一、概述 单例在 iOS 中应用广泛,常用于管理全局的资源,如应用程序的配置信息、数据库管理、网络请求管理器等。dispatch_once 常被用来实现单例,如下是创建单例的一个最基本的用法:
1 2 3 4 5 6 7 8 9 10 11 12 @implementation TestObject + (instancetype )sharedInstance { static TestObject *instance; static dispatch_once_t onceToken; dispatch_once (&onceToken, ^{ instance = [[TestObject alloc] init]; }); return instance; } @end
通过使用 dispatch_once 和静态变量,可以确保在多线程环境下,TestObject 类的实例只会被创建一次。这种实现方式是线程安全的,并且是 Objective-C 中实现单例模式的标准方法。
二、实现原理 libdispatch 是 Apple 的 Grand Central Dispatch (GCD) 的实现库,libdispatch 提供了用于在多核硬件上执行并发代码的基础设施。
dispatch_once 是 libdispatch 提供的一个函数,用于确保某段代码在程序的生命周期内只执行一次。通过使用 dispatch_once,开发者可以轻松实现线程安全的初始化逻辑,而无需担心多线程环境下的竞态条件。
libdispatch 是开源的:apple-oss-distributions/libdispatch ,接下来,通过 libdispatch 源码,看下 dispatch_once 实现原理。
1、dispatch_once dispatch_once 实现源码如下:
1 2 3 4 5 6 7 8 typedef intptr_t dispatch_once_t ;typedef void (^dispatch_block_t ) (void ) ;void dispatch_once (dispatch_once_t *val, dispatch_block_t block) { dispatch_once_f(val, block, _dispatch_Block_invoke(block)); }
dispatch_once 主要有两个参数:
val
val 是一个指向整数类型的指针。
dispatch_once_t 是 intptr_t 类型,intptr_t 实际上是个有符号整数类型。
在后续逻辑中,val 会被转成联合体 dispatch_once_gate_t,并借助其中的成员 dgo_once 标识 block 是否已经执行过。
block
2、dispatch_once_f dispatch_once 中主要调用了 dispatch_once_f 函数,dispatch_once_f 实现如下:
1 2 3 4 5 6 7 8 9 10 void dispatch_once_f (dispatch_once_t *val, void *ctxt, dispatch_function_t func) { dispatch_once_gate_t l = (dispatch_once_gate_t )val; if (_dispatch_once_gate_tryenter(l)) { return _dispatch_once_callout(l, ctxt, func); } return _dispatch_once_wait(l); }
dispatch_once_gate_t 是指向 dispatch_once_gate_s 结构体的指针:
1 2 3 4 5 6 7 8 9 10 11 12 typedef uint32_t dispatch_lock;typedef struct dispatch_gate_s { dispatch_lock dgl_lock; } dispatch_gate_s, *dispatch_gate_t ; typedef struct dispatch_once_gate_s { union { dispatch_gate_s dgo_gate; uintptr_t dgo_once; }; } dispatch_once_gate_s, *dispatch_once_gate_t ;
dispatch_once_gate_s 是一个联合体,主要包含两个成员:
dgo_gate
dispatch_gate_s 结构体类型,该结构体中只有一个整数类型的成员 dgl_lock。dgo_gate 用于实现后续的锁机制。
dgo_once
3、_dispatch_once_gate_tryenter dispatch_once_f 内部首先调用 _dispatch_once_gate_tryenter 函数进行判断,_dispatch_once_gate_tryenter 实现如下:
1 2 3 4 5 6 static inline bool _dispatch_once_gate_tryenter(dispatch_once_gate_t l) { return os_atomic_cmpxchg(&l->dgo_once, DLOCK_ONCE_UNLOCKED, (uintptr_t )_dispatch_lock_value_for_self(), relaxed); }
其中,os_atomic_cmpxchg 是一个宏,其相关宏定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #define os_atomic_cmpxchg(p, e, v, m) \ ({ _os_atomic_basetypeof(p) _r = (e); \ atomic_compare_exchange_strong_explicit(_os_atomic_c11_atomic(p), \ &_r, v, memory_order_##m, memory_order_relaxed); }) #define _os_atomic_basetypeof(p) \ __typeof__(atomic_load_explicit(_os_atomic_c11_atomic(p), memory_order_relaxed)) #define atomic_load_explicit __c11_atomic_load #define _os_atomic_c11_atomic(p) \ ((__typeof__(*(p)) _Atomic *)(p)) #define atomic_compare_exchange_strong_explicit __c11_atomic_compare_exchange_strong
_dispatch_once_gate_tryenter 源码完全展开后,实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 DISPATCH_ALWAYS_INLINE static inline bool _dispatch_once_gate_tryenter(dispatch_once_gate_t l) { uintptr_t expected_value = DLOCK_ONCE_UNLOCKED; uintptr_t new_value = (uintptr_t )_dispatch_lock_value_for_self(); return atomic_compare_exchange_strong_explicit( ((__typeof__(l->dgo_once) _Atomic *)(&l->dgo_once)), &expected_value, new_value, memory_order_relaxed, memory_order_relaxed ); }
(1)atomic_compare_exchange_strong_explicit atomic_compare_exchange_strong_explicit 是 C11 标准中定义的一个原子操作函数,用于实现比较并交换(Compare and Swap, CAS)操作。
该函数的主要作用是比较一个原子变量的当前值与预期值,如果相等,则将其更新为新值。这个操作是原子的,意味着它在执行过程中不会被其他线程打断。
函数原型如下:
1 2 3 4 5 6 7 bool atomic_compare_exchange_strong_explicit ( atomic_type *obj, atomic_type *expected, atomic_type desired, memory_order success, memory_order failure ) ;
各参数含义:
atomic_type *obj
指向要操作的原子变量的指针。该变量的值将被比较并可能被更新。
aomic_type *expected
指向预期值的指针。如果 *obj 的值等于 *expected,则将 *obj 更新为 desired。如果不相等,*expected 将被更新为 *obj 的当前值。
atomic_type desired
新值,如果比较成功(即 *obj 的值等于 *expected),则将 *obj 更新为该值。
memory_order success
表示操作成功时的内存序,决定了其他线程对该操作的可见性。
memory_order failure
表示操作失败时的内存序。与成功时的内存序相似,决定了在操作未成功时的可见性。
atomic_compare_exchange_strong_explicit 函数作用如下:
该函数会检查原子变量 obj 的当前值是否等于给定的预期值 expected。如果相等,函数会将该原子变量的值更新为新的值 desired。
这个操作是原子的,意味着在执行过程中不会被其他线程打断,从而避免数据竞争和不一致性。
如果操作成功(即当前值等于预期值),函数返回 true,并且原子变量的值被更新为新值。
如果操作失败(即当前值不等于预期值),函数返回 false,并且预期值会被更新为当前值。
下面是参考 _dispatch_once_gate_tryenter 实现的一个 atomic_compare_exchange_strong_explicit 的简单示例,该示例和 _dispatch_once_gate_tryenter 一样,使用 memory_order_relaxed 内存序,多个线程并发修改共享的原子变量:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #include <stdio.h> #include <stdatomic.h> #include <pthread.h> atomic_int shared_value;void * thread_func (void * arg) { int expected = 0 ; int desired = 1 ; if (atomic_compare_exchange_strong_explicit(&shared_value, &expected, desired, memory_order_relaxed, memory_order_relaxed)) { printf ("线程 %ld: 成功将值从 0 改为 %d\n" , (long )arg, desired); } else { printf ("线程 %ld: 值未改变,当前值为 %d,预期值为 %d\n" , (long )arg, shared_value, expected); } return NULL ; } int main () { shared_value = ATOMIC_VAR_INIT(0 ); int threadCount = 10 ; pthread_t threads[threadCount]; for (long i = 0 ; i < threadCount; i++) { pthread_create(&threads[i], NULL , thread_func, (void *)i); } for (int i = 0 ; i < threadCount; i++) { pthread_join(threads[i], NULL ); } return 0 ; }
运行打印如下:atomic_compare_exchange_strong_explicit 原子操作使用 memory_order_relaxed 内存序时,多个线程可以并发执行这个原子操作,但最终只会有一个线程成功能操作成功。
(2)内存序 内存序使用的是 memory_order_relaxed,内存序(Memory Order)是多线程编程中的一个关键概念,它决定了在多线程环境中,如何保证内存操作的可见性和顺序性。在原子操作中,内存序用于指定操作的内存模型,以确保线程间的同步和数据一致性。C11 和 C++11 标准中定义了几种不同的内存序,memory_order_relaxed 是其中之一。
内存序主要有 6 种类型:
memory_order_relaxed
特点:不对其他内存操作施加顺序上的约束,即不保证操作的可见性和顺序性。
用途:适用于不需要同步的情况,只需要保证原子性。
性能:因为没有同步开销,通常具有较高的性能。
memory_order_consume
特点:确保依赖于加载结果的操作在加载之后执行。
用途:适用于需要依赖关系但不需要严格顺序的情况。
memory_order_acquire
特点:保证在此操作之后的读写不会被重排到此操作之前。
用途:用于加载操作,确保获取到最新的值。
memory_order_release
特点:保证在此操作之前的读写不会被重排到此操作之后。
用途:用于存储操作,确保对其他线程可见。
memory_order_acq_rel
特点:结合了 acquire 和 release 的特性。
用途:用于读-改-写操作,确保读写的顺序。
memory_order_seq_cst
特点:提供最强的顺序保证,所有操作按全局顺序执行。
用途:适用于需要严格顺序的场合,通常性能较低。
接下来,通过一个示例看下 memory_order_relaxed 的作用。
下面是一个计数器的示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include <stdio.h> #include <pthread.h> #define NUM_THREADS 4 #define NUM_INCREMENTS 1000000 int counter = 0 ; void * increment_counter (void * arg) { for (int i = 0 ; i < NUM_INCREMENTS; ++i) { counter++; } return NULL ; } int main () { pthread_t threads[NUM_THREADS]; for (int i = 0 ; i < NUM_THREADS; ++i) { pthread_create(&threads[i], NULL , increment_counter, NULL ); } for (int i = 0 ; i < NUM_THREADS; ++i) { pthread_join(threads[i], NULL ); } printf ("counter = %d\n" , counter); return 0 ; }
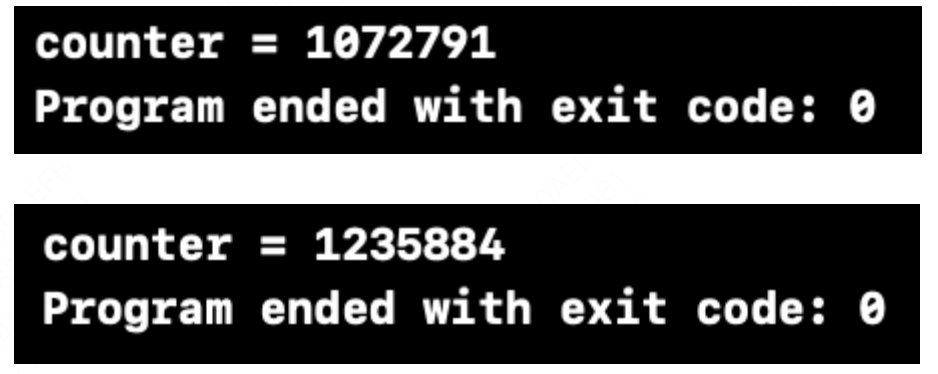
上述的主要逻辑是 4 个线程同时对一个共享的计数器 counter 进行递增操作。每个线程都会在一个循环中执行 1000000 次的 counter++ 操作。
符合预期的结果,运行结束 counter 应该等于 4000000,但实际上述代码每次运行结束 counter 结果都不相同:
主要原因是 counter++ 不是原子操作,多个线程同时修改 counter 会导致数据竞争,最终结果可能小于预期。
使用 memory_order_relaxed 可以解决问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <stdatomic.h> #include <stdio.h> #include <pthread.h> #define NUM_THREADS 4 #define NUM_INCREMENTS 1000000 atomic_int counter = 0 ; void * increment_counter (void * arg) { for (int i = 0 ; i < NUM_INCREMENTS; ++i) { atomic_fetch_add_explicit(&counter, 1 , memory_order_relaxed); } return NULL ; } int main () { pthread_t threads[NUM_THREADS]; for (int i = 0 ; i < NUM_THREADS; ++i) { pthread_create(&threads[i], NULL , increment_counter, NULL ); } for (int i = 0 ; i < NUM_THREADS; ++i) { pthread_join(threads[i], NULL ); } printf ("counter = %d\n" , counter); return 0 ; }
在上述使用 memory_order_relaxed 的示例中,无论运行多少次,都可以确保 counter 的值都是符合预期的。
memory_order_relaxed 保证了原子性,但不提供同步保证(即不强制其他线程立即看到更新),这意味着即使一个线程已经完成了对某个变量的更新,其他线程可能不会立即看到这个更新。由于没有同步开销,所以具有较高的性能,非常适合用于性能敏感的场景。
(3)_dispatch_lock_value_for_self() 其中,新值使用的是 _dispatch_lock_value_for_self(),其实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #define _dispatch_tid_self() ((dispatch_tid)_dispatch_thread_port()) #define _dispatch_thread_port() pthread_mach_thread_np(_dispatch_thread_self()) #define _dispatch_thread_self() ((uintptr_t)pthread_self()) typedef uint32_t mach_port_t ;typedef mach_port_t dispatch_tid;typedef uint32_t dispatch_lock;#define DLOCK_OWNER_MASK ((dispatch_lock)0xfffffffc) static inline dispatch_lock_dispatch_lock_value_for_self(void ) { return _dispatch_lock_value_from_tid(_dispatch_tid_self()); } static inline dispatch_lock_dispatch_lock_value_from_tid(dispatch_tid tid) { return tid & DLOCK_OWNER_MASK; }
_dispatch_lock_value_for_self 用于获取当前线程的“锁值”,这个“锁值”用于标识当前线程在锁机制中的身份。
_dispatch_lock_value_for_self 核心逻辑是通过一系列的宏和内联函数获取当前线程的唯一标识符 tid,再将线程标识符 tid 与 DLOCK_OWNER_MASK 进行按位与操作,生成最终的“锁值”。
(4)总结 _dispatch_once_gate_tryenter 根据前面内容对 _dispatch_once_gate_tryenter 总结如下:
该函数只有一个参数 dispatch_once_gate_t l:它是指向 dispatch_once_gate_s 结构的指针。
该函数调用 os_atomic_cmpxchg 宏,执行原子比较并交换操作,os_atomic_cmpxchg 宏展开后,实际调用的是前面提到的 atomic_compare_exchange_strong_explicit 函数。
总结该函数核心逻辑如下:
如果 &l->dgo_once 等于 DLOCK_ONCE_UNLOCKED,则将其更新为当前线程的锁值,并返回 true,表示当前线程可以进入一次性初始化的代码块。
获取当前线程的唯一标识符 tid,再将线程标识符 tid 与 DLOCK_OWNER_MASK 进行按位与操作,生成最终的“锁值”。
返回 true 将调用 _dispatch_once_callout(l, ctxt, func);
如果 &l->dgo_once 的值已经被其他线程修改(即不等于 DLOCK_ONCE_UNLOCKED),则返回 false,表示其他线程可能正在执行该代码块。
返回 false 将调用 _dispatch_once_wait(l)。
使用的内存序是 memory_order_relaxed,即**多个线程可以并发执行,但最终只会有一个线程执行成功并返回 true**。
从 dispatch_once_f 实现:
1 2 3 4 5 6 7 8 9 10 void dispatch_once_f (dispatch_once_t *val, void *ctxt, dispatch_function_t func) { dispatch_once_gate_t l = (dispatch_once_gate_t )val; if (_dispatch_once_gate_tryenter(l)) { return _dispatch_once_callout(l, ctxt, func); } return _dispatch_once_wait(l); }
可以知道,_dispatch_once_gate_tryenter 主要逻辑是判断进入一次性代码块,还是等待。
接下来看下代码块执行逻辑 _dispatch_once_callout 和 _dispatch_once_wait 的源码实现。
4、_dispatch_once_callout _dispatch_once_callout 函数实现如下:
1 2 3 4 5 6 7 static void _dispatch_once_callout(dispatch_once_gate_t l, void *ctxt, dispatch_function_t func) { _dispatch_client_callout(ctxt, func); _dispatch_once_gate_broadcast(l); }
该函数内部,调用了 _dispatch_client_callout、_dispatch_once_gate_broadcast 两个函数。
(1)_dispatch_client_callout _dispatch_client_callout 源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #define _dispatch_get_tsd_base() #define _dispatch_get_unwind_tsd() (NULL) #define _dispatch_set_unwind_tsd(u) do {(void)(u);} while (0) #define _dispatch_free_unwind_tsd() #define likely(x) __builtin_expect(!!(x), 1) #define unlikely(x) __builtin_expect(!!(x), 0) void _dispatch_client_callout(void *ctxt, dispatch_function_t f) { _dispatch_get_tsd_base(); void *u = _dispatch_get_unwind_tsd(); if (likely(!u)) return f(ctxt); _dispatch_set_unwind_tsd(NULL ); f(ctxt); _dispatch_free_unwind_tsd(); _dispatch_set_unwind_tsd(u); }
可以看到,_dispatch_client_callout 中核心逻辑主要是涉及到一系列 tsd 相关宏的调用,以及执行具体 block。
在该函数执行的宏定义中可以看到,这些宏实际上都是 NOOPs(无操作指令),可以理解为空的逻辑“没有任何作用”。那这些宏还有什么存在意义呢?
源码上方的注释给出了解释:
1 2 // On platforms with SjLj exceptions, avoid the SjLj overhead on every callout // by clearing the unwinder's TSD pointer to the handler stack around callouts
即:在具有 SjLj 异常的平台上,通过在调用过程中清除展开器的 TSD 指针到处理程序堆栈,避免每次调用的 SjLj 开销。
SjLj 是一种异常处理机制,主要用于不支持更高级异常处理的架构。它通过 setjmp 和 longjmp 函数实现异常捕获和跳转。setjmp 用于保存当前的堆栈状态,而 longjmp 用于恢复到之前保存的状态,从而实现异常处理。
每次调用 setjmp 时,都会有一定的开销,因为需要保存当前的堆栈上下文,包括寄存器状态和程序计数器等。在频繁调用的情况下,这种开销可能会显著影响性能。
对于现代硬件来说,这种对 TSD(线程安全数据)指针的 SjLj(Setjmp/Longjmp)优化是不必要的,这些 NOOPs(无操作指令)是故意而为之。
所以,可以理解为 _dispatch_client_callout 函数实现就是执行具体 block。
(2)_dispatch_once_gate_broadcast _dispatch_once_gate_broadcast 函数主要作用是在完成一次性初始化后,通知可能等待在该初始化完成的其他线程,该函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static inline void _dispatch_once_gate_broadcast(dispatch_once_gate_t l) { dispatch_lock value_self = _dispatch_lock_value_for_self(); uintptr_t v = _dispatch_once_mark_done(l); if (likely((dispatch_lock)v == value_self)) return ; _dispatch_gate_broadcast_slow(&l->dgo_gate, (dispatch_lock)v); }
其中 _dispatch_once_mark_done 函数实现逻辑如下:
1 2 3 4 5 static inline uintptr_t _dispatch_once_mark_done(dispatch_once_gate_t dgo) { return os_atomic_xchg(&dgo->dgo_once, DLOCK_ONCE_DONE, release); }
_dispatch_once_gate_broadcast 函数关键逻辑是在 _dispatch_client_callout 执行完 dispatch_once 具体 block 后,使用原子操作将 dgo_once 设置为 DLOCK_ONCE_DONE(记住这个操作,非常重要) 。
5、_dispatch_once_wait 再回头看下 dispatch_once_f 实现:
1 2 3 4 5 6 7 8 9 10 void dispatch_once_f (dispatch_once_t *val, void *ctxt, dispatch_function_t func) { dispatch_once_gate_t l = (dispatch_once_gate_t )val; if (_dispatch_once_gate_tryenter(l)) { return _dispatch_once_callout(l, ctxt, func); } return _dispatch_once_wait(l); }
根据前述内容可知,_dispatch_once_gate_tryenter 返回 false,则代表当前的这次调用没有获得 dispatch_once 的 block 执行权,则调用 _dispatch_once_wait 函数进入等待逻辑。
_dispatch_once_wait 函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 void _dispatch_once_wait(dispatch_once_gate_t dgo) { dispatch_lock self = _dispatch_lock_value_for_self(); uintptr_t old_v, new_v; uint32_t timeout = 1 ; for (;;) { os_atomic_rmw_loop(&dgo->dgo_once, old_v, new_v, relaxed, { if (likely(old_v == DLOCK_ONCE_DONE)) { os_atomic_rmw_loop_give_up(return ); } new_v = old_v | (uintptr_t )DLOCK_WAITERS_BIT; if (new_v == old_v) os_atomic_rmw_loop_give_up(break ); }); if (unlikely(_dispatch_lock_is_locked_by((dispatch_lock)old_v, self))) { DISPATCH_CLIENT_CRASH(0 , "trying to lock recursively" ); } _dispatch_thread_switch(new_v, 0 , timeout++); (void )timeout; } }
该函数中包含一系列宏定义,将该函数完全展开后逻辑如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 void _dispatch_once_wait(dispatch_once_gate_t dgo) { dispatch_lock self = _dispatch_lock_value_for_self(); uintptr_t old_v, new_v; uint32_t timeout = 1 ; for (;;) { bool _result = false ; __typeof__(&dgo->dgo_once) _p = (&dgo->dgo_once); old_v = os_atomic_load(_p, relaxed); do { if (likely(old_v == DLOCK_ONCE_DONE)) { os_atomic_thread_fence(relaxed); return ; } new_v = old_v | (uintptr_t )DLOCK_WAITERS_BIT; if (new_v == old_v) { os_atomic_thread_fence(relaxed); break ; } _result = atomic_compare_exchange_weak_explicit( _os_atomic_c11_atomic(_p), &old_v, new_v, memory_order_relaxed, memory_order_relaxed); } while (unlikely(!_result)); if (unlikely(_dispatch_lock_is_locked_by((dispatch_lock)old_v, self))) { DISPATCH_CLIENT_CRASH(0 , "trying to lock recursively" ); } _dispatch_thread_switch(new_v, 0 , timeout++); (void )timeout; } }
其中,_dispatch_thread_switch 函数实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 extern kern_return_t thread_switch ( mach_port_name_t thread_name, int option, mach_msg_timeout_t option_time) ; static inline void _dispatch_thread_switch(dispatch_lock value, dispatch_lock_options_t flags, uint32_t timeout) { int option; if (flags & DLOCK_LOCK_DATA_CONTENTION) { option = SWITCH_OPTION_OSLOCK_DEPRESS; } else { option = SWITCH_OPTION_DEPRESS; } thread_switch(_dispatch_lock_owner(value), option, timeout); }
_dispatch_thread_switch 函数,主要是对 thread_switch 函数的调用,thread_switch 函数是一个系统调用,用于在多线程环境中进行线程调度切换。当一个线程在等待某个资源(如锁)时,直接进行忙等待会浪费 CPU 资源。thread_switch 允许线程主动让出 CPU,使得其他线程可以被调度执行。
当一个线程调用 thread_switch 时,该线程会被挂起一段时间(由 option_time 参数指定,单位毫秒),在此期间,操作系统可以调度其他线程运行。
_dispatch_once_wait 中对 thread_switch 调用,第一次调用 option_time 传的值是 1 毫秒,即当前线程挂起 1 毫秒让出 CPU 资源给其他线程调用。下次时候 option_time ++,传入的是 2 毫秒,再挂起 2 毫秒,依次递增挂起时长……
总结 _dispatch_once_wait 函数核心逻辑是:
无限 for 循环,检测 dgo_once 是否为 DLOCK_ONCE_DONE。
如果是,代表 dispatch_once 的 block 执行完毕,无需再等待,终止 for 循环,该函数执行结束。
如果不是,代表 dispatch_once 的 block 没有执行完毕,将 dgo_once 设置为 dgo_once | DLOCK_WAITERS_BIT,继续 for 循环检测,直到 dgo_once 变成 DLOCK_ONCE_DONE。
无限 for 循环期间,通过 thread_switch 系统调用,使当前线程挂起,让出 CPU 资源给其他线程。挂起时长从 1毫秒开始,每次调用 thread_switch 递增 1 毫秒。
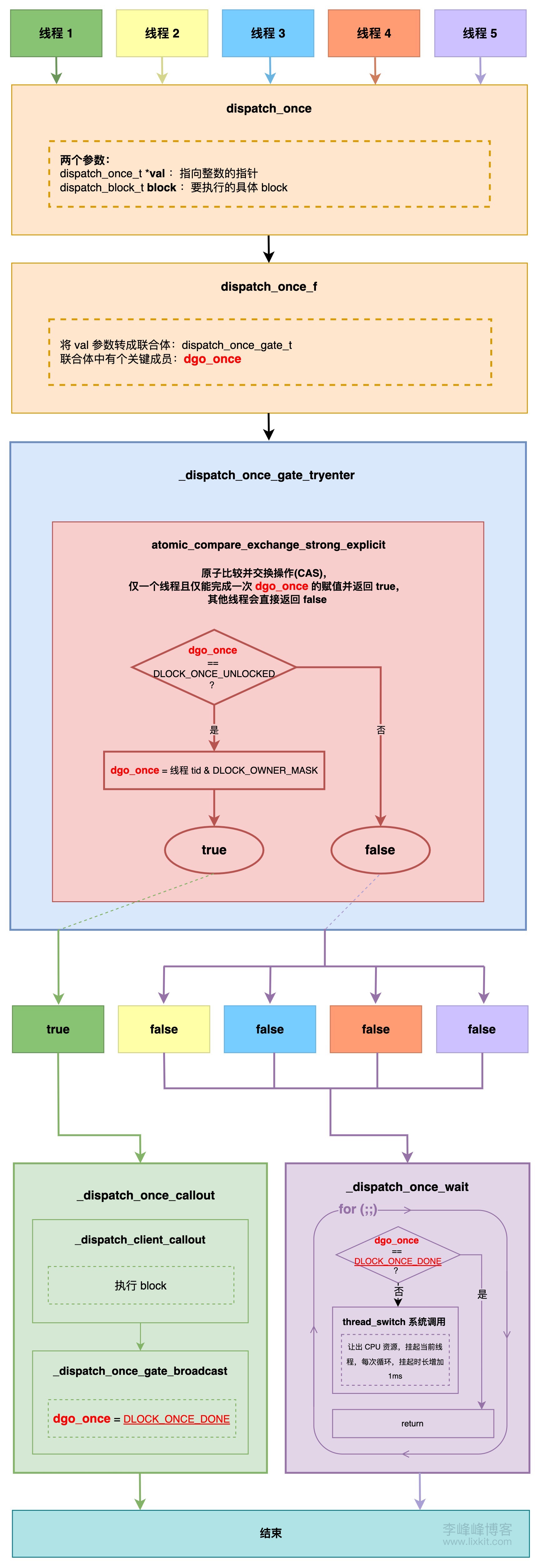
6、总结 根据前述 dispatch_once 源码,可以用下图表示其实现逻辑: