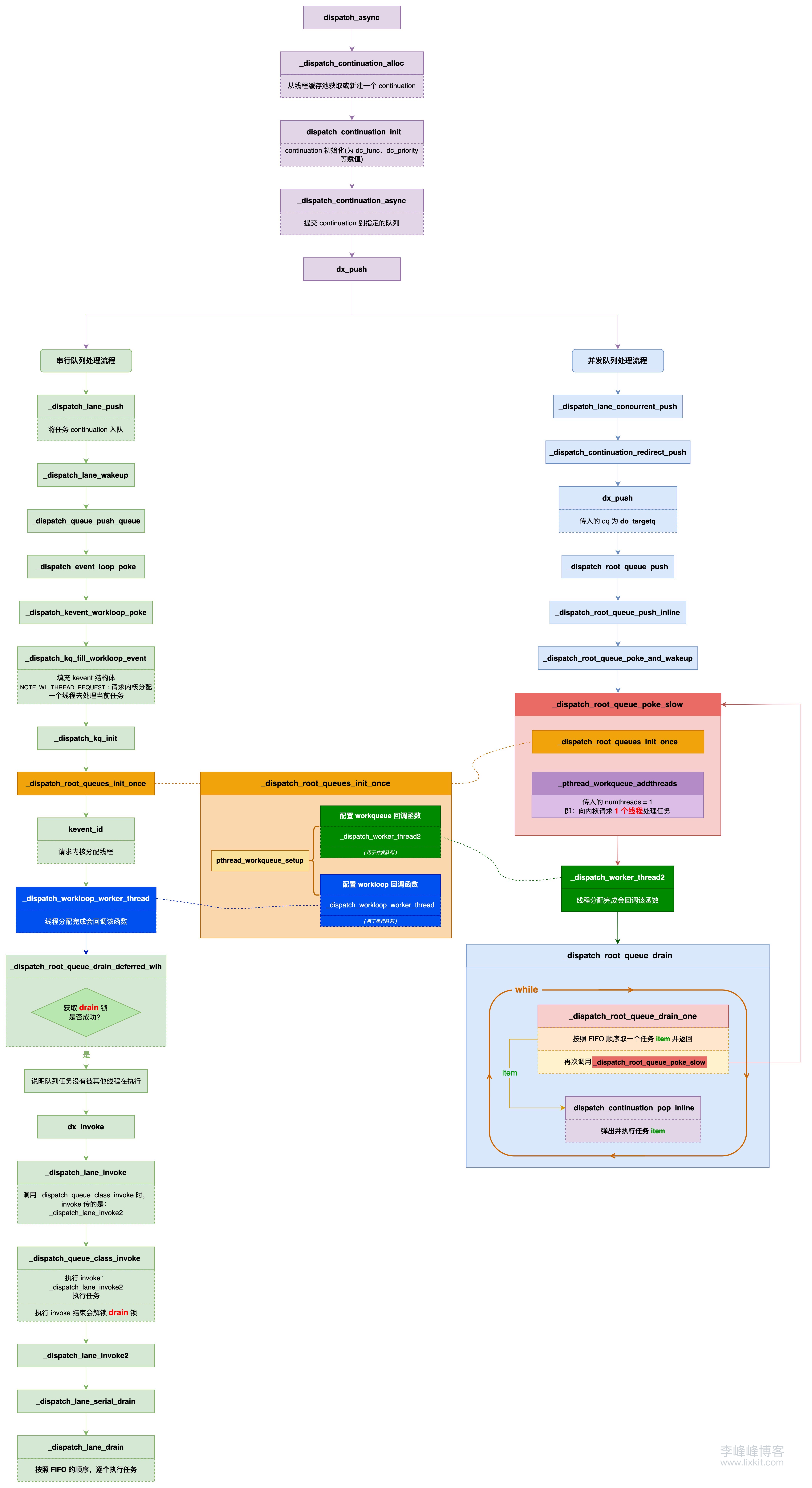
六、总结
可以用下图表示 dispatch_async + 串行队列/并发队列的逻辑: