一、概述 dispatch_sync 用于将一个任务同步地提交到指定的调度队列,并等待该任务完成后才返回。调用者线程会被阻塞,直到任务执行完毕。dispatch_sync 在需要确保任务在某个队列上按顺序执行,前一个任务完成之前,后续任务不会执行。
dispatch_sync 特点:
不会开启新线程
dispatch_sync 在调用时,不会创建新的线程来执行任务。它会在指定的队列上同步地执行任务。
按照顺序执行
串行队列
在串行队列上,dispatch_sync 提交的任务会按照队列中的顺序依次执行,确保任务之间的顺序性。
并发队列
同一个线程使用 dispatch_sync 往并发队列提交任务,任务会按照提交顺序执行,因为每个调用会阻塞调用线程,直到当前任务完成。
不同线程使用 dispatch_sync 往同一并发队列提交任务,任务的执行顺序是不可预测的,因为并发队列会并行处理任务,具体顺序取决于系统调度。
使用示例:
1 2 3 4 dispatch_queue_t queue = dispatch_queue_create("com.lixkit.serialQueue" , DISPATCH_QUEUE_SERIAL);dispatch_sync (queue, ^{ });
二、dispatch_sync dispatch_sync 函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 void dispatch_sync (dispatch_queue_t dq, dispatch_block_t work) { uintptr_t dc_flags = DC_FLAG_BLOCK; if (unlikely(_dispatch_block_has_private_data(work))) { return _dispatch_sync_block_with_privdata(dq, work, dc_flags); } _dispatch_sync_f(dq, work, _dispatch_Block_invoke(work), dc_flags); }
上述逻辑中,先判断传入的 block 是否包含私有数据,当我们通过前面的示例方式调用 dispatch_sync,传入的 block 是不包含私有数据的。当传入的 block 是通过下面方式创建的时候,block 中才会包含私有数据:
1 2 3 dispatch_block_t block = dispatch_block_create(0 , ^{ });
dispatch_block_create 用于创建一个带有附加控制信息的 Block,这些附加信息可以包括优先级、屏障标志、凭证等。例如,dispatch_block_create 的第 1 个参数传 DISPATCH_BLOCK_BARRIER,可以创建一个屏障 Block。在并发队列中,屏障 Block 可以确保在其前面的任务完成后才开始执行,并在其后面的任务开始之前完成。例如:
1 2 3 4 5 6 7 8 9 dispatch_block_t block = dispatch_block_create(DISPATCH_BLOCK_BARRIER, ^{ }); dispatch_async (queue, block);dispatch_block_cancel(block);
关于 dispatch_block_create 不是本次源码分析的重点,这里不再深究。也就是说,我们常规使用 dispatch_sync 执行串行、并发队列时,实际会调用 _dispatch_sync_f 函数。
三、_dispatch_sync_f _dispatch_sync_f 函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 static void _dispatch_sync_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func, uintptr_t dc_flags) { _dispatch_sync_f_inline(dq, ctxt, func, dc_flags); } static inline void _dispatch_sync_f_inline(dispatch_queue_t dq, void *ctxt, dispatch_function_t func, uintptr_t dc_flags) { if (likely(dq->dq_width == 1 )) { return _dispatch_barrier_sync_f(dq, ctxt, func, dc_flags); } if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) { DISPATCH_CLIENT_CRASH(0 , "Queue type doesn't support dispatch_sync" ); } dispatch_lane_t dl = upcast(dq)._dl; if (unlikely(!_dispatch_queue_try_reserve_sync_width(dl))) { return _dispatch_sync_f_slow(dl, ctxt, func, 0 , dl, dc_flags); } if (unlikely(dq->do_targetq->do_targetq)) { return _dispatch_sync_recurse(dl, ctxt, func, dc_flags); } _dispatch_introspection_sync_begin(dl); _dispatch_sync_invoke_and_complete(dl, ctxt, func DISPATCH_TRACE_ARG( _dispatch_trace_item_sync_push_pop(dq, ctxt, func, dc_flags))); }
这里需要分成两部分看:串行队列执行逻辑、并发队列执行逻辑。
在前面分析 dispatch_queue_create 的源码时候就已经知道:
创建串行队列时,dq_width = 1
创建并发队列时,dq_width = 4094
所以对于串行队列,会进入 _dispatch_barrier_sync_f 函数的执行逻辑,并发队列走剩余的逻辑。
四、_dispatch_barrier_sync_f 根据前面源码可知,对于串行队列,会通过 likely(dq->dq_width == 1) 的判断,进入 _dispatch_barrier_sync_f 函数的执行逻辑。
_dispatch_barrier_sync_f 函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 static void _dispatch_barrier_sync_f(dispatch_queue_t dq, void *ctxt, dispatch_function_t func, uintptr_t dc_flags) { _dispatch_barrier_sync_f_inline(dq, ctxt, func, dc_flags); } static inline void _dispatch_barrier_sync_f_inline(dispatch_queue_t dq, void *ctxt, dispatch_function_t func, uintptr_t dc_flags) { dispatch_tid tid = _dispatch_tid_self(); if (unlikely(dx_metatype(dq) != _DISPATCH_LANE_TYPE)) { DISPATCH_CLIENT_CRASH(0 , "Queue type doesn't support dispatch_sync" ); } dispatch_lane_t dl = upcast(dq)._dl; if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dl, tid))) { return _dispatch_sync_f_slow(dl, ctxt, func, DC_FLAG_BARRIER, dl, DC_FLAG_BARRIER | dc_flags); } if (unlikely(dl->do_targetq->do_targetq)) { return _dispatch_sync_recurse(dl, ctxt, func, DC_FLAG_BARRIER | dc_flags); } _dispatch_introspection_sync_begin(dl); _dispatch_lane_barrier_sync_invoke_and_complete(dl, ctxt, func DISPATCH_TRACE_ARG(_dispatch_trace_item_sync_push_pop( dq, ctxt, func, dc_flags | DC_FLAG_BARRIER))); }
上述核心逻辑如下:
获取屏障锁
屏障锁用于确保在执行任务时,队列中的其他任务不会同时执行。
获取屏障锁成功:意味着当前队列空闲,可以执行任务。
获取屏障锁失败:意味着当前队列非空闲,正在执行其他任务。
此时会执行 _dispatch_sync_f_slow 函数。
递归目标队列(如果有必要) 执行任务,并重置 dq_state、唤醒线程
接下来,通过源码详细看下各部分逻辑。
1、获取屏障锁 获取屏障锁逻辑如下:
1 2 3 4 5 6 if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dl, tid))) { return _dispatch_sync_f_slow(dl, ctxt, func, DC_FLAG_BARRIER, dl, DC_FLAG_BARRIER | dc_flags); }
获取屏障锁调用的是 _dispatch_queue_try_acquire_barrier_sync 函数:
1 2 3 4 5 static inline bool _dispatch_queue_try_acquire_barrier_sync(dispatch_queue_class_t dq, uint32_t tid) { return _dispatch_queue_try_acquire_barrier_sync_and_suspend(dq._dl, tid, 0 ); }
其内部调用的 _dispatch_queue_try_acquire_barrier_sync_and_suspend 函数,内部涉及到一系列宏定义,将该函数完全展开后逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 static inline bool _dispatch_queue_try_acquire_barrier_sync_and_suspend(dispatch_lane_t dq, uint32_t tid, uint64_t suspend_count) { uint64_t init = DISPATCH_QUEUE_STATE_INIT_VALUE(dq->dq_width); uint64_t value = DISPATCH_QUEUE_WIDTH_FULL_BIT | DISPATCH_QUEUE_IN_BARRIER | _dispatch_lock_value_from_tid(tid) | DISPATCH_QUEUE_UNCONTENDED_SYNC | (suspend_count * DISPATCH_QUEUE_SUSPEND_INTERVAL); uint64_t old_state, new_state; bool _result = false ; __typeof__(&(dq)->dq_state) _p = &(dq)->dq_state; old_state = os_atomic_load(_p, relaxed); do { uint64_t role = old_state & DISPATCH_QUEUE_ROLE_MASK; if (old_state != (init | role)) { os_atomic_rmw_loop_give_up(break ); } new_state = value | role; _result = os_atomic_cmpxchgvw(_p, old_state, new_state, &old_state, acquire); } while (unlikely(!_result)); return _result; }
从上述逻辑可知,是利用 dq_state 实现获取屏障锁逻辑,在上一篇 dispatch_queue 源码分析的文章里,已经知道串行队列:
1 2 dq_state = (DISPATCH_QUEUE_STATE_INIT_VALUE(dq_width) | DISPATCH_QUEUE_ROLE_BASE_WLH) = 0x001ffe2000000000 ;
所以首次执行 _dispatch_queue_try_acquire_barrier_sync_and_suspend 函数时,一定满足下面条件:
1 old_state == (init | role)
所以会继续执行 dq_state 的赋值逻辑:
1 new_state = value | role;
赋值完成后,_result 值为 true,并且 _dispatch_queue_try_acquire_barrier_sync_and_suspend 函数返回 true,获取屏障锁成功。
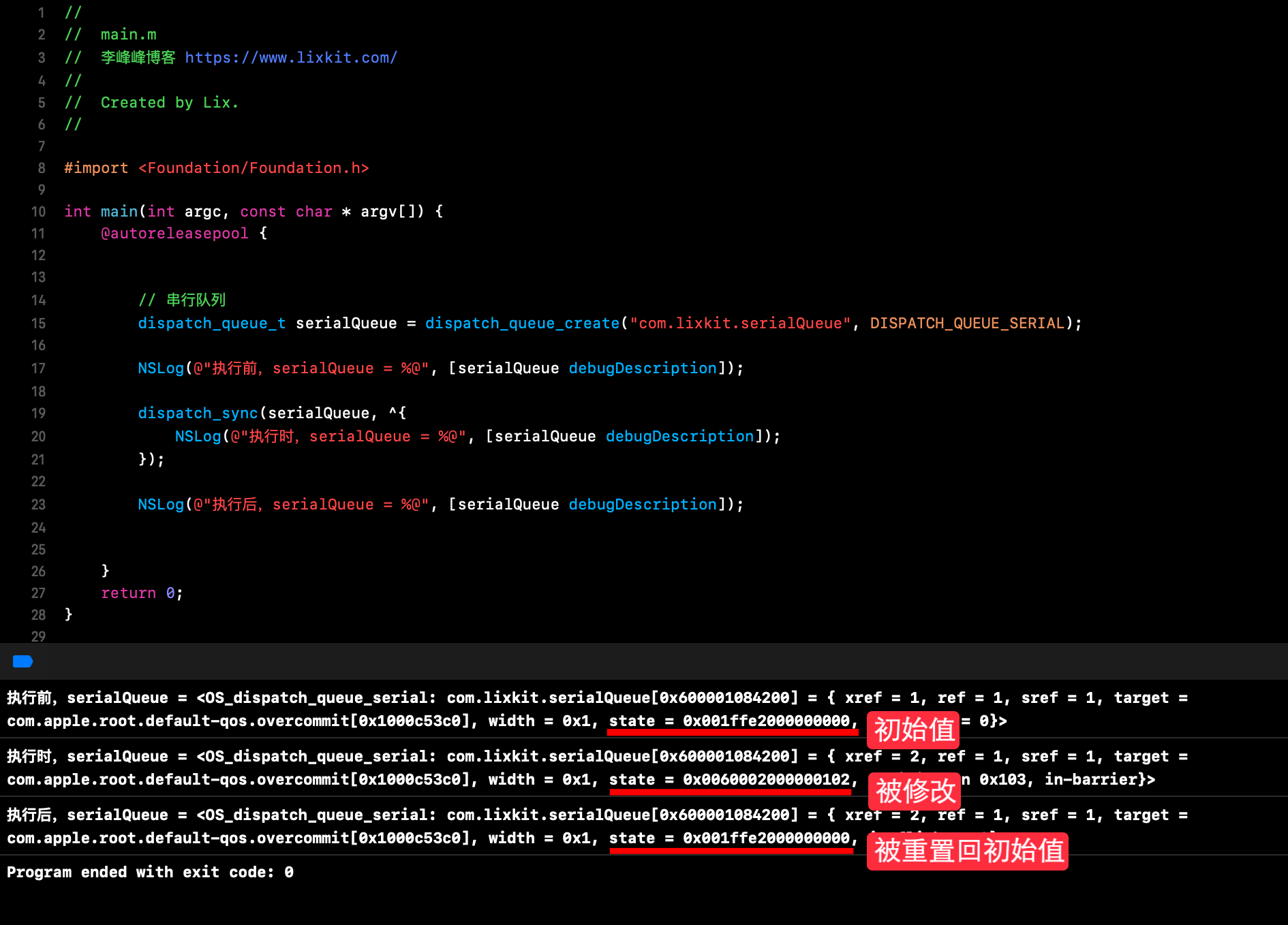
这里,我们可以通过一个 Demo 验证下这部分逻辑:
根据上述 Demo 打印结果也可以看出利用 dq_state 实现获取屏障锁逻辑:
dq_state 初始值满足 dq_state == (init | role),允许获取屏障锁。获取屏障锁后,dq_state 被修改(dq_state = value | role),dq_state 不再满 dq_state == (init | role),后续提交的任务将无法再获取屏障锁。
任务执行结束后,dq_state 会重置回初始值,下个任务可以获取屏障锁。
2、递归目标队列 上一步屏障锁如果获取成功,则会继续执行递归目标队列的逻辑,该逻辑如下:
1 2 3 4 5 6 if (unlikely(dl->do_targetq->do_targetq)) { return _dispatch_sync_recurse(dl, ctxt, func, DC_FLAG_BARRIER | dc_flags); }
上述主要逻辑是检查 do_targetq 是否也存在 do_targetq,如果存在,则需要递归队列。
那么,什么情况下 do_targetq 也存在 do_targetq 呢?
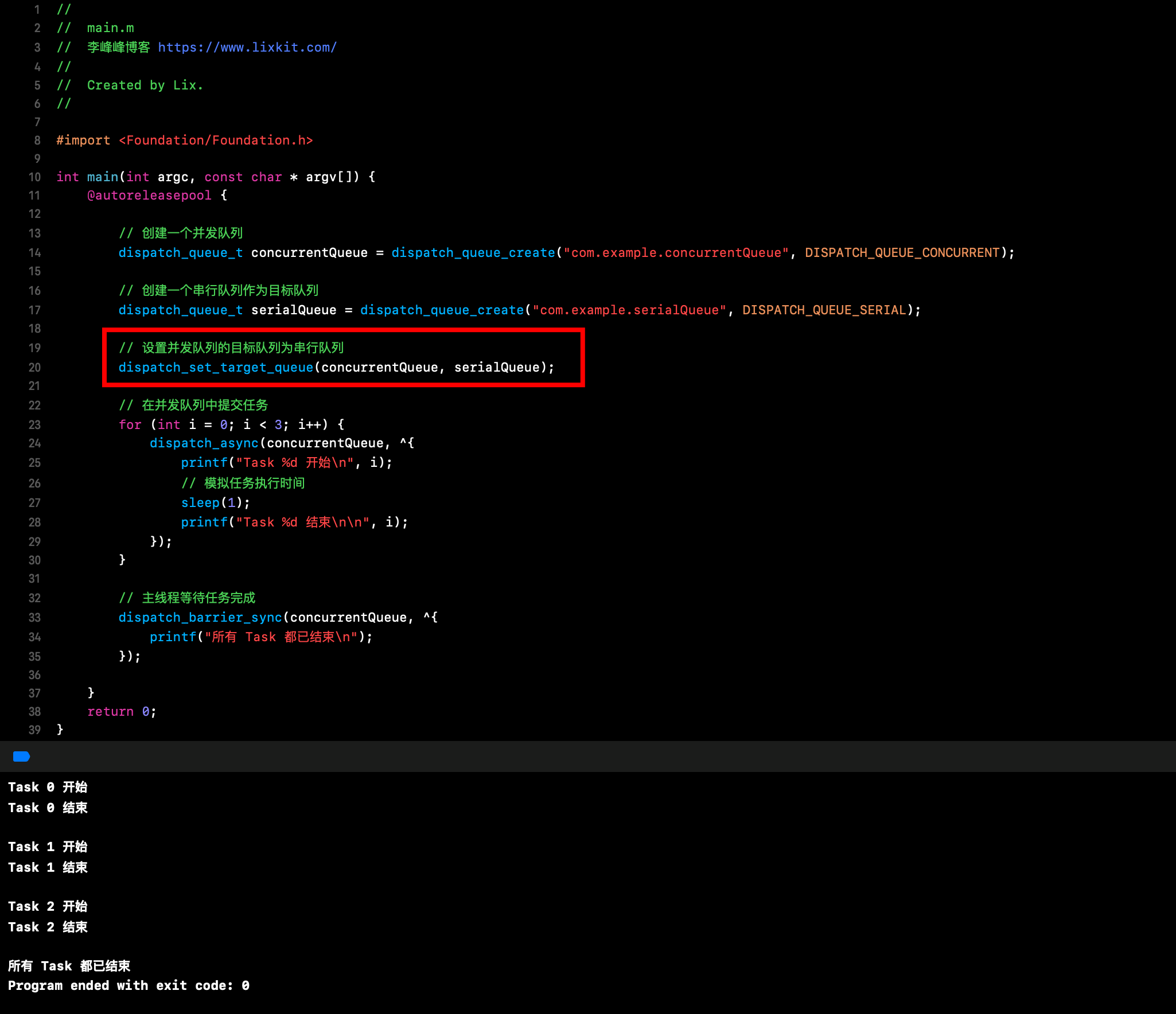
比较常见的一个场景是利用 dispatch_set_target_queue 函数设置目标队列,dispatch_set_target_queue 的主要目的是将一个 queue 的任务调度到另一个 queue。当你设置一个 queue 的目标 queue 后,原 queue 中的任务将在目标 queue 中执行,这样可以确保任务的优先级和调度策略与目标 queue 一致。
dispatch_set_target_queue 使用示例如下:dispatch_async 提交到 concurrentQueue 队列上的,由于设置了 concurrentQueue 的目标队列是 serialQueue,所以任务会在 serialQueue 上执行,最终任务串行执行。
这里调用 _dispatch_sync_recurse 函数内部与后续正常执行任务的逻辑基本一致,这里就不再单独分析。
3、执行任务,并重置 dq_state、唤醒线程 在上一步获取屏障锁成功后,最终会执行 _dispatch_lane_barrier_sync_invoke_and_complete 函数执行任务并重置 dq_state:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 static void _dispatch_lane_barrier_sync_invoke_and_complete(dispatch_lane_t dq, void *ctxt, dispatch_function_t func DISPATCH_TRACE_ARG(void *dc)) { _dispatch_sync_function_invoke_inline(dq, ctxt, func); _dispatch_trace_item_complete(dc); if (unlikely(dq->dq_items_tail || dq->dq_width > 1 )) { return _dispatch_lane_barrier_complete(dq, 0 , 0 ); } const uint64_t fail_unlock_mask = DISPATCH_QUEUE_SUSPEND_BITS_MASK | DISPATCH_QUEUE_ENQUEUED | DISPATCH_QUEUE_DIRTY | DISPATCH_QUEUE_RECEIVED_OVERRIDE | DISPATCH_QUEUE_RECEIVED_SYNC_WAIT; uint64_t old_state, new_state; dispatch_wakeup_flags_t flags = 0 ; os_atomic_rmw_loop2o(dq, dq_state, old_state, new_state, release, { new_state = old_state - DISPATCH_QUEUE_SERIAL_DRAIN_OWNED; new_state &= ~DISPATCH_QUEUE_DRAIN_UNLOCK_MASK; new_state &= ~DISPATCH_QUEUE_MAX_QOS_MASK; if (unlikely(old_state & fail_unlock_mask)) { os_atomic_rmw_loop_give_up({ return _dispatch_lane_barrier_complete(dq, 0 , flags); }); } }); if (_dq_state_is_base_wlh(old_state)) { _dispatch_event_loop_assert_not_owned((dispatch_wlh_t )dq); } }
执行任务调用的是 _dispatch_sync_function_invoke_inline 函数:
1 2 3 4 5 6 7 8 9 10 11 static inline void _dispatch_sync_function_invoke_inline(dispatch_queue_class_t dq, void *ctxt, dispatch_function_t func) { dispatch_thread_frame_s dtf; _dispatch_thread_frame_push(&dtf, dq); _dispatch_client_callout(ctxt, func); _dispatch_perfmon_workitem_inc(); _dispatch_thread_frame_pop(&dtf); }
上述执行任务主要是通过执行 _dispatch_client_callout 函数,关于 _dispatch_client_callout 函数,在另一篇文章《GCD 底层原理 1 - dispatch_once》 中有总结,其核心逻辑就是执行具体任务。
_dispatch_sync_function_invoke_inline 中其他的逻辑是线程调度相关,这部分不是本次分析重点,暂时忽略这部分逻辑。
_dispatch_lane_barrier_sync_invoke_and_complete 除了任务的执行外,还有这两部分逻辑:
重置 dq_state
前面已经提到,任务执行完成后,会重置 dq_state,使后续往队列新提交的任务可以成功获取屏障锁。
唤醒线程
如果 dispatch_sync 往串行队列中提交的任务还没有执行完成,再次使用 dispatch_sync 往相同队列提交新任务时,会获取屏障锁失败走 _dispatch_sync_f_slow 的逻辑,_dispatch_sync_f_slow 中会使线程阻塞等待上个任务的完成。当上个任务执行完成后,会唤醒阻塞的线程继续执行任务。
在分析唤醒线程的逻辑前,我们先分析下 _dispatch_sync_f_slow 中阻塞线程的逻辑。
五、_dispatch_sync_f_slow 在前面获取屏障锁失败后,会执行 _dispatch_sync_f_slow 函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 static void _dispatch_sync_f_slow(dispatch_queue_class_t top_dqu, void *ctxt, dispatch_function_t func, uintptr_t top_dc_flags, dispatch_queue_class_t dqu, uintptr_t dc_flags) { dispatch_queue_t top_dq = top_dqu._dq; dispatch_queue_t dq = dqu._dq; if (unlikely(!dq->do_targetq)) { return _dispatch_sync_function_invoke(dq, ctxt, func); } pthread_priority_t pp = _dispatch_get_priority(); struct dispatch_sync_context_s dsc = .dc_flags = DC_FLAG_SYNC_WAITER | dc_flags, .dc_func = _dispatch_async_and_wait_invoke, .dc_ctxt = &dsc, .dc_other = top_dq, .dc_priority = pp | _PTHREAD_PRIORITY_ENFORCE_FLAG, .dc_voucher = _voucher_get(), .dsc_func = func, .dsc_ctxt = ctxt, .dsc_waiter = _dispatch_tid_self(), }; _dispatch_trace_item_push(top_dq, &dsc); __DISPATCH_WAIT_FOR_QUEUE__(&dsc, dq); if (dsc.dsc_func == NULL ) { dispatch_queue_t stop_dq = dsc.dc_other; return _dispatch_sync_complete_recurse(top_dq, stop_dq, top_dc_flags); } _dispatch_introspection_sync_begin(top_dq); _dispatch_trace_item_pop(top_dq, &dsc); _dispatch_sync_invoke_and_complete_recurse(top_dq, ctxt, func, top_dc_flags DISPATCH_TRACE_ARG(&dsc)); }
该函数核心逻辑如下:
阻塞线程,等待上个任务执行结束
执行 __DISPATCH_WAIT_FOR_QUEUE__ 函数
解除阻塞后,执行当前任务,并重置 dq_state、唤醒线程
执行 _dispatch_sync_invoke_and_complete_recurse 函数
1、阻塞线程 _dispatch_sync_f_slow 中,阻塞线程是通过调用 __DISPATCH_WAIT_FOR_QUEUE__ 函数实现的,该函数源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 static void __DISPATCH_WAIT_FOR_QUEUE__(dispatch_sync_context_t dsc, dispatch_queue_t dq) { uint64_t dq_state = _dispatch_wait_prepare(dq); if (unlikely(_dq_state_drain_locked_by(dq_state, dsc->dsc_waiter))) { DISPATCH_CLIENT_CRASH((uintptr_t )dq_state, "dispatch_sync called on queue " "already owned by current thread" ); } _dispatch_thread_frame_save_state(&dsc->dsc_dtf); if (_dq_state_is_suspended(dq_state) || _dq_state_is_base_anon(dq_state)) { dsc->dc_data = DISPATCH_WLH_ANON; } else if (_dq_state_is_base_wlh(dq_state)) { dsc->dc_data = (dispatch_wlh_t )dq; } else { _dispatch_wait_compute_wlh(upcast(dq)._dl, dsc); } if (dsc->dc_data == DISPATCH_WLH_ANON) { dsc->dsc_override_qos_floor = dsc->dsc_override_qos = (uint8_t )_dispatch_get_basepri_override_qos_floor(); _dispatch_thread_event_init(&dsc->dsc_event); } _dispatch_set_current_dsc((void *) dsc); dx_push(dq, dsc, _dispatch_qos_from_pp(dsc->dc_priority)); _dispatch_trace_runtime_event(sync_wait, dq, 0 ); if (dsc->dc_data == DISPATCH_WLH_ANON) { _dispatch_thread_event_wait(&dsc->dsc_event); } else if (!dsc->dsc_wlh_self_wakeup) { _dispatch_event_loop_wait_for_ownership(dsc); } _dispatch_clear_current_dsc(); if (dsc->dc_data == DISPATCH_WLH_ANON) { _dispatch_thread_event_destroy(&dsc->dsc_event); if (dsc->dsc_override_qos > dsc->dsc_override_qos_floor) { _dispatch_set_basepri_override_qos(dsc->dsc_override_qos); } } }
上述逻辑中,先看这个判断:
1 2 3 4 5 6 7 8 if (_dq_state_is_suspended(dq_state) || _dq_state_is_base_anon(dq_state)) { dsc->dc_data = DISPATCH_WLH_ANON; } else if (_dq_state_is_base_wlh(dq_state)) { dsc->dc_data = (dispatch_wlh_t )dq; } else { _dispatch_wait_compute_wlh(upcast(dq)._dl, dsc); }
上述判断条件涉及的函数源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 static inline bool _dq_state_is_suspended(uint64_t dq_state) { return dq_state & DISPATCH_QUEUE_SUSPEND_BITS_MASK; } static inline bool _dq_state_is_base_anon(uint64_t dq_state) { return dq_state & DISPATCH_QUEUE_ROLE_BASE_ANON; } static inline bool _dq_state_is_base_wlh(uint64_t dq_state) { return dq_state & DISPATCH_QUEUE_ROLE_BASE_WLH; }
根据前面的源码分析可以知道,dq_state 是不包含 DISPATCH_QUEUE_SUSPEND_BITS_MASK 信息的,所以 _dq_state_is_suspended 的判断返回 false。
再根据另一篇文章 《GCD 底层原理 2 - dispatch_queue》 中分析得到的结论:
串行队列,role = DISPATCH_QUEUE_ROLE_BASE_WLH;
并发队列时,role = DISPATCH_QUEUE_ROLE_BASE_ANON;
所以对于串行队列,会走进第二个 if 分支里。
所以对于后面的这个判断:
1 2 3 4 5 6 7 if (dsc->dc_data == DISPATCH_WLH_ANON) { _dispatch_thread_event_wait(&dsc->dsc_event); } else if (!dsc->dsc_wlh_self_wakeup) { _dispatch_event_loop_wait_for_ownership(dsc); }
将执行 _dispatch_event_loop_wait_for_ownership 函数实现阻塞逻辑,该函数的完整源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 void _dispatch_event_loop_wait_for_ownership(dispatch_sync_context_t dsc) {#if DISPATCH_USE_KEVENT_WORKLOOP dispatch_wlh_t wlh = dsc->dc_data; dispatch_kevent_s ke[2 ]; uint32_t kev_flags = KEVENT_FLAG_IMMEDIATE | KEVENT_FLAG_ERROR_EVENTS; uint64_t dq_state; int i, n = 0 ; dq_state = os_atomic_load2o((dispatch_queue_t )wlh, dq_state, relaxed); if (!_dq_state_drain_locked(dq_state) && _dq_state_is_enqueued_on_target(dq_state)) { _dispatch_kq_fill_workloop_event(&ke[n++], DISPATCH_WORKLOOP_ASYNC, wlh, dq_state); } else if (_dq_state_received_sync_wait(dq_state)) { _dispatch_kq_fill_workloop_sync_event(&ke[n++], DISPATCH_WORKLOOP_SYNC_DISCOVER, wlh, dq_state, _dq_state_drain_owner(dq_state)); } again: _dispatch_kq_fill_workloop_sync_event(&ke[n++], DISPATCH_WORKLOOP_SYNC_WAIT, wlh, dq_state, dsc->dsc_waiter); n = _dispatch_kq_poll(wlh, ke, n, ke, n, NULL , NULL , kev_flags); for (i = 0 ; i < n; i++) { long flags = 0 ; if (ke[i].fflags & NOTE_WL_SYNC_WAIT) { flags = DISPATCH_KEVENT_WORKLOOP_ALLOW_EINTR; } _dispatch_kevent_workloop_drain_error(&ke[i], flags); } if (n) { dispatch_assert(n == 1 && (ke[0 ].fflags & NOTE_WL_SYNC_WAIT)); _dispatch_kevent_wlh_debug("restarting" , &ke[0 ]); dq_state = ke[0 ].ext[EV_EXTIDX_WL_VALUE]; n = 0 ; goto again; } #endif if (dsc->dsc_waiter_needs_cancel) { _dispatch_event_loop_cancel_waiter(dsc); dsc->dsc_waiter_needs_cancel = false ; } if (dsc->dsc_release_storage) { _dispatch_queue_release_storage(dsc->dc_data); } }
根据源码逻辑中各个判断条件,去除执行不到的逻辑分支,仅保留核心逻辑,精简后的 _dispatch_event_loop_wait_for_ownership 函数逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void _dispatch_event_loop_wait_for_ownership(dispatch_sync_context_t dsc) { dispatch_kevent_s ke[2 ]; uint32_t kev_flags = KEVENT_FLAG_IMMEDIATE | KEVENT_FLAG_ERROR_EVENTS; again: _dispatch_kq_fill_workloop_sync_event(&ke[n++], DISPATCH_WORKLOOP_SYNC_WAIT, wlh, dq_state, dsc->dsc_waiter); n = _dispatch_kq_poll(wlh, ke, n, ke, n, NULL , NULL , kev_flags); if (n) { n = 0 ; goto again; } }
乍一看上去,线程的阻塞是通过不停的 goto again 实现的,其实不然。先进去看下 _dispatch_kq_poll 函数的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 static int _dispatch_kq_poll(dispatch_wlh_t wlh, dispatch_kevent_t ke, int n, dispatch_kevent_t ke_out, int n_out, void *buf, size_t *avail, uint32_t flags) { bool kq_initialized = false ; int r = 0 ; dispatch_once_f(&_dispatch_kq_poll_pred, &kq_initialized, _dispatch_kq_init); if (unlikely(kq_initialized)) { _dispatch_memorypressure_init(); _voucher_activity_debug_channel_init(); } #if !DISPATCH_USE_KEVENT_QOS if (flags & KEVENT_FLAG_ERROR_EVENTS) { for (r = 0 ; r < n; r++) { ke[r].flags |= EV_RECEIPT; } n_out = n; } #endif retry: if (unlikely(wlh == NULL )) { DISPATCH_INTERNAL_CRASH(wlh, "Invalid wlh" ); } else if (wlh == DISPATCH_WLH_ANON) { int kqfd = _dispatch_kq_fd(); #if DISPATCH_USE_KEVENT_QOS if (_dispatch_kevent_workqueue_enabled) { flags |= KEVENT_FLAG_WORKQ; } r = kevent_qos(kqfd, ke, n, ke_out, n_out, buf, avail, flags); #else (void )buf; (void )avail; const struct timespec timeout_immediately =NULL ; if (flags & KEVENT_FLAG_IMMEDIATE) timeout = &timeout_immediately; r = kevent(kqfd, ke, n, ke_out, n_out, timeout); #endif #if DISPATCH_USE_KEVENT_WORKLOOP } else { flags |= KEVENT_FLAG_WORKLOOP; if (!(flags & KEVENT_FLAG_ERROR_EVENTS)) { flags |= KEVENT_FLAG_DYNAMIC_KQ_MUST_EXIST; } r = kevent_id((uintptr_t )wlh, ke, n, ke_out, n_out, buf, avail, flags); #endif } if (unlikely(r == -1 )) { int err = errno; switch (err) { case ENOMEM: _dispatch_temporary_resource_shortage(); case EINTR: goto retry; case EBADF: DISPATCH_CLIENT_CRASH(err, "Do not close random Unix descriptors" ); #if DISPATCH_USE_KEVENT_WORKLOOP case ENOENT: if ((flags & KEVENT_FLAG_ERROR_EVENTS) && (flags & KEVENT_FLAG_DYNAMIC_KQ_MUST_EXIST)) { return 0 ; } #endif default : DISPATCH_CLIENT_CRASH(err, "Unexpected error from kevent" ); } } return r; }
根据上述源码可知,_dispatch_kq_poll 内部核心逻辑是对 kevent/kevent_id 的调用。根据内部判断条件可以看出对于串行队列,会调用 kevent_id 函数。_dispatch_kq_poll 返回值实际上就是 kevent/kevent_id 函数的返回值。
kevent 和 kevent_id 是什么呢? kevent 通常与 kqueue 结合使用,它们提供了一种高效的方式来监控事件的发生。
kqueue
事件通知接口,它允许应用程序监控多个事件源,并在事件发生时获取通知。
用内核级的事件通知机制,减少了用户空间和内核空间之间的上下文切换,提高了性能。
kevent
是一个系统调用,通过 kevent() 系统调用,将事件注册到 kqueue 中。
使用 kevent() 系统调用,可以等待事件发生并获取已触发的事件列表。
kevent 函数定义如下:
1 2 3 4 int kevent (int kq, const struct kevent *changelist, int nchanges, struct kevent *eventlist, int nevents, const struct timespec *timeout) ;
各参数含义如下:
kq
kqueue 描述符,可以使用 kqueue() 系统调用获取 kq,用于标识一个事件队列。
changelist
nchanges
eventlist
用于接收已经发生的事件。调用成功返回后,这个数组包含了触发的事件信息。
nevents
eventlist 数组的大小,指定可以返回的最大事件数量。
timeout
指定等待事件发生的超时时间。如果为 NULL,kevent() 系统调用将阻塞线程直到监听的事件发生。
kevent 返回一个正整数,表示已发生的事件的数量。kevent_id 与 kevent 核心功能是一样的,kevent_id 是 kevent 的变体,提供了更细粒度的事件管理。可以在 Apple 开源的 XNU 源码中看到 kevent/kevent_id 实现逻辑,链接:apple-oss-distributions/xnu 。
总结来说,kevent/kevent_id 是一个系统调用,可以用来监听注册的事件的发生,其返回了已发生的事件的数量。
但是,从 _dispatch_event_loop_wait_for_ownership 中 kev_flags 的配置:
1 2 3 uint32_t kev_flags = KEVENT_FLAG_IMMEDIATE | KEVENT_FLAG_ERROR_EVENTS;
这里有两个配置:
KEVENT_FLAG_IMMEDIATE
使 kevent_id/kevent 是非阻塞的,即调用立刻返回,不用等到事件发生时再返回,所以增加了该配置后会使调用不阻塞线程。
KEVENT_FLAG_ERROR_EVENTS
即使发生错误也要返回事件,如果在处理 changelist 时遇到错误,会将错误信息作为一个事件返回给用户,而不是直接返回错误码。
所以,从表面上看,调用 kevent_id 函数的时候,是非阻塞的,同时也说明了 _dispatch_kq_poll 函数是非阻塞的。kevent_id 返回了本次调用监听到的发生的事件的数量(含错误事件数量),由于 kevent_id 函数的调用是非阻塞的,所以根本没有机会等到监听的事件的发生,也就是说 _dispatch_kq_poll 正常情况下返回都是 0。
而 _dispatch_event_loop_wait_for_ownership 函数的实现中,只有 _dispatch_kq_poll 返回值大于 0 时,才会 goto again 逻辑。所以,_dispatch_event_loop_wait_for_ownership 对线程的阻塞,不是靠不停 goto again 实现的。
那么问题就来了,既然不会不停地 goto again,看起来,_dispatch_event_loop_wait_for_ownership 对线程的阻塞,只能是靠 kevent_id 函数了。但是 kevent_id 不是配置了 KEVENT_FLAG_IMMEDIATE 之后,就变成了非阻塞的了吗?
kevent_id 到底会不会阻塞线程呢?kevent_id 传入 KEVENT_FLAG_IMMEDIATE 这个参数看,kevent_id 确实不会阻塞线程。但是,需要再看下传入的 dispatch_kevent_s 信息:
1 _dispatch_kq_fill_workloop_sync_event(&ke[n++], DISPATCH_WORKLOOP_SYNC_WAIT, wlh, dq_state, dsc->dsc_waiter);
这里 _dispatch_kq_fill_workloop_sync_event 函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 static void _dispatch_kq_fill_workloop_sync_event(dispatch_kevent_t ke, int which, dispatch_wlh_t wlh, uint64_t dq_state, dispatch_tid tid) { dispatch_queue_t dq = (dispatch_queue_t )wlh; pthread_priority_t pp = 0 ; uint32_t fflags = 0 ; uint64_t mask = 0 ; uint16_t action = 0 ; switch (which) { case DISPATCH_WORKLOOP_SYNC_DISCOVER: dispatch_assert(_dq_state_received_sync_wait(dq_state)); dispatch_assert(_dq_state_in_uncontended_sync(dq_state)); action = EV_ADD | EV_DISABLE; fflags = NOTE_WL_SYNC_WAKE | NOTE_WL_DISCOVER_OWNER | NOTE_WL_IGNORE_ESTALE; mask = DISPATCH_QUEUE_ROLE_MASK | DISPATCH_QUEUE_RECEIVED_SYNC_WAIT | DISPATCH_QUEUE_UNCONTENDED_SYNC; break ; case DISPATCH_WORKLOOP_SYNC_WAIT: action = EV_ADD | EV_DISABLE; fflags = NOTE_WL_SYNC_WAIT; pp = _dispatch_get_priority(); if (_dispatch_qos_from_pp(pp) == 0 ) { pp = _dispatch_qos_to_pp(DISPATCH_QOS_DEFAULT); } break ; case DISPATCH_WORKLOOP_SYNC_FAKE: action = EV_ADD | EV_DISABLE; fflags = NOTE_WL_SYNC_WAKE; break ; case DISPATCH_WORKLOOP_SYNC_WAKE: dispatch_assert(_dq_state_drain_locked_by(dq_state, tid)); action = EV_ADD | EV_DISABLE; fflags = NOTE_WL_SYNC_WAKE | NOTE_WL_DISCOVER_OWNER; break ; case DISPATCH_WORKLOOP_SYNC_END: action = EV_DELETE | EV_ENABLE; fflags = NOTE_WL_SYNC_WAKE | NOTE_WL_END_OWNERSHIP; break ; default : DISPATCH_INTERNAL_CRASH(which, "Invalid transition" ); } *ke = (dispatch_kevent_s){ .ident = tid, .filter = EVFILT_WORKLOOP, .flags = action, .fflags = fflags, .udata = (uintptr_t )wlh, .qos = (__typeof__(ke->qos))pp, .ext[EV_EXTIDX_WL_MASK] = mask, .ext[EV_EXTIDX_WL_VALUE] = dq_state, }; if (fflags & NOTE_WL_DISCOVER_OWNER) { ke->ext[EV_EXTIDX_WL_ADDR] = (uintptr_t )&dq->dq_state; } _dispatch_kevent_wlh_debug(_dispatch_workloop_actions[which], ke); }
由于传入的 which 参数是 DISPATCH_WORKLOOP_SYNC_WAIT,所以 ke 的 fflags 的值是:
1 fflags = NOTE_WL_SYNC_WAIT
NOTE_WL_SYNC_WAIT 不是在 libdispatch 定义的,是在 XNU 中定义的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #define NOTE_WL_SYNC_WAIT 0x00000004 #define NOTE_WL_SYNC_WAKE 0x00000008
与 NOTE_WL_SYNC_WAIT 对应的,还有个 NOTE_WL_SYNC_WAKE,两者作用如下:
NOTE_WL_SYNC_WAIT
这个标志表示调用者正在等待成为工作循环的所有者。
如果设置了这个标志,调用线程会阻塞 ,直到它被唤醒成为所有者。
可以用来实现线程间的同步,让一个线程等待获得工作循环的所有权。
NOTE_WL_SYNC_WAKE
这个标志用于标记等待的 knote 可以成为所有者了。
设置这个标志会唤醒之前因 NOTE_WL_SYNC_WAIT 而阻塞的线程 。
所以,由于传入的 ke(dispatch_kevent_s) 信息配置了 NOTE_WL_SYNC_WAIT,所以及时调用 kevent_id 时配置了 KEVENT_FLAG_IMMEDIATE,kevent_id 仍然会阻塞线程,直到使用 NOTE_WL_SYNC_WAKE 再次唤醒被阻塞的线程。
2、唤醒阻塞的线程 经过上一步的分析,线程的阻塞、唤醒逻辑就比较清晰了。
再回头看下 _dispatch_sync_f_slow 实现逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 static void _dispatch_sync_f_slow(dispatch_queue_class_t top_dqu, void *ctxt, dispatch_function_t func, uintptr_t top_dc_flags, dispatch_queue_class_t dqu, uintptr_t dc_flags) { __DISPATCH_WAIT_FOR_QUEUE__(&dsc, dq); _dispatch_sync_invoke_and_complete_recurse(top_dq, ctxt, func, top_dc_flags DISPATCH_TRACE_ARG(&dsc)); }
_dispatch_sync_invoke_and_complete_recurse 函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 static void _dispatch_sync_invoke_and_complete_recurse(dispatch_queue_class_t dq, void *ctxt, dispatch_function_t func, uintptr_t dc_flags DISPATCH_TRACE_ARG(void *dc)) { _dispatch_sync_function_invoke_inline(dq, ctxt, func); _dispatch_trace_item_complete(dc); _dispatch_sync_complete_recurse(dq._dq, NULL , dc_flags); } static void _dispatch_sync_complete_recurse(dispatch_queue_t dq, dispatch_queue_t stop_dq, uintptr_t dc_flags) { bool barrier = (dc_flags & DC_FLAG_BARRIER); do { if (dq == stop_dq) return ; if (barrier) { dx_wakeup(dq, 0 , DISPATCH_WAKEUP_BARRIER_COMPLETE); } else { _dispatch_lane_non_barrier_complete(upcast(dq)._dl, 0 ); } dq = dq->do_targetq; barrier = (dq->dq_width == 1 ); } while (unlikely(dq->do_targetq)); }
到这里,再回头看下调用 _dispatch_sync_f_slow 函数地方:
1 2 3 4 5 6 if (unlikely(!_dispatch_queue_try_acquire_barrier_sync(dl, tid))) { return _dispatch_sync_f_slow(dl, ctxt, func, DC_FLAG_BARRIER, dl, DC_FLAG_BARRIER | dc_flags); }
传入的 dc_flags 实际为:
1 dc_flags = DC_FLAG_BARRIER | dc_flags;
所以,_dispatch_sync_complete_recurse 里 barrier 为 true,因此会执行:
1 dx_wakeup(dq, 0 , DISPATCH_WAKEUP_BARRIER_COMPLETE);
dx_wakeup 是个宏:
1 2 #define dx_wakeup(x, y, z) dx_vtable(x)->dq_wakeup(x, y, z) #define dx_vtable(x) (&(x)->do_vtable->_os_obj_vtable)
将宏完全展开:
1 &(dq)->do_vtable->_os_obj_vtable->dq_wakeup(dq, 0 , DISPATCH_WAKEUP_BARRIER_COMPLETE)
到这里,就需要再回头看下另篇文章《GCD 底层原理 2 - dispatch_queue》 里的关于串行队列虚表 vtable 的内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 const struct dispatch_lane_vtable_s _dispatch_queue_serial_vtable = ._os_obj_xref_dispose = _dispatch_xref_dispose, ._os_obj_dispose = _dispatch_dispose, ._os_obj_vtable = { .do_kind = "queue_serial" , .do_type = DISPATCH_QUEUE_SERIAL_TYPE, .do_dispose = _dispatch_lane_dispose, .do_debug = _dispatch_queue_debug, .do_invoke = _dispatch_lane_invoke, .dq_activate = _dispatch_lane_activate, .dq_wakeup = _dispatch_lane_wakeup, .dq_push = _dispatch_lane_push, }, };
所以,前面 dx_wakeup 的调用,实际调用的是 _dispatch_lane_wakeup 函数,该函数实现源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void _dispatch_lane_wakeup(dispatch_lane_class_t dqu, dispatch_qos_t qos, dispatch_wakeup_flags_t flags) { dispatch_queue_wakeup_target_t target = DISPATCH_QUEUE_WAKEUP_NONE; if (unlikely(flags & DISPATCH_WAKEUP_BARRIER_COMPLETE)) { return _dispatch_lane_barrier_complete(dqu, qos, flags); } if (_dispatch_queue_class_probe(dqu)) { target = DISPATCH_QUEUE_WAKEUP_TARGET; } return _dispatch_queue_wakeup(dqu, qos, flags, target); }
经过下面函数执行路径:
1 2 3 4 5 _dispatch_queue_wakeup ⬇️ _dispatch_workloop_barrier_complete ⬇️ _dispatch_event_loop_end_ownership
会调用到 _dispatch_event_loop_end_ownership 函数,_dispatch_event_loop_end_ownership 函数核心逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void _dispatch_event_loop_end_ownership(dispatch_wlh_t wlh, uint64_t old_state, uint64_t new_state, uint32_t flags) { uint32_t kev_flags = KEVENT_FLAG_IMMEDIATE | KEVENT_FLAG_ERROR_EVENTS; dispatch_kevent_s ke[2 ]; int n = 0 ; if (!_dq_state_in_uncontended_sync(old_state)) { dispatch_tid tid = _dispatch_tid_self(); _dispatch_kq_fill_workloop_sync_event(&ke[n++], DISPATCH_WORKLOOP_SYNC_END, wlh, new_state, tid); } if (_dispatch_kq_poll(wlh, ke, n, ke, n, NULL , NULL , kev_flags)) { _dispatch_kevent_workloop_drain_error(&ke[0 ], 0 ); __builtin_unreachable(); } }
这里又看到了熟悉的逻辑:
调用 _dispatch_kq_fill_workloop_sync_event 创建 ke。
调用 _dispatch_kq_poll。
这里调用 _dispatch_kq_fill_workloop_sync_event 时,传入的是 DISPATCH_WORKLOOP_SYNC_END,结合前面提到的 _dispatch_kq_fill_workloop_sync_event 源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 static void _dispatch_kq_fill_workloop_sync_event(dispatch_kevent_t ke, int which, dispatch_wlh_t wlh, uint64_t dq_state, dispatch_tid tid) { switch (which) { case DISPATCH_WORKLOOP_SYNC_END: action = EV_DELETE | EV_ENABLE; fflags = NOTE_WL_SYNC_WAKE | NOTE_WL_END_OWNERSHIP; break ; default : DISPATCH_INTERNAL_CRASH(which, "Invalid transition" ); } *ke = (dispatch_kevent_s){ .ident = tid, .filter = EVFILT_WORKLOOP, .flags = action, .fflags = fflags, .udata = (uintptr_t )wlh, .qos = (__typeof__(ke->qos))pp, .ext[EV_EXTIDX_WL_MASK] = mask, .ext[EV_EXTIDX_WL_VALUE] = dq_state, }; }
可以知道,这里 fflags 配置的是:
1 fflags = NOTE_WL_SYNC_WAKE | NOTE_WL_END_OWNERSHIP;
结合前面 NOTE_WL_SYNC_WAIT、NOTE_WL_SYNC_WAKE 相关内容可以知道,配置了 NOTE_WL_SYNC_WAKE 之后,在 _dispatch_kq_poll 内部调用的 kevent_id,会使当前唤醒当前被阻塞的线程,开始执行当前任务。
除此之外,在前面获取屏障锁成功之后的逻辑,所调用的 _dispatch_lane_barrier_sync_invoke_and_complete 函数,内部也是基本相同的唤起阻塞线程的逻辑。
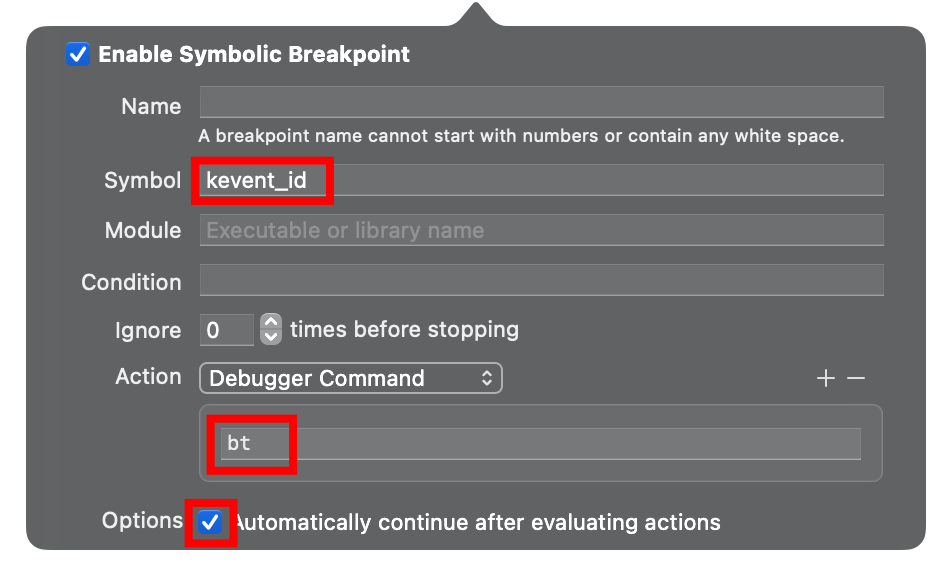
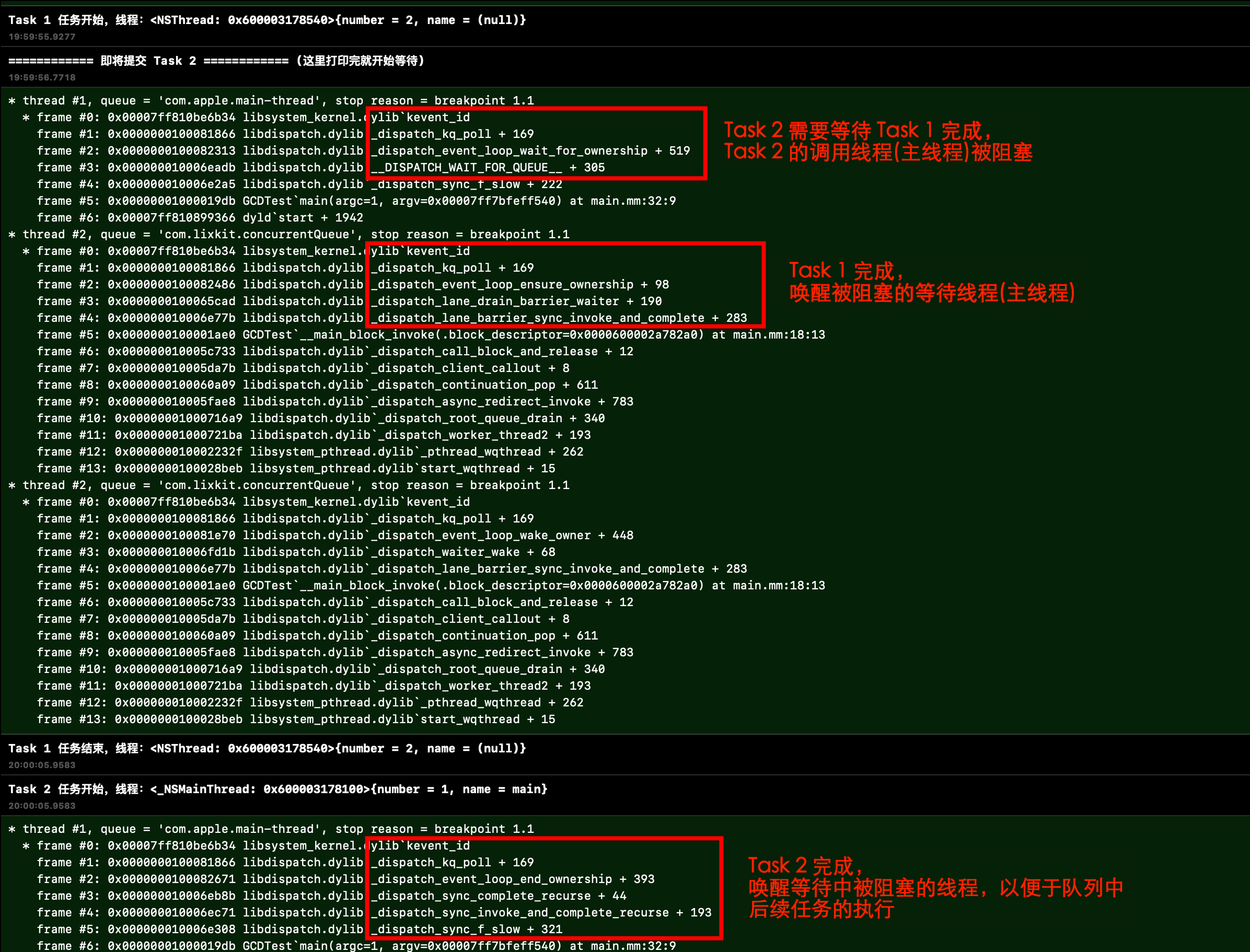
可以使用一个简单的 Demo 验证这个流程:Symbolic 断点,当调用到 kevent_id 函数时候,打印出调用堆栈:
六、总结 前面总结了使用 dispatch_sync 往串行队列提交任务的源码执行逻辑,对于 dispatch_sync 往并发队列提交任务的处理流程,将在后续分析 dispatch_async 源码时一起分析。
可以用下图表示上述的源码逻辑: