一、概述 提到线程,不得不讲下 CPU,CPU 是计算机的“大脑”,负责着程序的执行和数据的处理。
现代 CPU 基本都是多核 CPU,这里的“核”是指 CPU 的物理核心 ,物理核心是真正的硬件单元,负责执行指令。物理核心在执行某些类型的指令(如内存访问)时,可能会发生等待,这时核心的其他执行单元如 ALU(算术逻辑单元)可能处于闲置状态。在支持超线程(Hyper-Threading)的 CPU 上,每个物理核心通常可以提供两个逻辑核心 ,使得当一个逻辑核心在等待时,另一个逻辑核心可以利用闲置的执行单元来提前执行其他线程的指令。通过逻辑核心,操作系统可以调度更多的线程同时执行,这增强了系统的并发能力和响应速度。
所以,CPU 逻辑核心数量代表了最大并发处理数量参考上限,在逻辑核心数的范围内,操作系统可以提供较高性能的线程调度。
但是,这并不代表系统所能并发执行的线程数量一定小于 CPU 逻辑核心数量,操作系统可以通过上下文切换在单个逻辑核心上交替执行多个线程。虽然可以调度更多线程,但同时活跃的线程数超过逻辑核心数可能导致资源竞争和性能下降,所以我们在开发时,应尽量避免创建太多的线程。
对于开发者来说,需要使用 OC 或者 Swift 这类高级语言去开发一个 APP,编译器会将我们使用高级语言编写的代码,会经过编译器的编译处理,先将高级语言代码转换成汇编代码,最后再将汇编代码转成 CPU 可以执行的机器码。
只看 CPU 的单个核(物理核心),CPU 核从程序的入口地址开始,逐条读取并执行机器指令。每个核心按照程序计数器(PC)的指引,顺序执行指令,除非遇到控制流改变的指令(如跳转、条件分支)。由于 CPU 单个核一次只能执行一个指令,所以每个 CPU 核只可以同时执行一个线程。
现代操作系统通过时间分片(时间片轮转)的方式实现了单个核心“同时”执行多个线程,时间片是操作系统分配给每个线程的执行时间段(通常是几十毫秒)。一个线程在其时间片内运行,时间片结束时,操作系统再切换到另一个线程继续执行。线程可以有不同的优先级,操作系统可能会优先调度高优先级的线程。在 iOS 中,优先级可以通过 GCD 的 QoS(服务质量)等级进行设置。
也就是说,我们开发的 iOS APP 可以执行的最大线程数量,是可以远大于 CPU 核心数量的。
在 GCD 多线程开发中,经常会涉及一个“线程池”的概念,在提到 GCD 线程池时,经常有人说“GCD 线程池中线程最大数量是 64 个“、“GCD 最多可以创建 64 个线程”,其实这个说法是不完全正确的。
二、线程最大数量测试 新建一个 macOS 的 Command Line Tool 的工程,用来测试全局队列、并发队列、串行队列最多可以创建多少个线程。
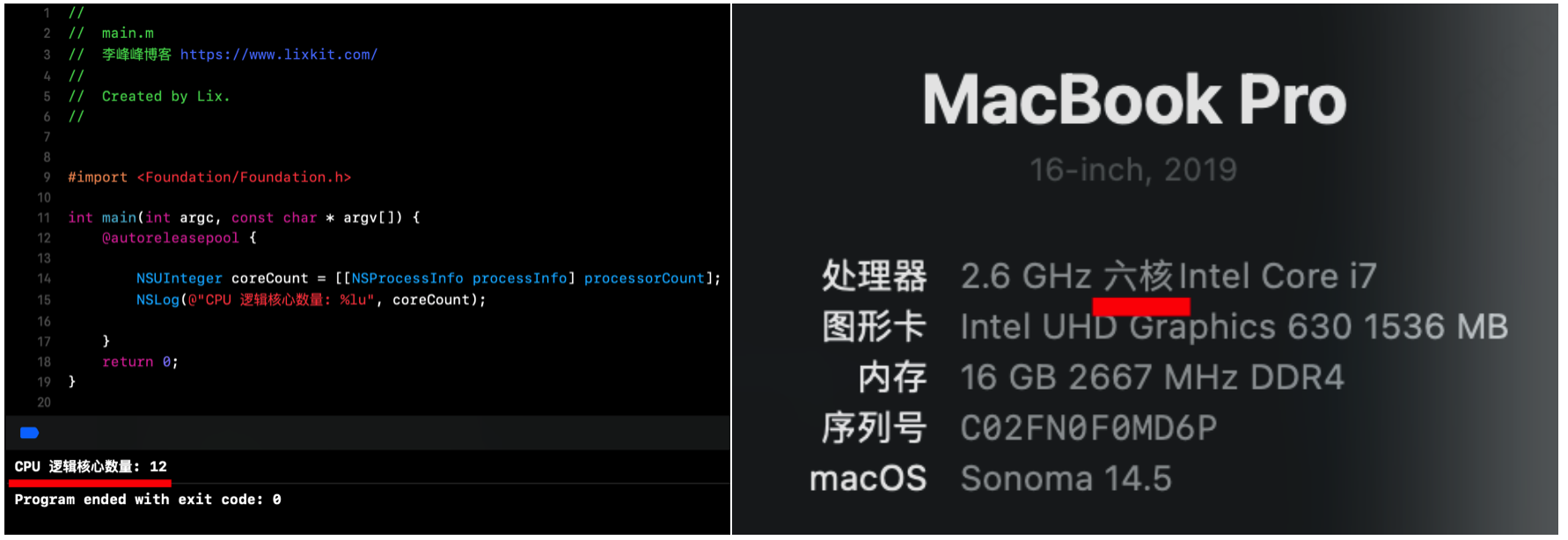
首先,先打印当前设备有多少个逻辑核心:
为了看清 CPU 繁忙(活跃线程数量超过逻辑核心数量 )和 CPU 空闲时,最大可创建线程的数量,需要针对两种常见分别测试。
1、全局并发队列 (1)CPU 繁忙 通过下面 Demo 测试 CPU 在繁忙情况下,使用全局并发队列最多可创建多少个线程:
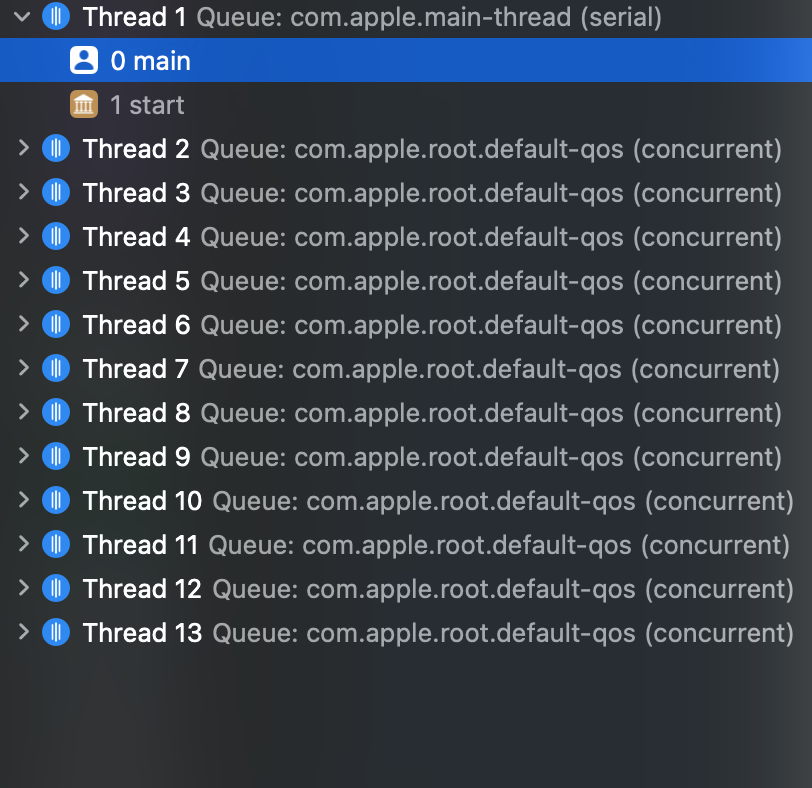
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #import <Foundation/Foundation.h> int main(int argc, const char * argv[]) { @autoreleasepool { for (NSInteger i = 0 ; i <= 1000 ; i ++) { dispatch_queue_t queue = dispatch_get_global_queue(0 , 0 ); dispatch_async (queue, ^{ NSLog (@"执行任务 i = %ld" , (long )i); while (YES ) { } }); } NSLog (@"在此处加断点看线程数量" ); } return 0 ; }
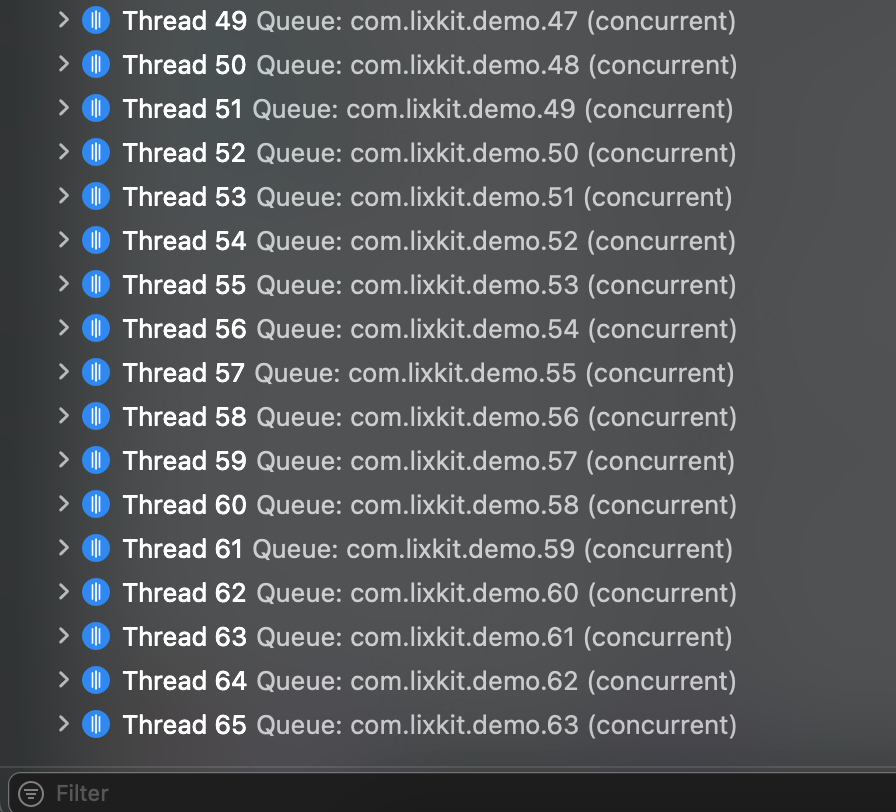
去掉一个主线程,可以看到全局并发队列在 CPU 繁忙的情况下,最多可以创建 12 个线程,与 CPU 逻辑核心数量一致。
(2)CPU 空闲情况 将上面 Demo 中的 while 无限循环改成 sleep,使其不一直占用 CPU,模拟 CPU 空闲情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #import <Foundation/Foundation.h> int main(int argc, const char * argv[]) { @autoreleasepool { for (NSInteger i = 0 ; i <= 1000 ; i ++) { dispatch_queue_t queue = dispatch_get_global_queue(0 , 0 ); dispatch_async (queue, ^{ NSLog (@"执行任务 i = %ld" , (long )i); [NSThread sleepForTimeInterval:10 ]; }); } NSLog (@"在此处加断点看线程数量" ); } return 0 ; }
(3)结论 全局队列最多可创建线程数量:
CPU 繁忙时:与 CPU 逻辑核心数量一致
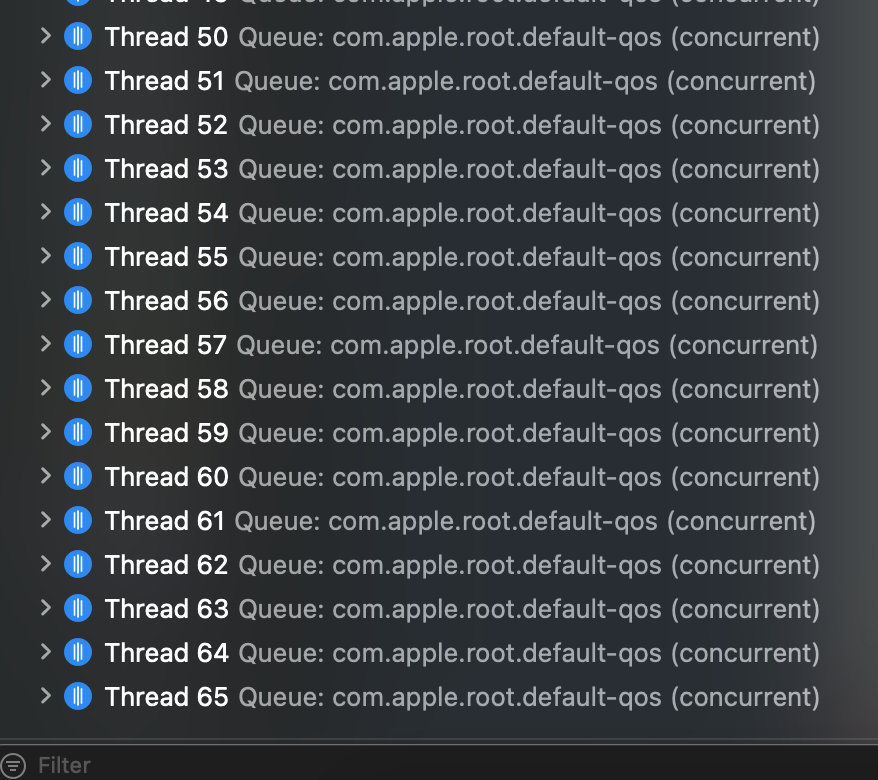
CPU 空闲时:64 个
2、并发队列 测试并发队列时,每次循环都创建新的队列,测试在 CPU 繁忙、空闲情况下分别最多可以创建多少个线程。
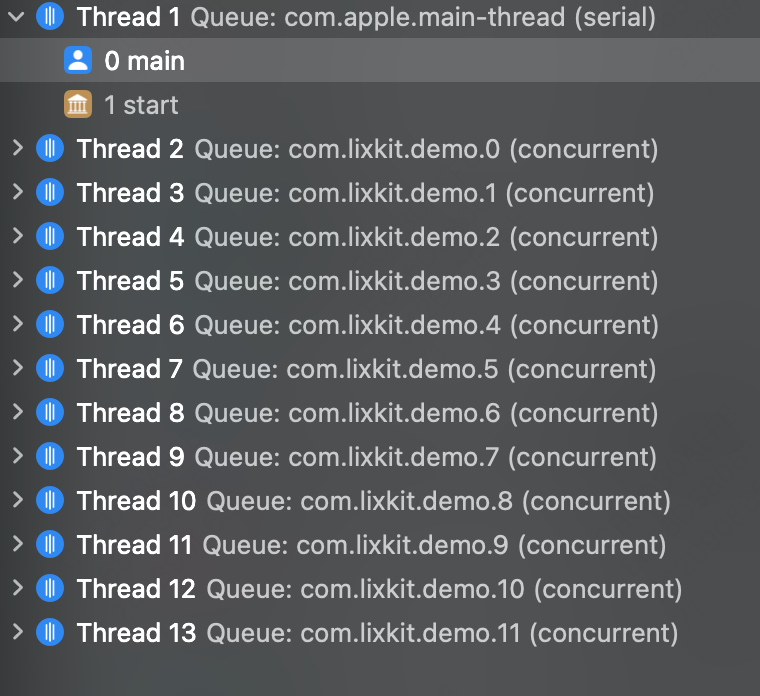
(1)CPU 繁忙情况 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #import <Foundation/Foundation.h> int main(int argc, const char * argv[]) { @autoreleasepool { for (NSInteger i = 0 ; i <= 1000 ; i ++) { NSString *label = [NSString stringWithFormat:@"com.lixkit.demo.%lu" , i]; dispatch_queue_t queue = dispatch_queue_create(label.UTF8String, DISPATCH_QUEUE_CONCURRENT); dispatch_async (queue, ^{ NSLog (@"执行任务 i = %ld" , (long )i); while (YES ) { } }); } NSLog (@"在此处加断点看线程数量" ); } return 0 ; }
(2)CPU 空闲情况 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #import <Foundation/Foundation.h> int main(int argc, const char * argv[]) { @autoreleasepool { for (NSInteger i = 0 ; i <= 1000 ; i ++) { NSString *label = [NSString stringWithFormat:@"com.lixkit.demo.%lu" , i]; dispatch_queue_t queue = dispatch_queue_create(label.UTF8String, DISPATCH_QUEUE_CONCURRENT); dispatch_async (queue, ^{ NSLog (@"执行任务 i = %ld" , (long )i); [NSThread sleepForTimeInterval:10 ]; }); } NSLog (@"在此处加断点看线程数量" ); } return 0 ; }
(3)结论 并发队列最多可创建线程数量:
CPU 繁忙时:与 CPU 逻辑核心数量一致
CPU 空闲时:64 个
与全局并发队列表现一致。
3、串行队列 测试串行队列和并发队列类似,只需要将循环里创建的队列改成串行队列即可。
(1)CPU 繁忙情况 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #import <Foundation/Foundation.h> int main(int argc, const char * argv[]) { @autoreleasepool { for (NSInteger i = 0 ; i <= 1000 ; i ++) { NSString *label = [NSString stringWithFormat:@"com.lixkit.demo.%lu" , i]; dispatch_queue_t queue = dispatch_queue_create(label.UTF8String, DISPATCH_QUEUE_SERIAL); dispatch_async (queue, ^{ NSLog (@"执行任务 i = %ld" , (long )i); while (YES ) { } }); } [NSThread sleepForTimeInterval:1 ]; NSLog (@"在此处加断点看线程数量" ); } return 0 ; }
(2)CPU 空闲情况 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #import <Foundation/Foundation.h> int main(int argc, const char * argv[]) { @autoreleasepool { for (NSInteger i = 0 ; i <= 1000 ; i ++) { NSString *label = [NSString stringWithFormat:@"com.lixkit.demo.%lu" , i]; dispatch_queue_t queue = dispatch_queue_create(label.UTF8String, DISPATCH_QUEUE_SERIAL); dispatch_async (queue, ^{ NSLog (@"执行任务 i = %ld" , (long )i); [NSThread sleepForTimeInterval:10 ]; }); } [NSThread sleepForTimeInterval:1 ]; NSLog (@"在此处加断点看线程数量" ); } return 0 ; }
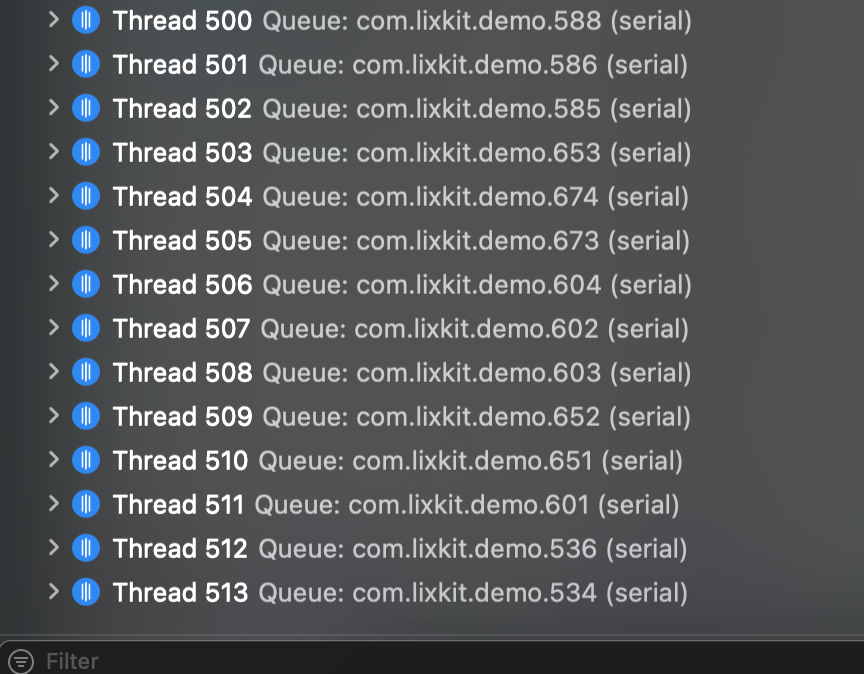
(3)结论 无论 CPU 是否空闲,串行队列都最多可以创建 512 个线程。
4、并发队列 + 串行队列 经过上面的测试可以发现,在 CPU 空闲情况下,并发队列相较于 CPU 繁忙时,可以创建更多数量的线程,最多可以创建 64 个线程。而串行队列,无论 CPU 是否空闲,都最多可以创建多达 512 个线程。
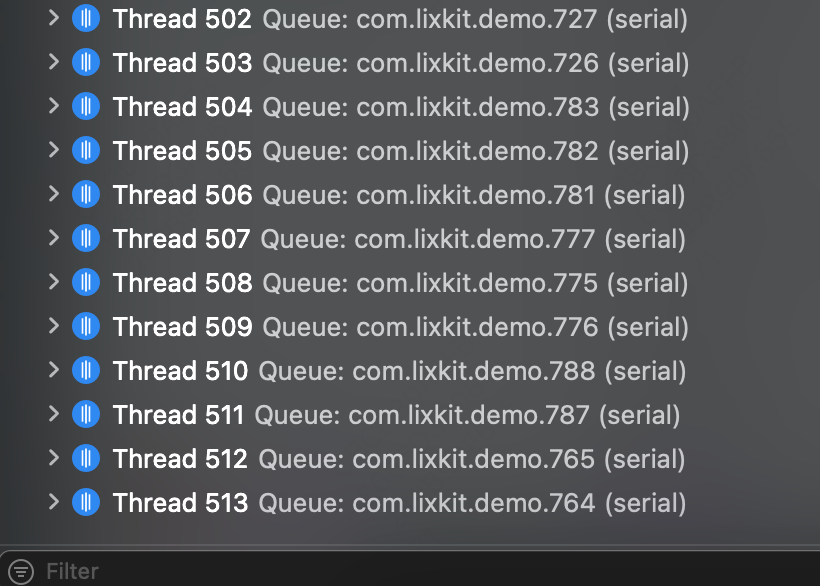
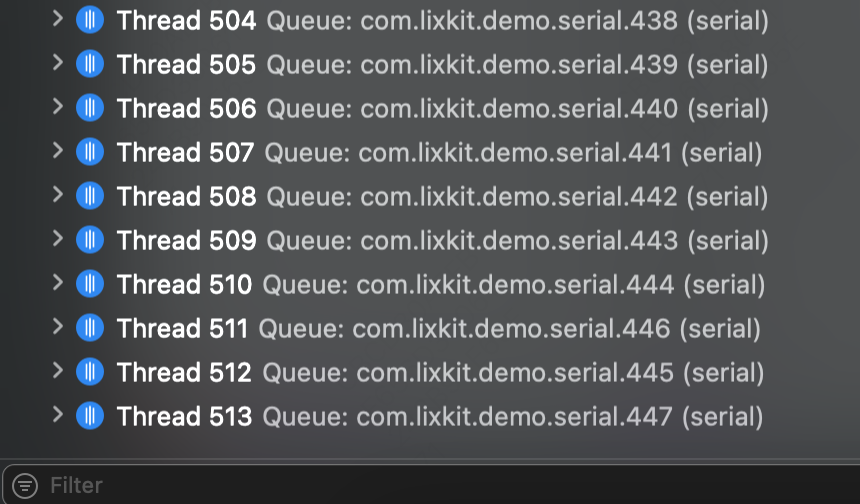
那么,在 CPU 空闲情况下下,同时使用并发队列和串行队列,最多可创建的线程数量,是 512 还是 512 + 64 = 576 个呢?
接下来通过 Demo 测试下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #import <Foundation/Foundation.h> int main(int argc, const char * argv[]) { @autoreleasepool { for (NSInteger i = 0 ; i <= 1000 ; i ++) { NSString *serialLabel = [NSString stringWithFormat:@"com.lixkit.demo.serial.%lu" , i]; dispatch_queue_t serialQueue = dispatch_queue_create(serialLabel.UTF8String, DISPATCH_QUEUE_SERIAL); dispatch_async (serialQueue, ^{ NSLog (@"执行任务 i = %ld" , (long )i); [NSThread sleepForTimeInterval:10 ]; }); NSString *concurrentLabel = [NSString stringWithFormat:@"com.lixkit.demo.concurrent.%lu" , i]; dispatch_queue_t concurrentQueue = dispatch_queue_create(concurrentLabel.UTF8String, DISPATCH_QUEUE_CONCURRENT); dispatch_async (concurrentQueue, ^{ NSLog (@"执行任务 i = %ld" , (long )i); [NSThread sleepForTimeInterval:10 ]; }); } [NSThread sleepForTimeInterval:1 ]; NSLog (@"在此处加断点看线程数量" ); } return 0 ; }
5、总结 经过测试可以得出结论,关于不同队列可创建线程数量的结论如下:
全局队列、并发队列
CPU 繁忙时,最大可创建线程数量:为 CPU 逻辑核心数量。
CPU 空闲时,最大可创建线程数量:64 个。
串行队列
CPU 繁忙、空闲时,最大可创建线程数量均为:512 个。
并发队列 + 串行队列
两种队列一起使用,即使在 CPU 空闲时,最大可创建线程数量也为:512 个。
根据测试结果可知,“GCD 线程池中线程最大数量是 64 个“、“GCD 最多可以创建 64 个线程”这样的说法是不完全正确的。更准确的说法应该是:GCD 线程池中线程最大数量是 512 个,其中并发队列(含全局并发队列)最多可创建线程数量是 64 个,串行队列最多可创建线程数量是 512 个。其中,这个“线程池”是由内核 XNU 维护的。
在上一篇文章《GCD 底层原理 4 - dispatch_async》 中已经分析过,dispatch_async 对于并发队列和串行队列申请线程的两个关键步骤如下:
初始化 workqueue
pthread_workqueue_setup(全局仅调用一次)初始化 workqueue
内部会调用 workq_open 函数(后续会分析该函数)
申请线程
并发队列
调用 _pthread_workqueue_addthreads 申请线程
串行队列
接下来,分别看下两种申请线程的方式分别是如何实现的。
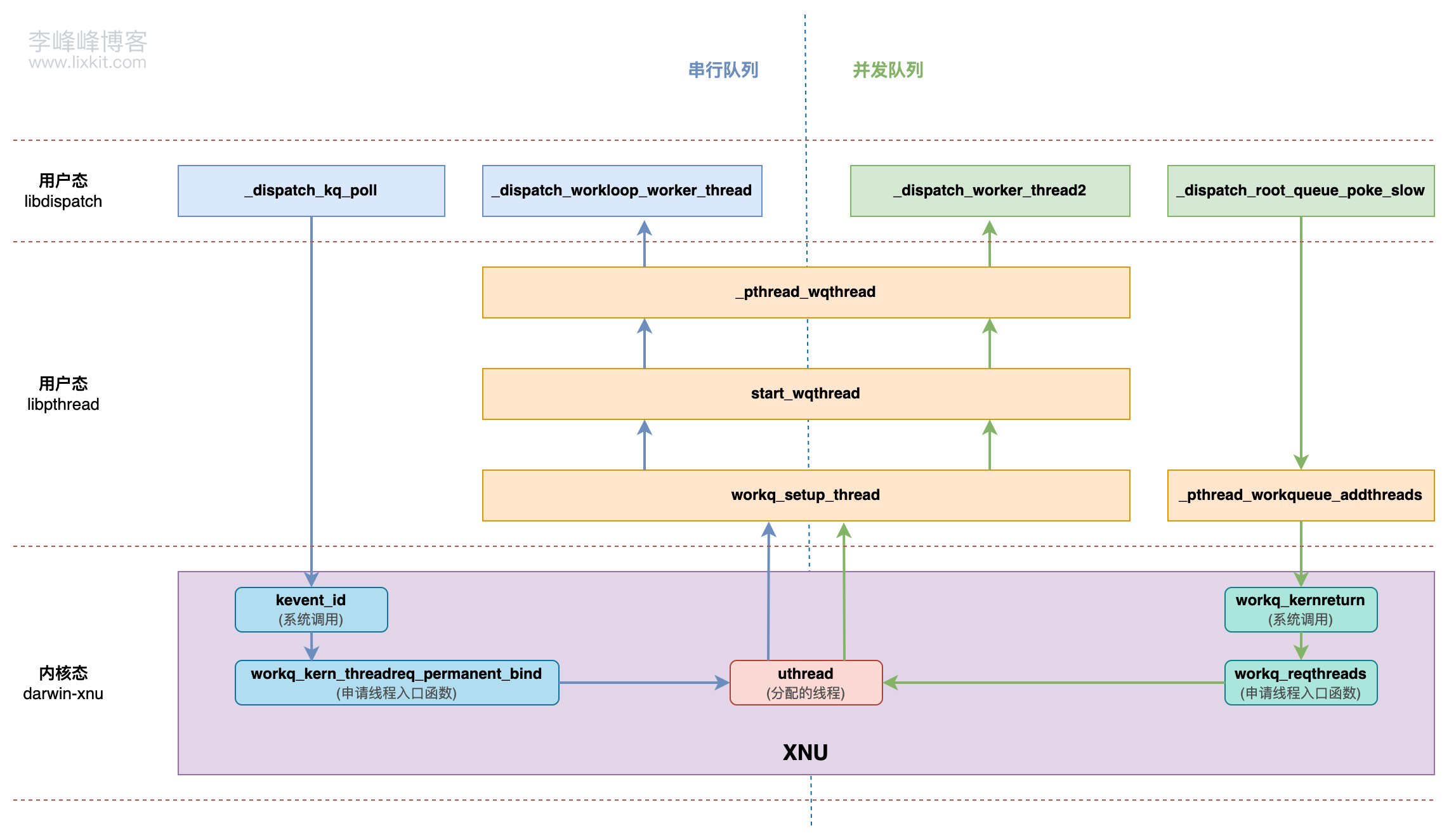
三、并发队列申请线程 1、_pthread_workqueue_addthreads 并发队列通过 _pthread_workqueue_addthreads 函数申请线程去执行任务,该函数是 libpthread 提供的一个函数,函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 int _pthread_workqueue_addthreads(int numthreads, pthread_priority_t priority) { int res = 0 ; if (__libdispatch_workerfunction == NULL ) { return EPERM; } #if TARGET_OS_OSX priority &= ~_PTHREAD_PRIORITY_SCHED_PRI_FLAG; #endif res = __workq_kernreturn(WQOPS_QUEUE_REQTHREADS, NULL , numthreads, (int )priority); if (res == -1 ) { res = errno; } return res; }
可以看到,该函数核心是调用 __workq_kernreturn 请求线程,并且调用 __workq_kernreturn 时,第一个参数传入的是 WQOPS_QUEUE_REQTHREADS。在《GCD 底层原理 4 - dispatch_async》 中已经分析过,调用 _pthread_workqueue_addthreads 时,传入的 numthreads 参数为 1,即每次请求一个线程。可以看到,这个 numthreads 参数也是透传给了 __workq_kernreturn。
2、__workq_kernreturn __workq_kernreturn 是 XNU 内核提供的一个函数,__workq_kernreturn 本质是个系统调用,在内核态对应 workq_kernreturn 函数,该函数精简后的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int workq_kernreturn (struct proc *p, struct workq_kernreturn_args *uap, int32_t *retval) { switch (options) { case WQOPS_QUEUE_REQTHREADS: { error = workq_reqthreads(p, arg2, arg3, false ); break ; } } return error; }
在上述逻辑中,如果 options 是 WQOPS_QUEUE_REQTHREADS,则会调用 workq_reqthreads 请求线程。
3、workq_reqthreads 在看 workq_reqthreads 函数之前,先看下几个关键的宏定义:
1 2 3 4 5 6 7 #define WORKQUEUE_MAXTHREADS 512 static uint32_t wq_max_threads = WORKQUEUE_MAXTHREADS; static uint32_t wq_max_constrained_threads = WORKQUEUE_MAXTHREADS / 8 ;
在前面几篇文章里,反复提到了 workqueue,这里看下 workqueue 的结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 struct workqueue { uint16_t wq_nthreads; uint16_t wq_thidlecount; struct proc *wq_proc ; struct workq_uthread_head wq_thrunlist ; struct workq_uthread_head wq_thnewlist ; struct workq_uthread_head wq_thidlelist ; };
每个进程都有一个 workqueue,workqueue 中存储了一系列线程池管理相关的内容,包含线程总数、空闲的线程数等。其中,workq_uthread_head 定义如下:
1 2 3 4 5 6 7 8 9 10 TAILQ_HEAD(workq_uthread_head, uthread); #define TAILQ_HEAD(name, type) \ __MISMATCH_TAGS_PUSH \ __NULLABILITY_COMPLETENESS_PUSH \ struct name { \ struct type *tqh_first; \ struct type **tqh_last; \ TRACEBUF \ }
所以,GCD 的线程池是使用双向链表的结构来存储线程的。
再继续看下 workq_reqthreads 函数,workq_reqthreads 是 GCD 请求线程的入口函数,该函数参数及实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 static int workq_reqthreads (struct proc *p, uint32_t reqcount, pthread_priority_t pp, bool cooperative) { thread_qos_t qos = _pthread_priority_thread_qos(pp); struct workqueue *wq = uint32_t unpaced, upcall_flags = WQ_FLAG_THREAD_NEWSPI; int ret = 0 ; if (wq == NULL || reqcount <= 0 || reqcount > UINT16_MAX || qos == THREAD_QOS_UNSPECIFIED) { ret = EINVAL; goto exit ; } WQ_TRACE_WQ(TRACE_wq_wqops_reqthreads | DBG_FUNC_NONE, wq, reqcount, pp, cooperative); workq_threadreq_t req = zalloc(workq_zone_threadreq); priority_queue_entry_init(&req->tr_entry); req->tr_state = WORKQ_TR_STATE_NEW; req->tr_qos = qos; workq_tr_flags_t tr_flags = 0 ; if (pp & _PTHREAD_PRIORITY_OVERCOMMIT_FLAG) { tr_flags |= WORKQ_TR_FLAG_OVERCOMMIT; upcall_flags |= WQ_FLAG_THREAD_OVERCOMMIT; } if (cooperative) { tr_flags |= WORKQ_TR_FLAG_COOPERATIVE; upcall_flags |= WQ_FLAG_THREAD_COOPERATIVE; if (reqcount > 1 ) { ret = ENOTSUP; goto free_and_exit; } } if (workq_tr_is_cooperative(tr_flags) && workq_tr_is_overcommit(tr_flags)) { ret = EINVAL; goto free_and_exit; } req->tr_flags = tr_flags; WQ_TRACE_WQ(TRACE_wq_thread_request_initiate | DBG_FUNC_NONE, wq, workq_trace_req_id(req), req->tr_qos, reqcount); workq_lock_spin(wq); do { if (_wq_exiting(wq)) { goto unlock_and_exit; } unpaced = reqcount - 1 ; if (reqcount > 1 ) { assert(!workq_threadreq_is_cooperative(req)); if (workq_threadreq_is_nonovercommit(req)) { unpaced = workq_constrained_allowance(wq, qos, NULL , false , true ); if (unpaced >= reqcount - 1 ) { unpaced = reqcount - 1 ; } } } assert(!(req->tr_flags & WORKQ_TR_FLAG_WL_PARAMS)); while (unpaced > 0 && wq->wq_thidlecount) { struct uthread *uth ; bool needs_wakeup; uint8_t uu_flags = UT_WORKQ_EARLY_BOUND; if (workq_tr_is_overcommit(req->tr_flags)) { uu_flags |= UT_WORKQ_OVERCOMMIT; } uth = workq_pop_idle_thread(wq, uu_flags, &needs_wakeup); _wq_thactive_inc(wq, qos); wq->wq_thscheduled_count[_wq_bucket(qos)]++; workq_thread_reset_pri(wq, uth, req, true ); wq->wq_fulfilled++; uth->uu_save.uus_workq_park_data.upcall_flags = upcall_flags; uth->uu_save.uus_workq_park_data.thread_request = req; if (needs_wakeup) { workq_thread_wakeup(uth); } unpaced--; reqcount--; } } while (unpaced && wq->wq_nthreads < wq_max_threads && (workq_add_new_idle_thread(p, wq, workq_unpark_continue, false , NULL ) == KERN_SUCCESS)); if (_wq_exiting(wq)) { goto unlock_and_exit; } req->tr_count = (uint16_t )reqcount; if (workq_threadreq_enqueue(wq, req)) { workq_schedule_creator(p, wq, WORKQ_THREADREQ_CAN_CREATE_THREADS); } workq_unlock(wq); return 0 ; unlock_and_exit: workq_unlock(wq); free_and_exit: zfree(workq_zone_threadreq, req); exit : return ret; }
从 workq_reqthreads 函数中 workqueue *wq 的获取方式:
1 2 struct workqueue *wq =
可以知道,每个进程都有一个共用的 workqueue。
从 workq_reqthreads 函数实现中可以看到有针对超额提交线程、受限线程等不同线程类型的处理逻辑,那超额提交线程、受限线程分别是什么呢?
GCD 在管理线程时,把线程大致分成了这么几类:
创建者线程(Creator Thread)
创建者线程是一个匿名线程,用来控制线程创建节奏。
workqueue 只会有一个创建者线程。创建者线程会被转换成普通工作线程传到用户态执行任务,并协调创建其他线程。
超额提交线程 (Overcommit Threads)
可以突破 CPU 最大并发限制的线程,可能会引发线程爆炸(Thread Explosion),导致上下文切换开销剧增。
串行队列是 Overcommit 的 ,所以串行队列创建的是超额提交线程。
受限线程 (Constrained Threads)
根据 CPU 最大并发能力限制最大并行线程数量的线程,可以避免过度使用系统资源。
并发队列(含全局队列)是非 Overcommit 的 ,所以并发队列创建的是受限线程。
除此之外,还有管理线程、协作线程中,但这些不是本次分析的关注点。
在《GCD 底层原理 2 - dispatch_queue》 中已经得出过结论:并发队列是非 overcommit 的,串行队列是 overcommit 的。由于走进 workq_reqthreads 函数的主要是并发队列,所以这里只关注非 overcommit 的情况即可。
workq_reqthreads 中的线程请求逻辑中,根据请求的线程数量 reqcount 分成了两部分逻辑,根据两部分逻辑的特点,姑且称之为「快速请求流程」 和「慢速请求流程」 :
快速请求流程
为了能快速处理线程请求,加快线程调度速度。
当请求线程数量大于 1 时会先走快速请求流程。
慢速请求流程
更精细的线程调度方式,会根据所请求线程类型、优先级、CPU 负载情况,动态调整可创建线程数量。
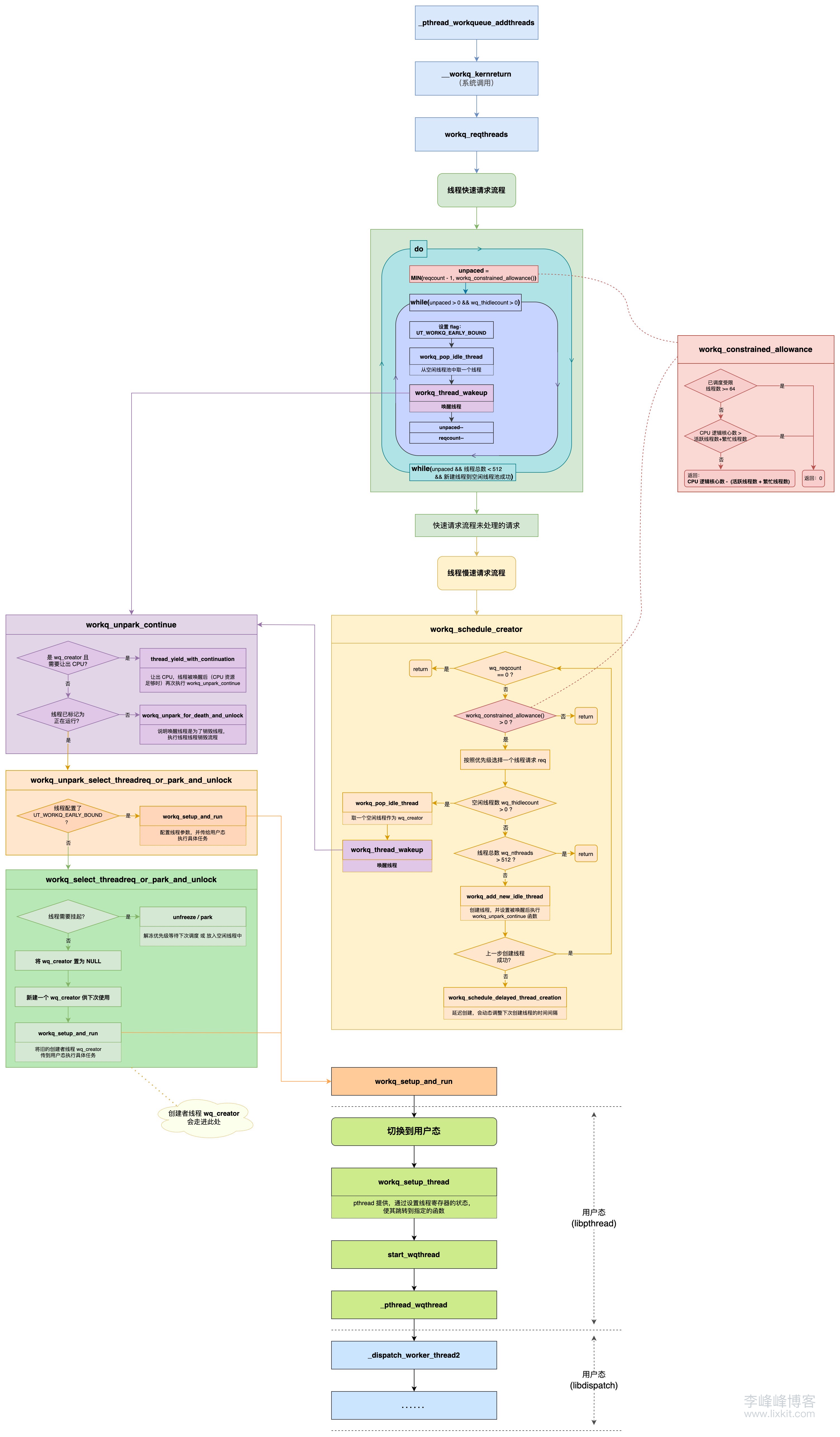
workq_reqthreads 函数核心逻辑如下:
获取当前进程的 workqueue *wq 根据请求线程的数量 reqcount 决定走「快速请求流程」还是「慢速请求流程」
unpaced = reqcount - 1 数量的请求走「快速请求流程」剩余的 1 个请求走「慢速请求流程」
快速请求流程
对于并发队列(队列是非 overcommit 的),则限制 unpaced 最大值为 CPU 逻辑核心数量
这里调用 workq_constrained_allowance 获取 unpaced 最大值,该函数返回结果是 CPU 逻辑核心的数量
如果线程池中的空闲线程数量 wq_thidlecount 足够,则通过 while 循环调用 workq_pop_idle_thread 从线程池中取 unpaced 个线程直接唤醒并使用。
如果线程池中的空闲线程已用完,且线程总数未达到上限 wq_max_threads(512),会调用 workq_add_new_idle_thread 创建新线程。否则将走慢速请求流程。
综上,对于并发队列,每次调用 workq_reqthreads,参与快速请求流程的线程请求数量最多是 CPU 逻辑核心的数量。
慢速请求流程
将线程请求入队,并调用 workq_schedule_creator 调度线程
但是,需要注意的是,并发队列调用 workq_reqthreads 时,reqcount 传入的参数是 1,且通过递归调用的方式多次调用 workq_reqthreads 每次申请一个线程(详情可看:《GCD 底层原理 4 - dispatch_async》 )。所以并发队列不会走进快速请求流程,而是直接走慢速请求流程。
4、workq_constrained_allowance workq_constrained_allowance 函数用于根据 CPU 最大并发能力(CPU 逻辑核心数量)及受限线程数量限制,计算 CGD 是否还允许创建受限线程。
上面已经提到,在快速请求流程中,会调用 workq_constrained_allowance 获取并发队列最大参与快速请求流程的请求数量。但该函数有必要单独拿出来讲一下,workq_constrained_allowance 函数精简后的实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 static uint32_t workq_constrained_allowance (struct workqueue *wq, thread_qos_t at_qos, struct uthread *uth, bool may_start_timer, bool record_failed_allowance) { assert(at_qos != WORKQ_THREAD_QOS_MANAGER); uint32_t allowance_passed = 0 ; uint32_t count = 0 ; uint32_t max_count = wq->wq_constrained_threads_scheduled; if (max_count >= wq_max_constrained_threads) { allowance_passed = 0 ; goto out; } max_count -= wq_max_constrained_threads; count = wq_max_parallelism[_wq_bucket(at_qos)]; if (count > thactive_count + busycount) { count -= thactive_count + busycount; allowance_passed = MIN(count, max_count); goto out; } else { allowance_passed = 0 ; } return allowance_passed; }
其中,wq_max_parallelism 是个数组,在 workq_open 函数(pthread_workqueue_setup 中调用的该函数)中初始化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 int workq_open (struct proc *p, __unused struct workq_open_args *uap, __unused int32_t *retval) { if (wq_init_constrained_limit) { for (thread_qos_t qos = WORKQ_THREAD_QOS_MIN; qos <= WORKQ_THREAD_QOS_MAX; qos++) { wq_max_parallelism[_wq_bucket(qos)] = qos_max_parallelism(qos, QOS_PARALLELISM_COUNT_LOGICAL); } } return error; } uint32_t qos_max_parallelism (int qos, uint64_t options) { return SCHED(qos_max_parallelism)(qos, options); } uint32_t sched_qos_max_parallelism (__unused int qos, uint64_t options) { if (options & QOS_PARALLELISM_COUNT_LOGICAL) { return hinfo.logical_cpu; } else { return hinfo.physical_cpu; } }
注意,workq_constrained_allowance 函数中,有一段这样的逻辑:
1 2 3 4 5 6 7 8 9 10 if (max_count >= wq_max_constrained_threads) { goto out; } max_count -= wq_max_constrained_threads;
在计算 max_count 时,max_count 一定是小于 wq_max_constrained_threads 的,而 max_count 和 wq_max_constrained_threads 都是 uint32_t 类型(无符号整数),当一个较小的无符号整数减去一个较大的无符号整数时,会发生下溢,导致 max_count 变成一个很大的正数。
这个 XNU 的 BUG 则导致了后续 MIN(count, max_count) 结果一定是 count,即:
1 count -= thactive_count + busycount = CPU 逻辑核心数 - (活跃线程数 + 繁忙线程数);
从而导致了 workq_constrained_allowance 返回值一定是上面的计算结果,使 MIN(count, max_count) 的逻辑变得无意义。
更合理的计算方式应该是:
1 2 max_count = wq_max_constrained_threads - max_count;
综上,workq_constrained_allowance 核心逻辑如下:
如果已调度受限线程数超过超过最大受限线程数(64),则不允许再新建线程,直接返回 0。
否则,判断是否满足 CPU 逻辑核心数 > (活跃线程数 + 繁忙线程数),
如果满足,返回:CPU 逻辑核心数 - (活跃线程数 + 繁忙线程数)
如果不满足,返回 0,即不允许再创建线程
活跃线程与繁忙线程:
活跃线程
正在执行任务(未被阻塞或挂起)的工作队列线程。
活跃线程会占用 CPU 资源,所以需要严格控制活跃线程数量。
繁忙线程
线程被阻塞在时间窗口内(被阻塞的时间小于 200 微秒)的线程。
这部分判断逻辑在 workq_thread_is_busy 函数中实现的。
系统会记录线程阻塞的时间,如果线程在短时间窗口内被阻塞,会被视为”繁忙”线程,因为线程可能会很快被唤醒执行任务。繁忙线程本身不会消耗 CPU 资源。
如果线程一直被阻塞,阻塞时间超过了时间窗口 200 微秒,则不统计在内了。
5、慢速请求流程(workq_schedule_creator) 上面已经提到,并发队列调用 workq_reqthreads 时,reqcount 传入的参数是 1,且通过递归调用的方式多次调用 workq_reqthreads 每次申请 1 个线程(详情可看:《GCD 底层原理 4 - dispatch_async》 )。所以并发队列不会走进快速请求流程,而是直接走慢速请求流程。
慢速请求流程调用的是 workq_schedule_creator,该函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 static void workq_schedule_creator (proc_t p, struct workqueue *wq, workq_kern_threadreq_flags_t flags) { workq_threadreq_t req; struct uthread *uth ; bool needs_wakeup; again: uth = wq->wq_creator; if (!wq->wq_reqcount) { return ; } req = workq_threadreq_select_for_creator(wq); if (req == NULL ) { return ; } if (uth) { if (workq_thread_needs_priority_change(req, uth)) { workq_thread_reset_pri(wq, uth, req, true ); } assert(wq->wq_inheritor == get_machthread(uth)); } else if (wq->wq_thidlecount) { wq->wq_creator = uth = workq_pop_idle_thread(wq, UT_WORKQ_OVERCOMMIT, &needs_wakeup); if (needs_wakeup) { workq_thread_wakeup(uth); } } else { if (__improbable(wq->wq_nthreads >= wq_max_threads)) { } else if (flags & WORKQ_THREADREQ_SET_AST_ON_FAILURE) { } else if (!(flags & WORKQ_THREADREQ_CAN_CREATE_THREADS)) { workq_schedule_immediate_thread_creation(wq); } else if ((workq_add_new_idle_thread(p, wq, workq_unpark_continue, false , NULL ) == KERN_SUCCESS)) { goto again; } else { workq_schedule_delayed_thread_creation(wq, 0 ); } } }
在 workq_schedule_creator 函数中,多次提到线程(uth)和线程请求(thread request),线程和线程请求到底是什么关系呢?
线程(uth)
线程(uth)是线程在内核态的形态,线程(uth)回传回用户空间,执行我们通过 dispatch_async 的 block 提交的具体任务。
线程请求(thread request)
线程请求(thread request)是任务在内核层面的描述,它不包含实际的 dispatch_async 的 block 任务,而是包含执行该任务所需的元数据,如 QoS、优先级、执行模式等。
线程(uth)需要根据线程请求(thread request)完成执行参数配置之后,才能提供给用户态执行任务。
总结 workq_schedule_creator 函数逻辑如下:
如果进程 workqueue 的线程请求数量为 0,直接 return。
根据请求线程的优先级,调用 workq_threadreq_select_for_creator 按照高优先级优先的原则,为创建者线程选择一个合适的线程请求 req。
选择线程请求时,会调用前面提到的 workq_constrained_allowance 判断是否还允许创建受限线程,如果不可以再创建线程,workq_threadreq_select_for_creator 会返回 NULL。
如果 req 为 NULL,则 workq_schedule_creator 函数会直接 return。
如果创建者线程 wq_creator 已存在,根据线程请求 req 调整其优先级等参数。
如果创建者线程 wq_creator 不存在,则进入 wq_creator 创建流程:
步骤 1: 是否有空闲线程,如果有,则调用 workq_pop_idle_thread 取一个空闲线程作为 wq_creator,并调用 workq_thread_wakeup 唤醒创建者线程 wq_creator。步骤 2: 如果没有空闲线程,再判断当前线程总数是否已经达到 wq_max_threads(512),如果达到,不允许再创建 wq_creator。步骤 3: 如果线程总数未达到 wq_max_threads(512),则:
调用 workq_add_new_idle_thread 创建线程,并设置线程被唤醒后执行 workq_unpark_continue 函数。
执行 goto again,会前面重新走 wq_creator 创建流程,并在上面步骤 1 时,将这一步新建的线程作为空闲线程赋值给 wq_creator 并唤醒。
步骤 4: 走到这里,说明由于前面各种条件限制,不允许再新建线程,则调用 workq_schedule_delayed_thread_creation 走延迟创建逻辑。
在工作队列中安排一个延迟执行的线程创建任务。它会根据工作队列的当前状态和历史运行情况动态调整下次创建线程的时间间隔,实现自适应的线程创建策略。
其中,从线程池取一个空闲线程调用的是 workq_pop_idle_thread 函数,该函数精简后实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 static struct uthread *workq_pop_idle_thread (struct workqueue *wq, uint16_t uu_flags, bool *needs_wakeup) { struct uthread *uth ; if ((uth = TAILQ_FIRST(&wq->wq_thidlelist))) { TAILQ_REMOVE(&wq->wq_thidlelist, uth, uu_workq_entry); } else { uth = TAILQ_FIRST(&wq->wq_thnewlist); TAILQ_REMOVE(&wq->wq_thnewlist, uth, uu_workq_entry); } uth->uu_workq_flags |= UT_WORKQ_RUNNING | uu_flags; wq->wq_threads_scheduled++; wq->wq_thidlecount--; return uth; }
从源码实现可知,取空闲线程的关键逻辑如下:
先从空闲线程 wq_thidlelist 里取一个线程。
空闲线程为空,则从新建线程链表 wq_thnewlist 中取一个线程。
workq_add_new_idle_thread 新建的线程会存到 wq_thnewlist 里。
将取到的线程标记为运行状态,增加 UT_WORKQ_RUNNING 标记。
所以,创建者线程 wq_creator 也会有 UT_WORKQ_RUNNING 标记。
已调度线程数量 wq_threads_scheduled ++,空闲线程数量 wq_thidlecount --。
返回取到的空闲线程。
6、workq_unpark_continue 创建者线程 wq_creator 创建完成被唤醒后,会调用 workq_unpark_continue 函数。workq_unpark_continue 函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 static void workq_unpark_continue (void *parameter __unused, wait_result_t wr __unused) { thread_t th = current_thread(); struct uthread *uth = proc_t p = current_proc(); struct workqueue *wq = workq_lock_spin(wq); if (wq->wq_creator == uth && workq_creator_should_yield(wq, uth)) { uth->uu_save.uus_workq_park_data.fulfilled_snapshot = wq->wq_fulfilled; uth->uu_save.uus_workq_park_data.yields++; workq_unlock(wq); thread_yield_with_continuation(workq_unpark_continue, NULL ); __builtin_unreachable(); } if (__probable(uth->uu_workq_flags & UT_WORKQ_RUNNING)) { workq_unpark_select_threadreq_or_park_and_unlock(p, wq, uth, WQ_SETUP_NONE); __builtin_unreachable(); } if (__probable(wr == THREAD_AWAKENED)) { assert(uth->uu_workq_flags & UT_WORKQ_DYING); assert((uth->uu_workq_flags & UT_WORKQ_NEW) == 0 ); } else { assert(wr == THREAD_INTERRUPTED); wq->wq_thdying_count++; uth->uu_workq_flags |= UT_WORKQ_DYING; } workq_unpark_for_death_and_unlock(p, wq, uth, WORKQ_UNPARK_FOR_DEATH_WAS_IDLE, WQ_SETUP_NONE); __builtin_unreachable(); }
在该函数中,多次出现了:
1 __builtin_unreachable();
是 GCC 和 Clang 编译器提供的一个内建函数,用于告诉编译器程序的某个代码路径是不可达的。如果代码在运行时真的到达了__builtin_unreachable(),会导致崩溃或其他未定义行为:
而在 workq_unpark_continue 函数中,实际上是不会执行到 __builtin_unreachable() 的,因为 __builtin_unreachable() 上面所调用的函数,都是 noreturn 的,进去后就出不来了 。
总结 workq_unpark_continue 函数实现如下:
如果线程是创建者线程 wq_creator,则判断是否需要让出 CPU,如果需要,则让出 CPU 且使其被唤醒后(CPU 资源足够时)再次执行 workq_unpark_continue,并终止 workq_unpark_continue 执行。
当正在工作的线程(占用 CPU)数量,超过了最大并发线程数(CPU 逻辑核心数量),则需要让出 CPU。
如果线程被标记为运行状态(含 UT_WORKQ_RUNNING 标记),则调用 workq_unpark_select_threadreq_or_park_and_unlock 选择一个线程请求处理或挂起线程。
所以,对于创建者线程 wq_creator,也会走此逻辑。
否则,线程被唤醒是为了销毁线程,执行线程销毁的逻辑。
7、workq_unpark_select_threadreq_or_park_and_unlock 上一步提到,如果线程被标记为运行状态(含 UT_WORKQ_RUNNING 标记),则调用 workq_unpark_select_threadreq_or_park_and_unlock 选择一个线程请求处理或挂起线程,在前面已经提到,选择一个线程请求处理就是根据线程请求进行执行参数配置,完成参数配置之后,就会将配置好的线程传给用户态去执行具体任务。
分析源码后确认,只有 workq_pop_idle_thread 会增加 UT_WORKQ_RUNNING 标记,即从空闲线程中取出线程时增加了 UT_WORKQ_RUNNING 标记:
快速请求流程中,从空闲线程取线程使用时。
慢速请求流程中,创建 wq_creator 时。
所以,在上述两个场景中,都会走进 workq_unpark_select_threadreq_or_park_and_unlock 函数。
workq_unpark_select_threadreq_or_park_and_unlock 函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 static void workq_unpark_select_threadreq_or_park_and_unlock (proc_t p, struct workqueue *wq, struct uthread *uth, uint32_t setup_flags) { if (uth->uu_workq_flags & UT_WORKQ_EARLY_BOUND) { if (uth->uu_workq_flags & UT_WORKQ_NEW) { setup_flags |= WQ_SETUP_FIRST_USE; } uth->uu_workq_flags &= ~(UT_WORKQ_NEW | UT_WORKQ_EARLY_BOUND); workq_setup_and_run(p, uth, setup_flags); __builtin_unreachable(); } thread_freeze_base_pri(get_machthread(uth)); workq_select_threadreq_or_park_and_unlock(p, wq, uth, setup_flags); }
该函数可以分成两个逻辑分支:
逻辑分支 1: 配置线程并传给用户态执行具体任务。
当线程配置了 UT_WORKQ_EARLY_BOUND 标志时,会走该逻辑分支。
只有 workq_reqthreads 中取空闲线程后会设置 UT_WORKQ_EARLY_BOUND,所以快速请求流程获取到的线程走此逻辑分支。
此逻辑分支核心逻辑是调用 workq_setup_and_run 将线程传给用户态执行具体任务。
逻辑分支 2: 选择线程请求处理或挂起线程。
由于创建 wq_creator 时,未无 UT_WORKQ_EARLY_BOUND,所以创建者线程 wq_creator 会走此分支。
此处调用的是 workq_select_threadreq_or_park_and_unlock 函数
8、workq_select_threadreq_or_park_and_unlock 上面已经提到,创建线程 wq_creator 被唤醒后,最终会执行到 workq_select_threadreq_or_park_and_unlock 函数,选择一个线程请求处理,或者挂起线程。该函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 static void workq_select_threadreq_or_park_and_unlock (proc_t p, struct workqueue *wq, struct uthread *uth, uint32_t setup_flags) { workq_threadreq_t req = NULL ; bool is_creator = (wq->wq_creator == uth); bool schedule_creator = false ; if (......) { goto park; } if (is_creator) { wq->wq_creator = NULL ; } if (......) { goto park_thawed; } wq->wq_fulfilled++; schedule_creator = workq_threadreq_dequeue(wq, req, cooperative_sched_count_changed); if (is_creator || schedule_creator) { workq_schedule_creator(p, wq, WORKQ_THREADREQ_CAN_CREATE_THREADS); } workq_unlock(wq); if (req) { zfree(workq_zone_threadreq, req); } workq_setup_and_run(p, uth, setup_flags); __builtin_unreachable(); park: thread_unfreeze_base_pri(get_machthread(uth)); park_thawed: workq_park_and_unlock(p, wq, uth, setup_flags); }
从上述逻辑可知,当线程需要挂起时(例如:队列正在退出、没有线程请求或达到最大并发数量限制时),会将创建者线程 wq_creator 挂起(解冻优先级等待下次调度或放入空闲线程中)。否则,将:
先将 workqueue 的 wq_creator 置为 NULL。
新建一个创建者线程 wq_creator 供下次使用。
将调用 workq_setup_and_run 将旧的创建者线程 wq_creator 传到用户态执行具体任务。
所以,这里就看出了创建者线程 wq_creator 的工作流程:作为工作线程传到用户态执行具体任务,并再次通过慢速请求流程创建一个新的创建者线程 wq_creator,循环执行此 wq_creator 的工作。
9、workq_setup_and_run 根据前面逻辑分析结果,有两种场景会调用 workq_setup_and_run 函数:
快速请求流程,从空闲线程中取出线程使用时。 慢速请求流程,创建者线程 wq_creator 处理线程请求时。
workq_setup_and_run 函数主要作用是配置线程,并将线程传到用户态执行具体任务。该函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 static void workq_setup_and_run (proc_t p, struct uthread *uth, int setup_flags) { pthread_functions->workq_setup_thread(p, th, vmap, uth->uu_workq_stackaddr, uth->uu_workq_thport, 0 , setup_flags, upcall_flags); __builtin_unreachable(); }
其中,workq_setup_thread 函数是由 pthread 提供的,在 libpthread 开源仓库中。workq_setup_thread 的主要逻辑是通过设置线程寄存器的状态,使其跳转到指定的函数,这里函数主要执行路径是:
1 2 3 4 5 start_wqthread ⬇️ _pthread_wqthread ⬇️ _dispatch_worker_thread2
到这里,就和上篇文章《GCD 底层原理 4 - dispatch_async》 )中并发队列申请线程并执行任务的内容对应上了。
10、总结 可以使用下图表示并发队列线程池管理逻辑:
四、串行队列申请线程 上篇文章《GCD 底层原理 4 - dispatch_async》 )中有分析过,串行队列是基于 Workloop 的,通过 kevent_id 系统调用的方式申请线程。并且对于串行队列,当有任务需要执行时,每个串行队列只会开启一个线程去执行任务。从这一点其实也可看出,队列、Workloop、线程是一一对应且绑定的。
根据前面测试结果也可以看出,虽然每个串行队列在执行任务期间只会创建一个线程,但是有很多个不同的串行队列时,就可以创建很多个线程,最高可以创建 512 个线程,可以超过 CPU 逻辑核心数量。
而并发队列却需要考虑 CPU 负载情况,限制了最大并发线程数量不超过 CPU 逻辑核心数量,且线程总数不超过 64 个,XNU 这么设计,至少有下面两个好处:
每个串行队列在任一时刻只有一个任务在执行,对 CPU 的消耗相对较少,系统需要确保足够的线程资源使串行队列不被阻塞,如果限制太严格,可能导致队列任务无法及时调度。
并发队列主要为计算密集型任务设计,目标是最大化 CPU 利用率,超过 CPU 逻辑核心数量的线程会增加上下文切换成本,会导致性能的降低。所以需要限制线程数量以确保 CPU 能高性能处理任务。
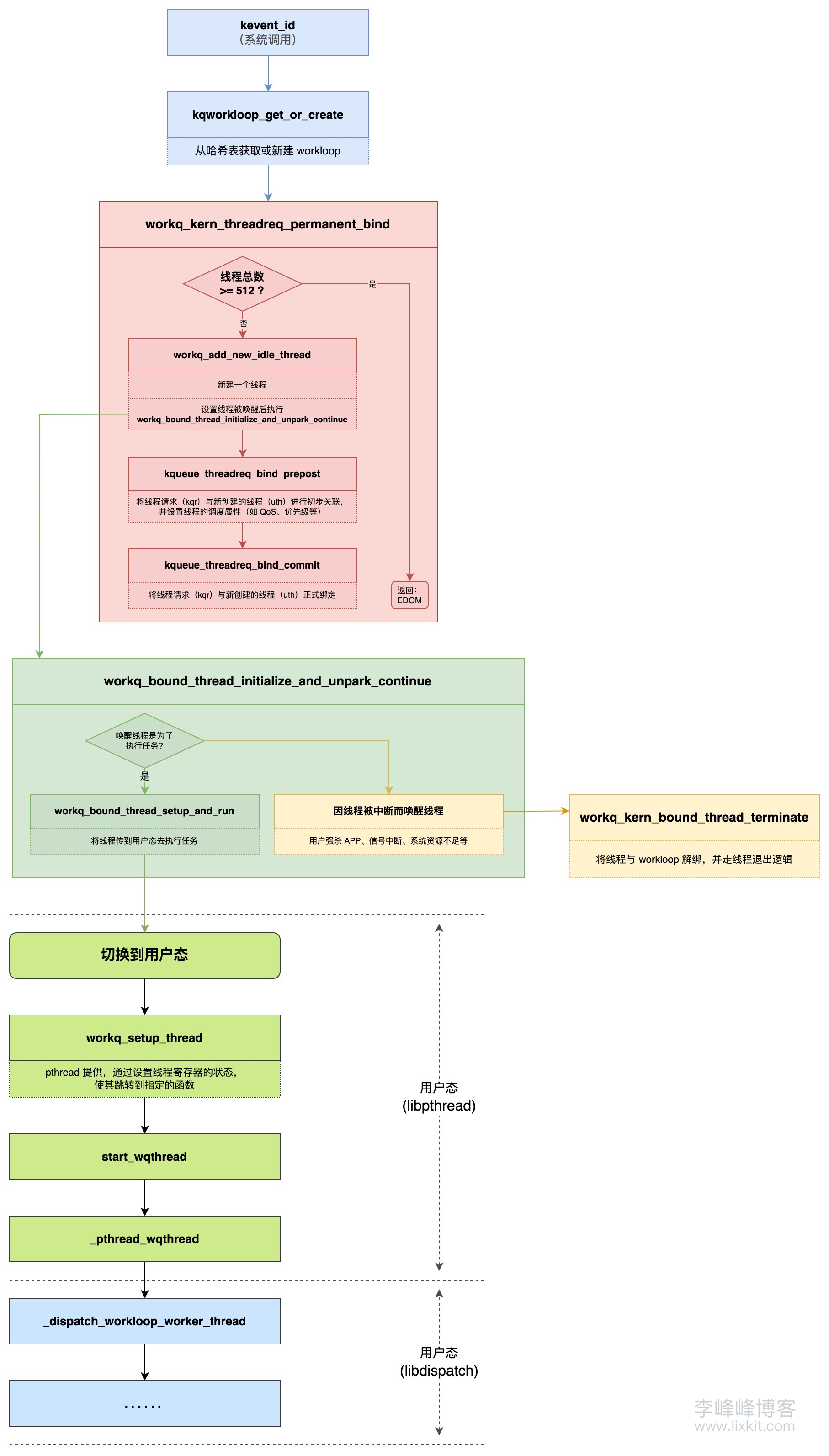
1、kevent_id 串行队列是基于 Workloop 并通过 kevent_id 系统调用的方式申请线程的,kevent_id 函数主要逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 int kevent_id (struct proc *p, struct kevent_id_args *uap, int32_t *retval) { uthread_t uth = current_uthread(); workq_threadreq_t kqr = uth->uu_kqr_bound; kqu.kqwl = kqr ? kqr_kqworkloop(kqr) : NULL ; if (kqu.kqwl && kqu.kqwl->kqwl_dynamicid == uap->id) { kqworkloop_retain(kqu.kqwl); } else if (__improbable(kevent_args_requesting_events(flags, uap->nevents))) { return EXDEV; } else { error = kqworkloop_get_or_create(p, uap->id, NULL , NULL , flags, &kqu.kqwl); if (__improbable(error)) { return error; } } return kevent_modern_internal(kqu, uap->changelist, uap->nchanges, uap->eventlist, uap->nevents, flags, kectx, retval); }
上述主要逻辑是根据工作队列线程请求判断对应的 workloop 是否存在,如果不存在则新建,如果存在则直接获取。其中,是通过调用 kqworkloop_get_or_create 函数获取或新建 workloop 的。
2、kqworkloop_get_or_create kqworkloop_get_or_create 函数用于获取或新建 workloop,该函数主要实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 static int kqworkloop_get_or_create (struct proc *p, kqueue_id_t id, workq_threadreq_param_t *trp, struct workq_threadreq_extended_param_s *trp_extended, unsigned int flags, struct kqworkloop **kqwlp) { struct filedesc *fdp = for (;;) { kqhash_lock(fdp); if (__improbable(fdp->fd_kqhash == NULL )) { kqworkloop_hash_init(fdp); } kqwl = kqworkloop_hash_lookup_locked(fdp, id); if (kqwl) { break ; } if (__probable(alloc_kqwl == NULL )) { alloc_kqwl = zalloc_flags(kqworkloop_zone, Z_NOWAIT | Z_ZERO); } if (__probable(alloc_kqwl)) { kqworkloop_hash_insert_locked(fdp, id, alloc_kqwl); kqhash_unlock(fdp); if (trp && (trp->trp_flags & TRP_BOUND_THREAD)) { error = workq_kern_threadreq_permanent_bind(p, &alloc_kqwl->kqwl_request); if (error != KERN_SUCCESS) { kqworkloop_release(alloc_kqwl); alloc_kqwl = NULL ; return error; } else { } } *kqwlp = alloc_kqwl; return 0 ; } } kqhash_unlock(fdp); return error; }
从该函数中可以看出队列对应的 workloop 存储在哈希表中,workloop 获取和新建逻辑如下:
判断哈希表是否初始化,如果没有则先初始化。
根据队列 id 从哈希表中获取 workloop。
如果哈希表中没找到,则新建一个 workloop,同时:
将新建的 workloop 插入哈希表。
调用 workq_kern_threadreq_permanent_bind 函数申请线程,并将线程与 workloop 绑定。
调用 workq_kern_threadreq_permanent_bind 时,传入的线程请求(kqr)是从 workloop 中获取的(&alloc_kqwl->kqwl_request)。所以线程请求(kqr)已经和 workloop 是绑定的关系。
3、workq_kern_threadreq_permanent_bind 关于该函数,源码中给出了注释去解释该函数的作用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 /* * An entry point for kevent to request a newly created workqueue thread * and bind it permanently to the given workqueue thread request. * * It currently only supports fixed scheduler priority thread requests. * * The newly created thread counts towards wq_nthreads. This function returns * an error if we are above that limit. There is no concept of delayed thread * creation for such specially configured kqworkloops. * * If successful, the newly created thread will be parked in * workq_bound_thread_initialize_and_unpark_continue waiting for * new incoming events. */
即该函数是通过 kevent/kevent_id 请求线程的入口点,会将线程、线程请求、workloop 进行绑定。新创建的线程计入 wq_nthreads。新创建的线程将在有任务需要处理时候,会被唤醒并调用 workq_bound_thread_initialize_and_unpark_continue 函数。
workq_kern_threadreq_permanent_bind 函数主要实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 kern_return_t workq_kern_threadreq_permanent_bind (struct proc *p, struct workq_threadreq_s *kqr) { kern_return_t ret = 0 ; thread_t new_thread = NULL ; struct workqueue *wq = workq_lock_spin(wq); if (wq->wq_nthreads >= wq_max_threads) { ret = EDOM; } else { if (kqr->tr_flags & WORKQ_TR_FLAG_WL_OUTSIDE_QOS) { workq_threadreq_param_t trp = kqueue_threadreq_workloop_param(kqr); thread_qos_t qos = thread_workq_qos_for_pri(trp.trp_pri); if (qos == THREAD_QOS_UNSPECIFIED) { qos = WORKQ_THREAD_QOS_ABOVEUI; } kqr->tr_qos = qos; } kqr->tr_count = 1 ; ret = workq_add_new_idle_thread(p, wq, workq_bound_thread_initialize_and_unpark_continue, true , &new_thread); if (ret == KERN_SUCCESS) { struct uthread *uth = if (kqr->tr_flags & WORKQ_TR_FLAG_WL_OUTSIDE_QOS) { workq_thread_reset_pri(wq, uth, kqr, true ); } kqueue_threadreq_bind_prepost(p, kqr, uth); uth->uu_workq_flags |= UT_WORKQ_PERMANENT_BIND; } } workq_unlock(wq); if (ret == KERN_SUCCESS) { kqueue_threadreq_bind_commit(p, new_thread); } return ret; }
总结该函数逻辑如下:
判断当前线程总数 wq_nthreads 是否大于等于 wq_max_threads(512),如果达到了上限数量 512,则不允许再新建线程。
等待有线程释放后再被调度获取线程。
前面并发队列申请的线程,也会增加 wq_nthreads 计数,这就是一开始的测试中串行队列、并发队列一起使用时,线程总数仍然不能超过 512 的原因。
如果线程总数未达上限 512,则调用 workq_add_new_idle_thread 新建一个线程,并设置线程被唤醒后执行 workq_bound_thread_initialize_and_unpark_continue 函数。 将线程请求(kqr)与新创建的线程(uth)进行初步关联,并设置线程的调度属性(如 QoS、优先级等),为后续的 kqr、uth 正式绑定提交做好准备。
将线程请求(kqr)与新创建的线程(uth)正式绑定。
由于线程请求(kqr)已经和 workloop 是绑定的关系了,所以这一步实际上也是将线程(uth)与 workloop 进行绑定。
4、workq_bound_thread_initialize_and_unpark_continue 前面创建的线程将在有任务需要处理时候,会被唤醒并调用 workq_bound_thread_initialize_and_unpark_continue 函数,该函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 static void workq_bound_thread_initialize_and_unpark_continue (void *parameter __unused, wait_result_t wr) { struct uthread *uth = if (__probable(wr == THREAD_AWAKENED)) { assert((uth->uu_workq_flags & (UT_WORKQ_RUNNING | UT_WORKQ_DYING)) != (UT_WORKQ_RUNNING | UT_WORKQ_DYING)); assert(workq_thread_is_permanently_bound(uth)); if (uth->uu_workq_flags & UT_WORKQ_RUNNING) { assert(uth->uu_workq_flags & UT_WORKQ_NEW); uth->uu_workq_flags &= ~UT_WORKQ_NEW; struct workq_threadreq_s *kqr = if (kqr->tr_work_interval) { kern_return_t kr; kr = kern_work_interval_explicit_join(get_machthread(uth), kqr->tr_work_interval); if (kr == KERN_SUCCESS) { uth->uu_workq_flags |= UT_WORKQ_WORK_INTERVAL_JOINED; } else { uth->uu_workq_flags |= UT_WORKQ_WORK_INTERVAL_FAILED; } } workq_thread_reset_cpupercent(kqr, uth); workq_bound_thread_setup_and_run(uth, WQ_SETUP_FIRST_USE); __builtin_unreachable(); } else { assert(uth->uu_workq_flags & UT_WORKQ_DYING); } } else { assert(wr == THREAD_INTERRUPTED); proc_t p = current_proc(); struct workqueue *wq = workq_lock_spin(wq); assert(workq_thread_is_permanently_bound(uth)); workq_unlock(wq); kqueue_threadreq_bind_commit(p, get_machthread(uth)); } workq_kern_bound_thread_terminate(uth->uu_kqr_bound); __builtin_unreachable(); }
该函数核心逻辑如下:
如果唤醒线程是为了执行任务,则调用 workq_bound_thread_setup_and_run 将线程传到用户态去执行任务。
如果唤醒线程,是因为线程被中断(INTERRUPTED),则将线程与 workloop 解绑,并走线程退出逻辑。
如下场景会导致线程被中断:
用户强制杀死 APP。
用户态 APP 主动调用 exit() 或 abort() 终止进程。
用户态 APP 注册了信号处理程序,但未处理某些信号(如 SIGKILL),当这些信号到达时,线程会被中断。
在高并发场景下,APP 创建了大量线程,导致系统资源耗尽。
其中,workq_bound_thread_setup_and_run 内部最终还是通过前面分析过的 workq_setup_thread 将任务传到 pthread 的。workq_setup_thread 的主要逻辑是通过设置线程寄存器的状态,使其跳转到指定的函数,对于串行队列,函数主要执行路径是:
1 2 3 4 5 start_wqthread ⬇️ _pthread_wqthread ⬇️ _dispatch_workloop_worker_thread
后续就是串行队列中具体任务的执行逻辑了,详见《GCD 底层原理 4 - dispatch_async》 。
到这里,应该都可以发现串行队列、并发队列在申请线程上,除了最大线程数量的差异,还有个请求路径上的差异:串行队列是直接通过 kevent_id 系统调用申请线程的,而并发队列是先调用 pthread 提供的 _pthread_workqueue_addthreads 函数申请线程,再由该函数进入内核态申请线程,两者差异可以用下图表示:
5、总结 从线程申请逻辑上看,串行队列申请线程要比并发队列简单的多,可以用下图总结串行队列线程管理的流程: