一、图像渲染原理
1、iOS 双缓冲机制
图像的渲染离不开 CPU 和 GPU 的协作:
CPU(Central Processing Unit,中央处理器)
- 对象的创建和销毁、对象属性的调整、布局计算、文本的计算和排版、图片的格式转换和解码、图像的绘制(Core Graphics)
GPU(Graphics Processing Unit,图形处理器)
- 纹理的渲染(CPU 计算好的数据不能直接展示到屏幕,需要经过 GPU 的渲染)
CPU 计算之后数据不能直接用于显示,CPU 将计算之后的图像信息(即:图元 primitives)传给 GPU ,由 GPU 负责后续的渲染,GPU 会将渲染结束之后像素信息(即:位图 bitmap),存在帧缓冲器(Framebuffer)中,视频控制器(Video Controller)会读取帧缓冲器中的信息,经过数模转换传递给显示器(Monitor),进行显示,流程如下: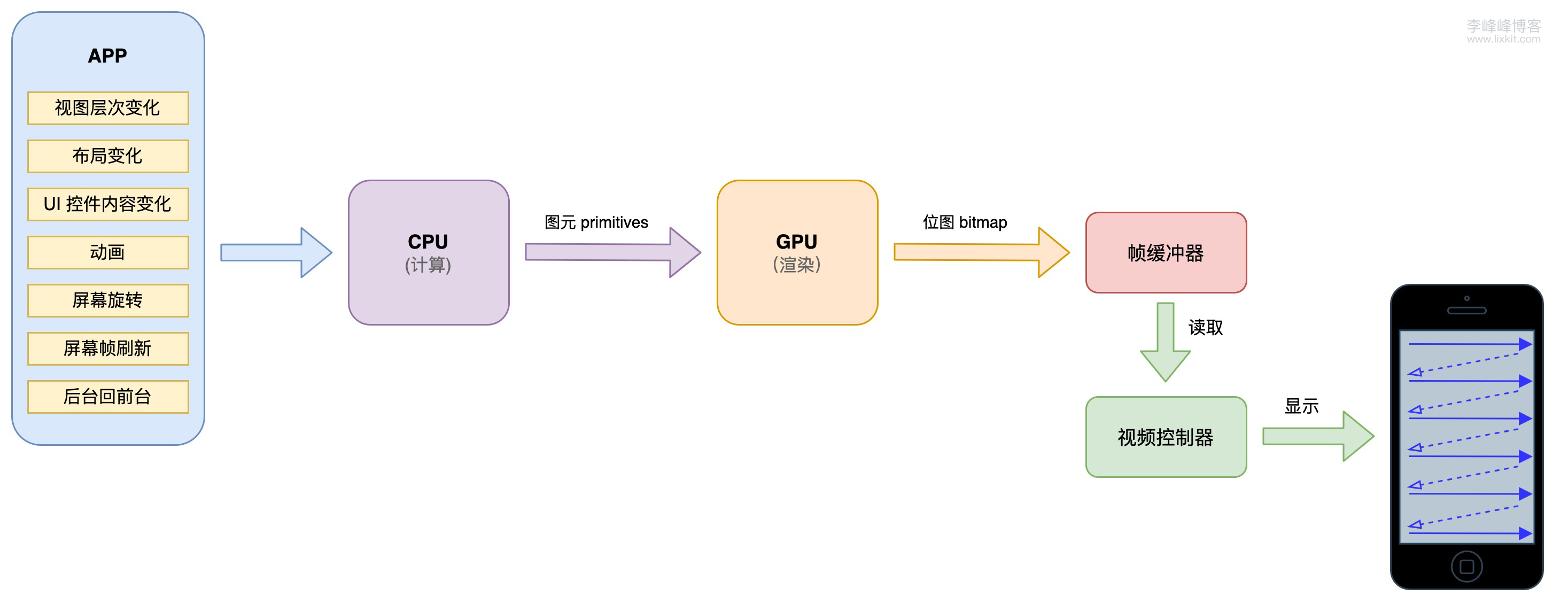
显示器的电子束会从屏幕的左上角开始逐行扫描,当电子枪换到新的一行,准备进行扫描时,显示器会发出一个水平同步信号 HSync,而当一帧画面绘制完成后,电子枪回复到原位,准备画下一帧前,显示器会发出一个垂直同步信号 VSync。扫描时,屏幕上的每个点的图像信息都从帧缓冲器中的位图进行读取,在屏幕上对应地显示。扫描的流程如下图所示: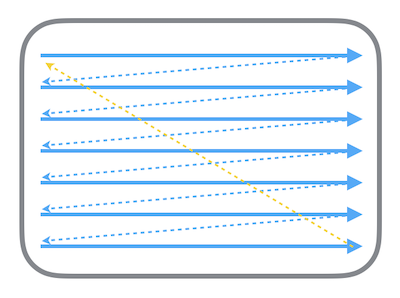
每次整个屏幕被扫描完一次后,就相当于呈现了一帧完整的图像。屏幕不断地刷新,不停呈现新的帧,就能呈现出连续的影像。
屏幕刷新的频率,就是帧率(Frame per Second,FPS)。由于人眼的视觉暂留效应,当屏幕刷新频率足够高时(FPS 通常是 50 到 60 左右),就能让画面看起来是连续而流畅的。对于 iOS 而言,APP 应该尽量保证 60 FPS 才是最好的体验。
单缓冲器与屏幕撕裂
在单缓冲器的情况下,很容易产生屏幕撕裂,CPU+GPU 的渲染流程是一个非常耗时的过程。如果在电子束开始扫描新的一帧时,位图还没有渲染好,那么这时候帧缓冲器中还是上一帧的内容,显示器的电子束会再次将上一帧内容扫描到屏幕上。扫描一半时,新一帧才被正常渲染完成并放入帧缓冲器中。 那么已扫描的部分就是上一帧的画面,而未扫描的部分则会显示新的一帧图像,于是造成了屏幕撕裂:
垂直同步 Vsync + 双缓冲机制 Double Buffering
解决屏幕撕裂、提高显示效率的一个策略就是使用垂直同步信号 Vsync 与双缓冲机制 Double Buffering。根据苹果的官方文档描述,iOS 设备会始终使用 Vsync + Double Buffering 的策略。
垂直同步信号(vertical synchronisation,Vsync)相当于给帧缓冲器加锁:当电子束完成一帧的扫描,将要从头开始扫描时,就会发出一个垂直同步信号。只有当视频控制器接收到 Vsync 之后,才会将帧缓冲器中的位图更新为下一帧,这样就能保证每次显示的都是同一帧的画面,因而避免了屏幕撕裂。
但是这种情况下,视频控制器在接受到 Vsync 之后,就要将下一帧的位图传入,这意味着整个 CPU+GPU 的渲染流程都要在一瞬间完成,这是明显不现实的。所以双缓冲机制会增加一个新的备用缓冲器(back buffer)。在电子束在扫描帧缓冲器中的内容时,CPU 和 GPU 同时渲染下一帧的内容,渲染结果会预先保存在 back buffer 中,当一帧扫描结束接收到 Vsync 信号的时候,视频控制器会将 back buffer 中的内容置换到 frame buffer 中,此时就能保证置换操作几乎在一瞬间完成(实际上是交换了内存地址),这样就通过充分利用 CPU 和 GPU 资源解决了屏幕撕裂的问题。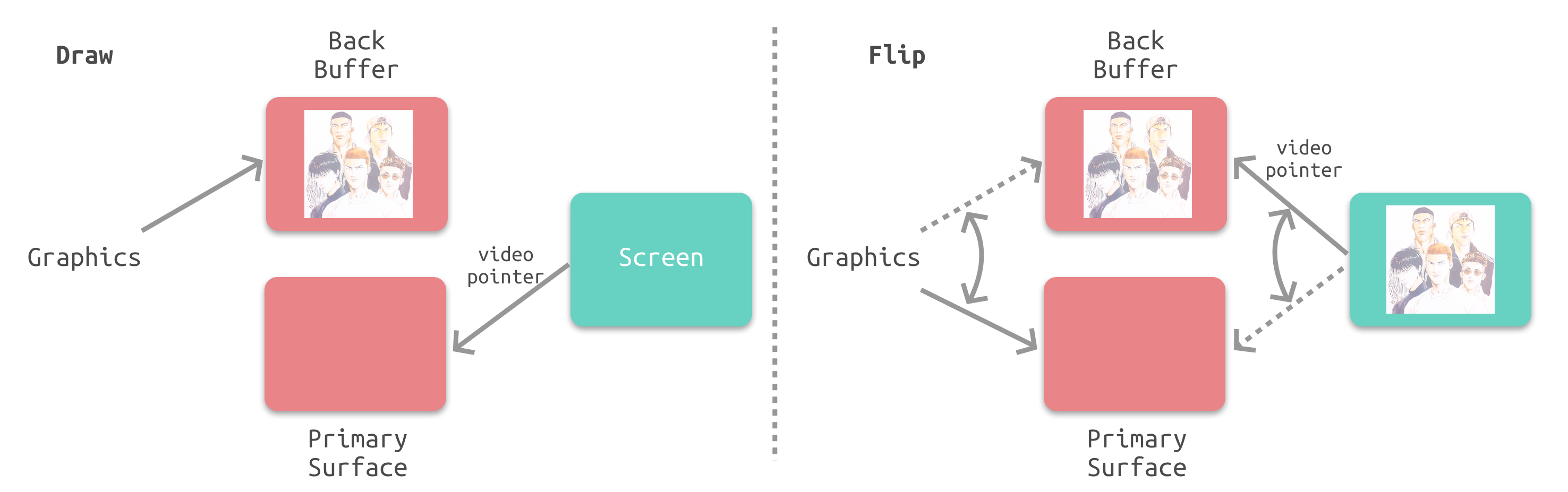
2、Core Animation
Core Animation 职责并非像其名字一样只负责动画,而是同时兼顾 UI 渲染、构建和实现动画等重要职责,就像 Apple 文档所说:
If you are writing iOS apps, you are using Core Animation whether you know it or not。
也就是说无论我们开发过程中是否直接使用了 Core Animation,它都在底层深度参与了 APP 的构建。
Core Animation 是 iOS 和 OSX 上的图形渲染和动画基础结构,用于为应用的视图和其他视觉元素设置动画。它把大量的绘图工作交给 GPU 去加速渲染,所以可以实现高帧率高流畅度的动画效果,而不会增加 CPU 负担和减慢应用程序的速度。
Core Animation 并不是一个绘图系统,而是使用硬件去合成和处理视图内容的基础框架,而这个基础框架的核心就是 CALayer 对象,Core Animation 的职责就是尽可能快地组合屏幕上不同的 CALayer,并且被存储为树状层级结构。这个树也形成了 UIKit 以及在 iOS 应用程序当中你所能在屏幕上看见的一切的基础。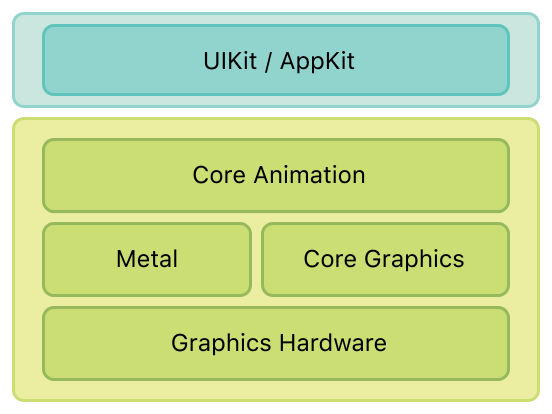
上面是来自 Apple 官方文档的一个架构图,上图还涉及到 Metal 和 Core Graphics:
Metal
类似于 OpenGL ES 的图形处理框架,Apple 早在 2014 年就推出了 Metal,从 iOS 12 开始 OpenGL ES 被弃用,正式被 Metal 取代,其绘制工作主要使用 GPU。Core Graphics
Core Graphics 是一个强大的二维图像绘制引擎,是 iOS 的核心图形库,常用的比如 CGRect 就定义在这个框架下,其绘制工作主要使用 CPU。
Core Animation 渲染流水线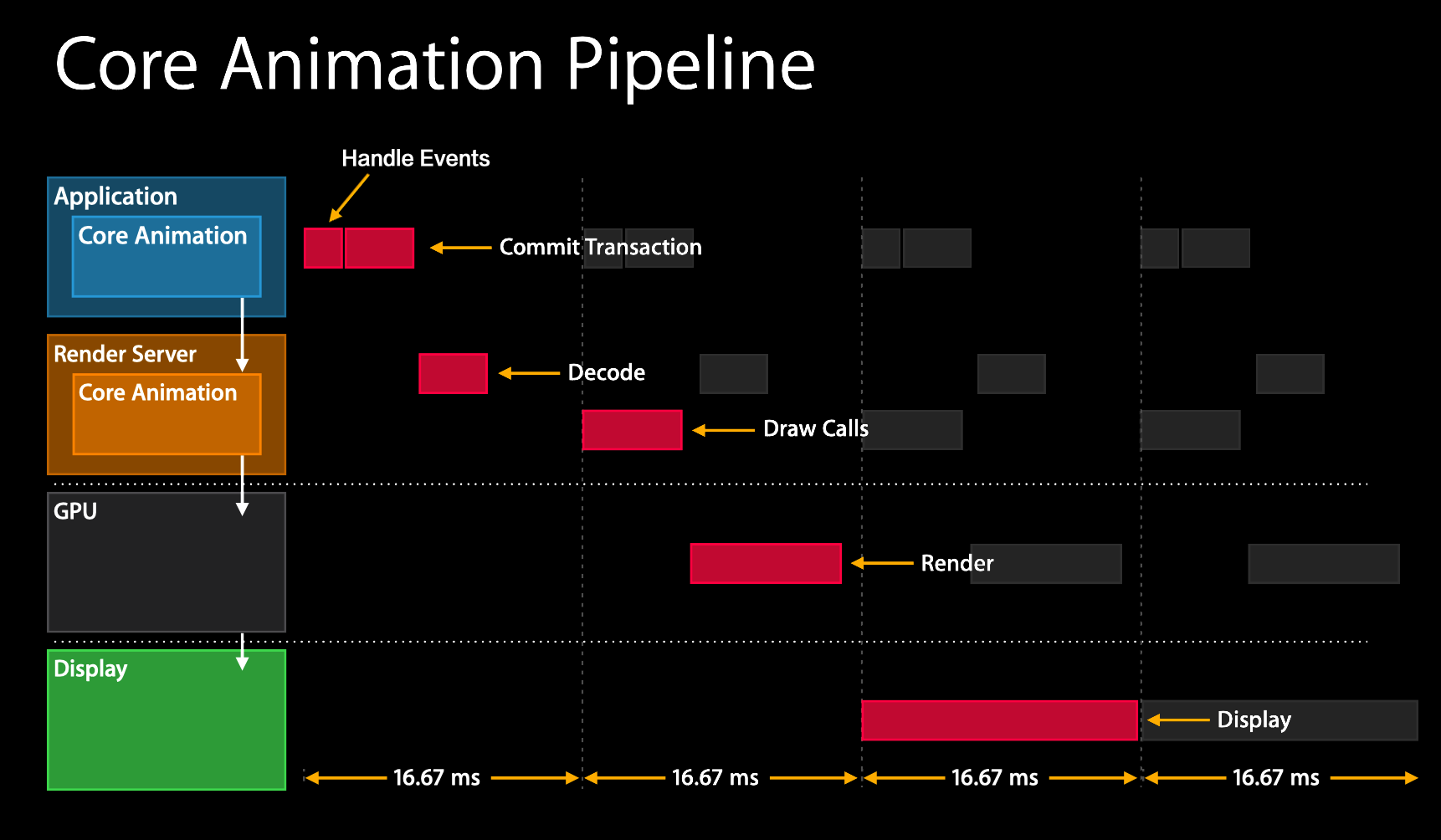
上图即为 Core Animation 的渲染流水线,APP 进程本身是不负责渲染的,CATransaction 把一组 UI 上的修改,合并成一个事务,通过 commit 提交给 RenderServer,RenderServer 在一个单独的进程里进行渲染,调用渲染框架(Metal/OpenGL ES)来生成 bitmap,放到帧缓冲区里,硬件根据时钟信号读取帧缓冲区内容,完成屏幕刷新。
根据上图可以看到,一次完整渲染流程需要跨越 3 帧才能完成,我们 iOS 设备的刷帧率是 60 FPS(Frame per Second 帧/秒),也就是 1 秒钟可以刷新 60 帧(次)。完成一帧刷新的用时是 16.67ms。因此垂直同步信号 VSync 就是每 16.67ms 发出一次。Core Animation 渲染流水线不停地进行,使每一帧都能展示对应的画面,我们就看到了流畅的画面。换句话说,这些阶段里任何一阶段因耗时太长无法正常在一帧内完成,都会引起卡顿的产生。
Core Animation 一次完整的渲染流水线中主要有 4 个阶段:
第一阶段:准备图层和动画属性
此阶段发生在应用内,也是开发者最直接接触的阶段,该阶段工作在 CPU 上,分为 Handle Events、Commit Transaction 两大部分:
Handle Events
APP 先响应和处理点击、手势等用户交互事件,这一阶段如果涉及视图/图层的改变,就会触发渲染流水线开始。Commit Transaction

Commit Transaction 包含布局、显示、准备、提交四个阶段,发生在应用程序进程内,并且是在 CPU 上工作。Layout:布局
这个阶段主要处理视图的构建和布局,具体步骤包括:- 调用重载的
layoutSubviews方法 - 创建视图,并通过
addSubview方法添加子视图 - 计算视图布局,即所有的 Layout Constraint
由于这个阶段是在 CPU 中进行,通常是 CPU 限制或者 IO 限制,所以我们应该尽量高效轻量地操作,减少这部分的时间,比如减少非必要的视图创建、简化布局计算、减少视图层级等。
- 调用重载的
Display:显示
这个阶段主要是交给 Core Graphics 进行视图的绘制,注意不是真正的显示,而是得到前文所说的图元 primitives 数据:- 根据上一阶段 Layout 的结果创建得到图元信息。
- 如果重写了
drawRect:方法,那么会调用重载的drawRect:方法,在drawRect:方法中手动绘制得到 bitmap 数据,从而自定义视图的绘制。
注意正常情况下 Display 阶段只会得到图元 primitives 信息,而位图 bitmap 是在 GPU 中根据图元信息绘制得到的。但是如果重写了
drawRect:方法,这个方法会直接调用 Core Graphics 绘制方法得到 bitmap 数据,同时系统会额外申请一块内存,用于暂存绘制好的 bitmap,后续 bitmap 到了 GPU 那里经过一定处理之后会跟 GPU 渲染出的 bitmap 一块组合展示。
由于重写了drawRect:方法,导致绘制过程从 GPU 转移到了 CPU,这就导致了一定的效率损失。与此同时,这个过程会额外使用 CPU 和内存,因此需要高效绘制,否则容易造成 CPU 卡顿或者内存爆炸。Prepare:准备
这是 Core Animation 准备发送动画数据到 Render Server 的阶段。这同时也是 Core Animation 将要执行一些额外事务的时间点,主要包括:- 图片解码;
- 图片转换;
Commit:提交
这一步主要是:在 Runloop 即将休眠(BeforeWaiting)或退出(Exit)时,将图层打包并发送到 Render Server。
Render Server 是在单独的进程上工作的,APP 进程和 Render Server 进程之间通过 IPC 进行通信。
注意 commit 操作是依赖图层树递归执行的,所以如果图层树过于复杂,commit 的开销就会很大。这也是我们希望减少视图层级,从而降低图层树复杂度的原因。
第二阶段:解码及绘制调用
此阶段发生在 Render Server 内,工作在 CPU 上,分为两个阶段:
- Decode
使用 Core Animation 解码收到的图层树。 - Draw Calls
Core Animation 解码完成后,CPU 通过调用绘制命令(称为一次 Draw Call)来告诉 GPU 开始进行一个渲染过程的,Draw Call 命令会告诉 GPU 需要渲染的信息,包含图元信息。
第三阶段:渲染
此阶段工作在 GPU 上,GPU 接收到 Draw Call 命令之后就会开始进行一次渲染流程。调用着色器,进行像素渲染,最终得到位图 bitmap,并存储到帧缓冲区中。
第四阶段:展示
在 VSync 到达时,视频控制器读取帧缓冲区的数据,交给显示器显示。
根据 Core Animation 渲染流水线可以知道,为了保证渲染流畅进行,我们在开发阶段需要注意:
- 尽量减少非必要的视图创建、简化布局计算、减少视图层级。
- 如非必要,不要重写
drawRect:方法。如果重写了drawRect:方法,需要保证高效绘制,以减少 CPU 消耗。
3、UIView & CALayer
(1) UIView 和 CALayer 的关系
前面提到 Core Animation 的核心就是 CALayer 对象,是显示的基础。那么 UIView 和 CALayer 之间有什么关系呢?
UIView 和 CALayer 概念上很相似,同样也是一些被层级关系树管理的矩形块,同样也可以包含一些内容,管理子图层的位置。两者不同的是:UIView 可以处理触摸事件;CALayer 不处理用户的交互,不参与响应事件传递。
对于 UIView 视图来说真正的负责内容展示的其实是它内部的 CALayer,UIView 只是将自身的展示任务交给了内部的 CALayer 完成,而它还肩负着一些其它的任务,比如说用户的交互响应,提供一些 Core Animation 底层方法的高级接口等,这也是使用了职责分离的设计思想。
UIView 定义如下:
1 | @interface UIView : UIResponder <NSCoding, UIAppearance, UIAppearanceContainer, UIDynamicItem, UITraitEnvironment, UICoordinateSpace, UIFocusItem, UIFocusItemContainer, CALayerDelegate> |
CALayer 定义如下:
1 | @interface CALayer : NSObject <NSSecureCoding, CAMediaTiming> |
可以看出:CALayer 是继承于 NSObject;UIView 是继承于 UIResponder,每个 UIView 都拥有一个非空的 CALayer。CALayer 有一个可选的 delegate 属性,实现了 CALayerDelegate 协议。UIView 作为 CALayer 的代理实现了 CALayerDelegae 协议。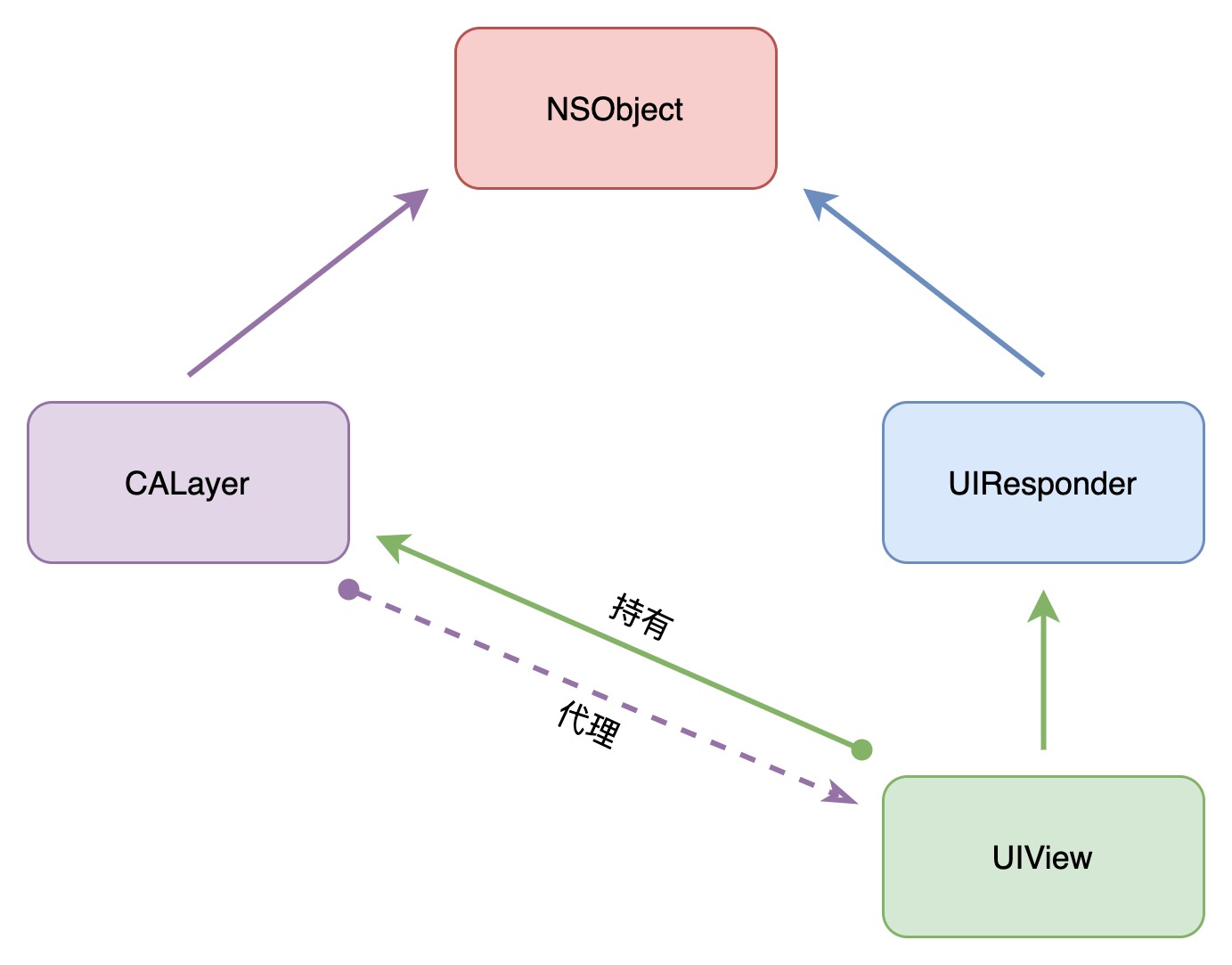
CALayer 之所以可以呈现可视化内容,是因为 CALayer 保存了 Metal/OpenGL 渲染需要的顶点数据和纹理数据。其中顶点数据是必须要有的,而纹理数据不是必需的,图形渲染流水线支持从顶点开始进行绘制(GPU 会处理顶点数据并生成纹理),也支持直接使用纹理进行渲染。
顶点数据
通过我们给CALayer设置各种属性比如frame、backgroundColor来获取。即 Metal/OpenGL 获取到位置和大小信息,当然还包括一个颜色来进行一个图形的渲染。纹理数据
CALayer有个属性contents,contents指向一块缓存区,称为 backing store,可以存放位图(Bitmap),iOS 中将该缓存区保存的 Bitmap 称为寄宿图。这个也就是 Metal/OpenGL 渲染可以使用的纹理数据了。
设置寄宿图有两种方式:使用图片(contents image)和手动绘制(custom drawing)。
使用图片(contents image)
Contents Image 是指通过 CALayer 的 contents 属性来配置图片。关于 contents 属性,根据代码注释也可以知道 contents 默认是 nil,可以用来存储 CALayer 要显示的内容,在 iOS 中可以存储 CGImageRef,即 CGImage,在 macOS 下可以存储 CGImage 或 NSImage。
Apple 对 CGImageRef 的定义是:
A bitmap image or image mask.
也就是说 CALayer.contents 就可以存储 bitmap,这就和前面 Core Animation 渲染流水线关联起来了。
例如:
1 | UIImage *myImage = [UIImage imageNamed:@"myImage"]; |
手动绘制(custom drawing)
Custom Drawing 是指使用 Core Graphics 直接绘制寄宿图。实际开发中,一般通过继承 UIView 并实现 drawRect: 方法来自定义绘制。
例如,绘制一个圆形:
1 | - (void)drawRect:(CGRect)rect { |
虽然 drawRect: 是一个 UIView 的方法,但实际上都是底层的 CALayer 完成了重绘工作并保存了产生的图片,在 drawRect: 方法中加断点打印的调用栈如下:
1 | // ... |
主要逻辑如下:
UIView作为CALayer的代理实现了CALayerDelegae协议,CALayerDelegae中声明了displayLayer:、drawLayer:inContext:等方法。当我们重写了
drawRect:方法时,CALayer会调用display方法请求其代理(即UIView)给予一个寄宿图来显示。CALayer首先会尝试调用displayLayer:方法,此时代理可以直接设置contents属性。- (void)displayLayer:(CALayer *)layer;如果
CALayer的代理没有实现displayLayer:方法,CALayer则会尝试调用drawLayer:inContext:方法。在调用该方法前,CALayer会创建一个空的寄宿图和一个 Core Graphics 的绘制上下文CGContextRef,为绘制寄宿图做准备,作为ctx参数传入。- (void)drawLayer:(CALayer *)layer inContext:(CGContextRef)ctx;drawLayer:inContext:内部会再去调用我们重写的drawRect:方法进行绘制。最后,由 Core Graphics 绘制生成的寄宿图会通过 context(
CGContextRef) 存入 backing store,后续会提交给 GPU 进行对应的渲染显示流程。
根据上述逻辑可知,一旦我们重写了 drawRect: 方法,即使方法内部没有任何绘制逻辑,系统也会默认生成一张空的寄宿图,会对 CPU 和内存产生消耗。这也就是前面 Core Animation 渲染流水线内容里提到“如非必要,不要重写 drawRect: 方法”的原因。
这里有个细节需要注意,drawRect: 方法中获取并使用了上下文 context(CGContextRef),实际上也只有在 drawRect: 方法中才能使用这个上下文 context。
因为 drawRect: 方法在 drawLayer:inContext: 里被调用, 并且被调用前有个 UIGraphicsPushContext(context) 方法将视图图层对应上下文压入栈顶,然后 drawRect: 执行完后,将视图图层对应上下文执行出栈操作。系统会维护一个 CGContextRef 的栈,而 UIGraphicsGetCurrentContext() 会取栈顶的 CGContextRef, 当前视图图层的上下文的入栈和出栈操作恰好将 drawRect: 的执行包裹在其中,所以说只在 drawRect: 方法里才能获取当前图层的上下文。
相关逻辑伪代码如下:
1 | - (void)drawLayer:(CALayer*)layer inContext:(CGContextRef)context { |
(2) UI 更新与 RunLoop
操作 UI 时,比如改变了 Frame、更新了 UIView/CALayer 的层次时,或者手动调用了 UIView/CALayer 的 setNeedsLayout/setNeedsDisplay 方法后,这个 UIView/CALayer 就被标记为待处理,并被提交到一个全局的容器去,这个容器就保存了这些 CATransaction 事务。
CATransaction 的作用就是捕获 CALayer 的变化,然后提交,就像下面这样:
1 | [CATransaction begin]; |
苹果注册了一个 RunLoop Observer 监听 BeforeWaiting(即将进入休眠) 和 Exit (退出) 事件,回调去执行一个很长的函数:_ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv()
这个函数里会遍历所有待处理的 UIView/CAlayer 以执行实际的绘制和调整,并更新 UI 界面。
我们看到下面的代码中就是获取到这个全局的 Transaction 容器,然后执行 Transaction commit,判断 layout_if_needed() 和 display_if_needed(),然后执行视图的创建、布局计算、图片解码、文本绘制等。
1 | _ZN2CA11Transaction17observer_callbackEP19__CFRunLoopObservermPv() |
如果想要立刻根据刷新标记刷新视图,可以调用 layoutIfNeeded 方法,该方法会触发立刻刷新。如果 view 被标记了需要刷新,那么调用 layoutIfNeeded 方法之后,subView 的 layoutSubviews 方法会被调用。
(3) 异步绘制
当我们调用了 setNeedsDisplay 方法后,RunLoop 即将进入休眠和结束的时候会调用 [CALayer display],如果 CALayer 的代理(即 UIView)实现了 dispalyLayer: 方法,那么 dispalyLayer: 会被调用。
CoreGraphic 的绘制方法是线程安全的,我们可以在子线程中去做异步绘制的工作,我们虽然不能在非主线程将内容绘制到 layer 的 context 上,但是我们可以将需要绘制的内容绘制在一个自己创建的 context 上,绘制完成后切换到到主线程, 为 layer.contents 赋值。例如:
1 | - (void)display { |
当然这个是重写的 CALayer 的 display 方法实现的。我们也可以重写 UIView 的 dispalyLayer: 方法,在 dispalyLayer: 方法中按照相同方式进行异步绘制。
二、离屏渲染
根据前文,简化来看,通常的渲染流程是这样的:
App 通过 CPU 和 GPU 的合作,不停地将内容渲染完成放入 Framebuffer 帧缓冲器中,而显示屏幕不断地从 Framebuffer 中获取内容,显示实时的内容。
而离屏渲染的流程是这样的: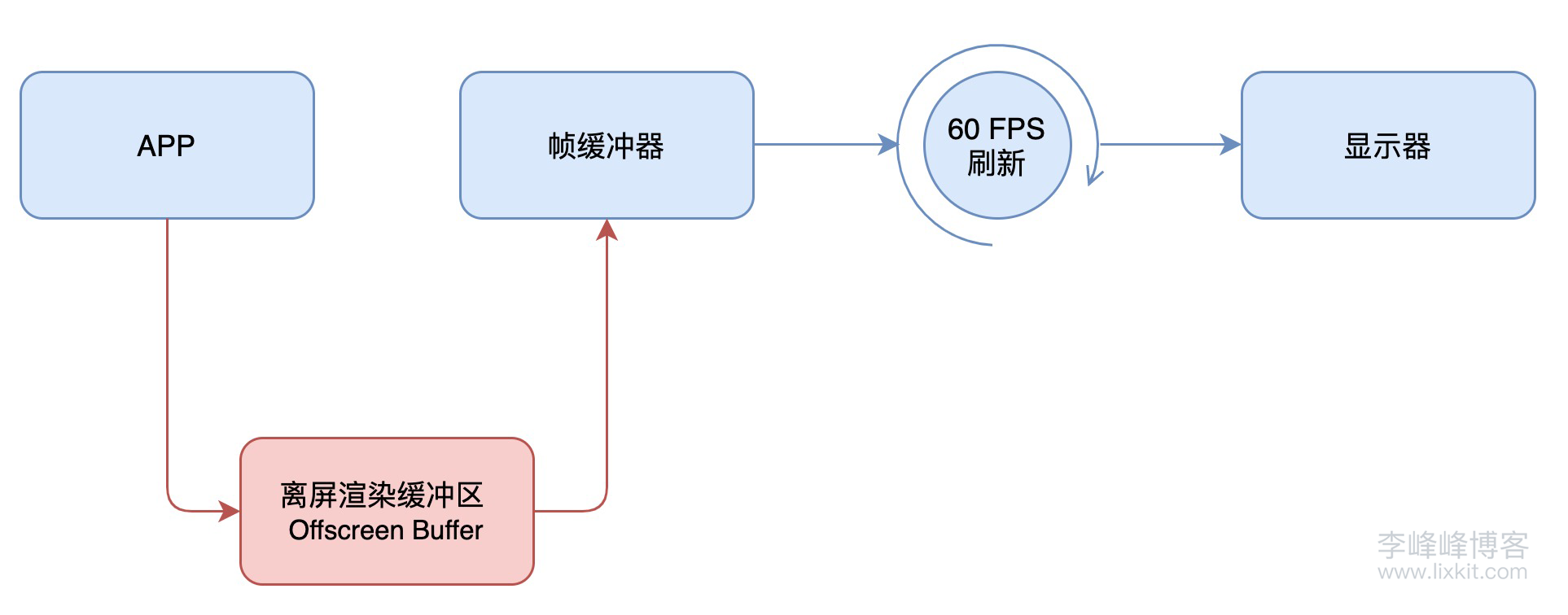
与普通情况下 GPU 直接将渲染好的内容放入 Framebuffer 中不同,需要先额外创建离屏渲染缓冲区 Offscreen Buffer,将提前渲染好的内容放入其中,等到合适的时机再将 Offscreen Buffer 中的内容进一步叠加、渲染,完成后将结果切换到 Framebuffer 中。
为什么会有离屏渲染呢?
使用离屏渲染主要是因为下面这两种原因:
- (1) 一些特殊效果需要使用额外的 Offscreen Buffer 来保存渲染的中间状态,所以不得不使用离屏渲染。
- (2) 处于效率目的,可以将内容提前渲染保存在 Offscreen Buffer 中,达到复用的目的。
对于第一种情况,也就是不得不使用离屏渲染的情况,一般都是系统自动触发的,比如阴影、圆角等等。
为什么需要使用额外的 Offscreen Buffer 来保存渲染的中间状态?通过前面的 Core Animation 渲染流水线可以知道,主要渲染操作是由 Render Server 模块通过调用显卡驱动所提供的 Metal/OpenGL 接口来执行的,通常对于每一层 layer,Render Server 会遵循“画家算法”,按次序输出到 frame buffer,后一层覆盖前一层,就能得到最终的显示结果:
作为“画家”的 GPU 虽然可以一层一层往画布上进行输出,但是无法在某一层渲染完成之后,再回过头来擦除/改变其中的某个部分,因为目前存在的 layer 已经是若干层 layer 覆盖合并后的 layer 了。所以,对于这种复杂的场景,就不得不另开一块内存,也就是创建一个缓冲区(Offscreen Buffer),将已渲染好的 layer 先临时保存到这个缓冲区中,以便于可以多次取出做出一些特定处理。
例如,使用了 mask 蒙版:
1 | UIImageView *mImageView = [UIImageView new]; |
由于最终的内容是由两层渲染结果叠加,所以必须要利用额外的内存空间对中间的渲染结果进行保存,因此系统会默认触发离屏渲染。
再例如,使用了 iOS 8+ 提供的模糊效果 UIBlurEffectView:
1 | UIImageView *mImageView = [[UIImageView alloc] init]; |
整个模糊过程分为多步:Pass 1 先渲染需要模糊的内容本身,Pass 2 对内容进行缩放,Pass 3 4 分别对上一步内容进行横纵方向的模糊操作,最后一步用模糊后的结果叠加合成,最终实现完整的模糊特效。
而第二种情况,为了复用提高效率而使用离屏渲染一般是主动的行为,是通过 CALayer 的 shouldRasterize 光栅化操作实现的。
开启光栅化后,会触发离屏渲染,Render Server 会强制将 CALayer 的渲染位图结果 bitmap 保存下来,这样下次再需要渲染时就可以直接复用,从而提高效率。
而保存的 bitmap 包含 layer 的 subLayer、圆角、阴影、组透明度 group opacity 等,所以如果 layer 的构成包含上述几种元素,结构复杂且需要反复利用,那么就可以考虑打开光栅化,以改善性能。
圆角、阴影、组透明度等会由系统自动触发离屏渲染,那么打开光栅化可以节约第二次及以后的渲染时间。而多层 subLayer 的情况由于不会自动触发离屏渲染,所以相比之下会多花费第一次离屏渲染的时间,但是可以节约后续的重复渲染的开销。
例如,UITableView 的 cell 中,如果使用了阴影效果,那么会触发离屏渲染:
1 | // ... |
我们可以使用 shouldRasterize 来缓存图层内容。这将会让图层离屏渲染一次之后把结果保存起来,大大减少了 GPU 的负担:
1 | - (UITableViewCell *)tableView:(UITableView *)tableView cellForRowAtIndexPath:(NSIndexPath *)indexPath |
不过使用光栅化的时候需要注意以下几点:
- 如果
layer不能被复用,则没有必要打开光栅化 - 如果
layer不是静态,需要被频繁修改,比如处于动画之中,那么开启离屏渲染反而影响效率 - 离屏渲染缓存内容有时间限制,缓存内容 100ms 内如果没有被使用,那么就会被丢弃,无法进行复用
- 离屏渲染缓存空间有限,超过 2.5 倍屏幕像素大小的话也会失效,无法复用。
离屏渲染的代价是很高的,主要体现在两个方面:
创建新缓冲区(Offscreen Buffer)
要想进行离屏渲染,首先要创建一个新的缓冲区,缓冲区需求占有一定的内存空间,大量的离屏渲染可能造成内存的过大压力。与此同时,Offscreen Buffer 的总大小也有限,不能超过屏幕总像素的 2.5 倍。上下文切换
离屏渲染的整个过程,需要多次切换上下文环境:先是从当前屏幕(On-Screen)切换到离屏(Off-Screen),等到离屏渲染结束以后,将离屏缓冲区的渲染结果显示到屏幕上有需要将上下文环境从离屏切换到当前屏幕。而上下文环境的切换是要付出很大代价的。
离屏渲染的开销非常大,一旦需要离屏渲染的内容过多,很容易造成掉帧的问题。所以大部分情况下,我们都应该尽量避免离屏渲染。
除了前面提到的几个触发离屏渲染的案例,还有很多情况也会触发离屏渲染。
总结一下,会触发离屏渲染的情况如下:
- 使用了
mask的layer(layer.mask) layer切圆角 (layer.masksToBounds/layer.masksToBounds),单纯的cornerRadius+masksToBounds不会触发离屏渲染,以下情况时才会触发离屏渲染:layer设置了圆角裁剪,且有子layer,或者有content,会触发离屏渲染。UIImageView设置了圆角裁剪,同时设置了backgroundColor和image(属于两个图层),会触发离屏渲染。UIButton设置了圆角裁剪,且设置了backgroundImage或者image+backgroundColor,会触发离屏渲染。
- 有子
layer或者背景图的layer设置了组透明度为 YES(默认就是 YES),并且设置了透明度不为 1 (layer.allowsGroupOpacity/layer.opacity) - 添加了投影的
layer(layer.shadow*) - 采用了光栅化的
layer(layer.shouldRasterize) - 绘制了文字的
layer(UILabel,CATextLayer,Core Text等)
特殊的“离屏渲染”:CPU渲染
在前面渲染流程中提到如果我们重写了 drawRect: 方法,就涉及到了 CPU 渲染。整个渲染过程由 CPU 在 App 内同步地完成,渲染得到的 bitmap(位图)最后再交由 GPU 用于显示。
Designing for iOS: Graphics & Performance 这篇文章也提到了使用 Core Graphics API 会触发离屏渲染。 苹果 iOS 4.1-8 时期的 UIKit 组成员 Andy Matuschak 也曾对这个说法进行解释:「Core Graphics 的绘制 API 的确会触发离屏渲染,但不是那种 GPU 的离屏渲染。使用 Core Graphics 绘制 API 是在 CPU 上执行,触发的是 CPU 版本的离屏渲染。」
优化建议:
(1)对于圆角,可使用贝塞尔曲线 UIBezierPath 和 CoreGraphics 的替代方式画圆角避免离屏渲染。例如:
1 | UIImageView *imageView = [[UIImageView alloc]initWithFrame:CGRectMake(100, 100, 100, 100)]; |
(2)对于 layer 透明度不为 1 的情况,可以设置 allowsGroupOpacity 为 NO 避免离屏渲染。iOS 7+ 系统 allowsGroupOpacity 默认为 YES,例如:
1 | view.layer.allowsGroupOpacity = NO |
备注:allowsGroupOpacity 作用
红色的是父 View,蓝色是子 View,效果如下:
子 View 不设置透明度,对父 View 设置半透明:
1 | parentView.layer.opacity = 0.5; |
allowsGroupOpacity 为 YES(默认) 效果:
allowsGroupOpacity 为 NO 效果:
可以看到,如果 allowsGroupOpacity 为 YES,这是对图层整体设置透明度,相当于先合并图层,再设置透明度。如果 allowsGroupOpacity 为 NO,则是分别对图层设置透明度,于是就出现了子 View 半透明后能看到后面的父 View 的效果。
(3)对于 layer 设置阴影情况,可以通过设置 shadowPath 的替代方式设置阴影避免离屏渲染。例如:
1 | // 1. 设置 shadow ,会产生离屏渲染。 |
检测离屏渲染
启动模拟器并打开如下选项,页面黄色区域部门表示发生了离屏渲染: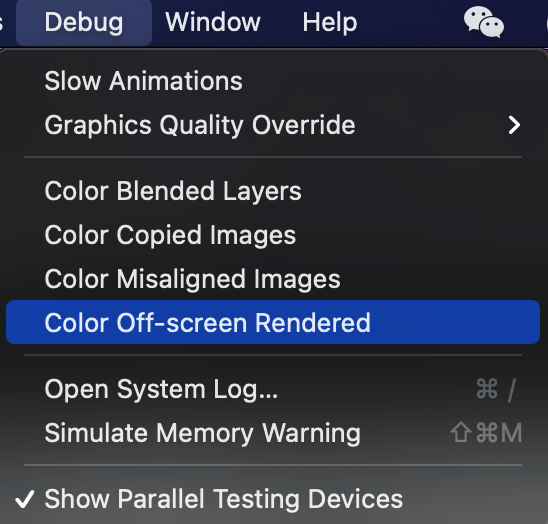
三、卡顿
1、卡顿原因
前面图像渲染原理部分提到 iOS 使用“垂直同步 Vsync + 双缓冲机制 Double Buffering”机制避免了屏幕撕裂问题。但是,这种方式也引起了另个问题:掉帧
在 VSync 信号到来后,系统图形服务会通过 CADisplayLink 等机制通知 App,App 主线程开始在 CPU 中计算显示内容,比如视图的创建、布局计算、图片解码、文本绘制等。随后 CPU 会将计算好的内容提交到 GPU 去,由 GPU 进行变换、合成、渲染。随后 GPU 会把渲染结果提交到帧缓冲区去,等待下一次 VSync 信号到来时显示到屏幕上。如果在接收到 Vsync 之时 CPU 和 GPU 还没有渲染好新的位图,视频控制器就不会去替换 frame buffer 中的位图。这时屏幕就会重新扫描呈现出上一帧一模一样的画面。相当于两个周期显示了同样的画面,引起了掉帧的现象,这就是界面卡顿的原因。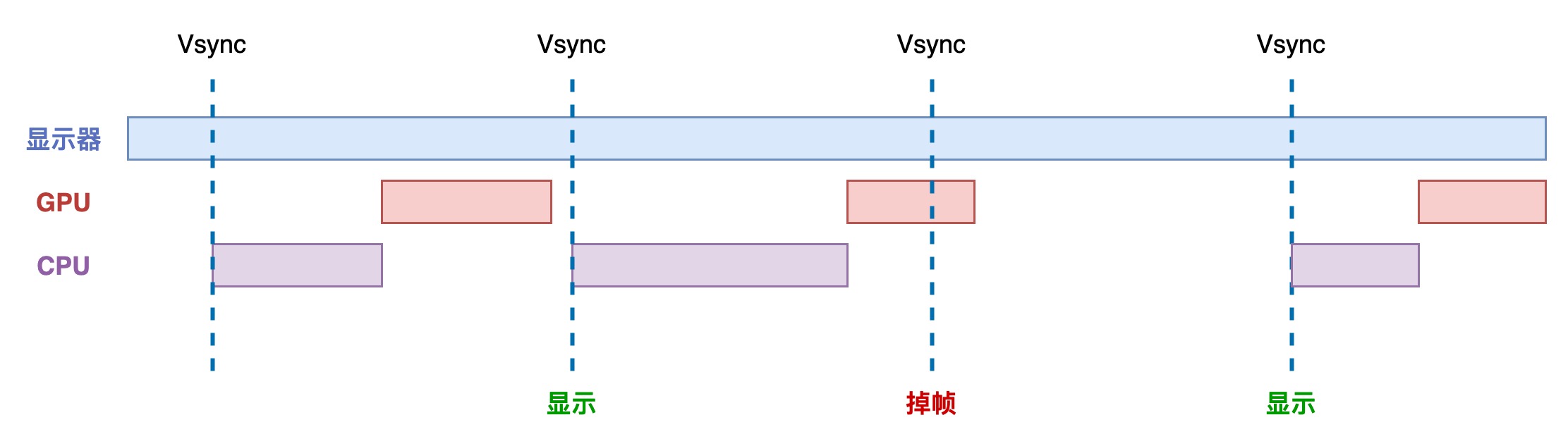
从上面的图中可以看到,CPU 和 GPU 不论哪个阻碍了显示流程,都会造成掉帧现象。所以开发时,也需要分别对 CPU 和 GPU 压力进行评估和优化。
2、解决卡顿
针对 CPU 资源消耗方面的优化:
- (1)对象的创建和销毁是比较消耗 CPU 资源的,所以应当减少 UIView 的创建,尽量复用 UIView
- (2)尽量使用轻量级对象,例如使用 CALayer 能满足需求的话,尽量使用 CALayer
- (3)如果任务不涉及到 UI 操作,尽量放到后台线程处理
- (4)尽量避免调整视图层次、添加和移除视图
- (5)避免频繁调整 frame/bounds/center 等属性
- (6)如果使用了 CoreGraphic 相关 API 进行绘制,尽量异步绘制(前面有提到异步绘制实现方式)
针对 GUP 资源消耗方面的优化:
- (1)当多个视图(或者说 CALayer)重叠在一起显示时,GPU 会首先把他们混合到一起。如果视图结构过于复杂,混合的过程也会消耗很多 GPU 资源,所以应当尽量减少视图数量和层次
- (2)GPU 能处理的最大纹理尺寸是 4096x4096,一旦超过这个尺寸,就会占用 CPU 资源进行处理,所以纹理尽量不要超过这个尺寸
- (3)减少透明的视图(alpha<1),不透明的就设置 opaque 为 YES,避免无用的 Alpha 通道合成。
- (4)避免离屏渲染
3、监听卡顿
(1) 利用 Runloop 监控卡顿
根据 Runloop 的执行流程可以发现,Runloop 对我们业务逻辑的处理时间在两个阶段:
kCFRunLoopBeforeSources和kCFRunLoopBeforeWaiting之间kCFRunLoopAfterWaiting之后
所以,如果主线程 Runloop 处在 kCFRunLoopBeforeSources 时间过长,也就是迟迟无法将任务处理完成,顺利到达 kCFRunLoopBeforeWaiting 阶段,说明发生了卡顿。
同样的,如果 Runloop 处在 kCFRunLoopAfterWaiting 时间过长,也是发生了卡顿。
所以,如果我们要利用 Runloop 来监控卡顿的话,就要关注 kCFRunLoopBeforeSources 和 kCFRunLoopAfterWaiting 两个阶段,一般卡顿时间超过 250ms 会被明显感知,所以,可以以连续 5 次卡顿时长超过 50ms 可以认为发生卡顿,或者根据需要调整统计阀值。以下是通过 Runloop 监听卡顿的一个例子:
1 | @interface LagMonitor() { |
(2) 子线程 ping 监控卡顿
子线程定时给主线程发送 ping 消息,主线程收到消息后回复 pong 消息,如果隔了太久才回复消息,可以说明主线程发生了卡顿。
其中一种实现方式是在子线程进行加锁,让主线程去解锁,如果主线程没有卡顿就能很快解锁。但是如果主线程在一定时间阀值内(例如 150 ms)还没有解锁,也就是加锁到解锁这段时间间隔大于阀值,就代表产生了卡顿,例如:
1 | // 自定义的子线程 PingThread |
当然这只是其中一种实现方式,除此之外还可以利用信号量、发通知等各种实现方式,但是思想是一样的。
(3) 使用 CADisplayLink 监测 FPS
通常情况下,屏幕会保持 60hz/s 的刷新率,每次刷新时会发出一个屏幕刷新信,通过 CADisplayLink 可以注册一个与刷新信号同步的回调处理。可以通过屏幕刷新机制来展示 FPS 值,如果没有达到 60hz/s 可以认为发生了卡顿。例如:
1 | @implemention ViewController { |
上面代码逻辑只是通过一个 UILable 去显示当前帧率,如果有需要,可以在帧率小于 60 fps 时上报主线程堆栈。
参考:
Advanced Graphics and Animations for iOS Apps
iOS Rendering 渲染全解析
iOS 保持界面流畅的技巧
iOS 的图形绘制原理
-

- 本文章采用 知识共享署名 4.0 国际许可协议 进行许可,完整转载、部分转载、图片转载时均请注明原文链接。