一、概述
Lex 和 Yacc 是编译器和解释器开发中广泛使用的工具,分别用于词法分析和语法分析。它们通常配合使用,帮助开发者快速构建语言处理工具,处理复杂的语言解析任务。
Lex(Lexical Analyzer Generator)是词法分析器生成器,Yacc(Yet Another Compiler Compiler)是语法分析器生成器,可以通过编写 Lex 和 Yacc 文件,实现自定义的词法分析器和语法分析器,实现对特定语言的解析和处理。
Lex 最早由 Mike Lesk 和 Eric Schmidt 在 1975 年为 Unix 操作系统开发。虽然 Lex 的原始版本是闭源的,但后来出现了多个开源实现,如 Flex(Fast Lexical Analyzer Generator),这是 Lex 的一个开源替代品。
Yacc 由 Stephen C. Johnson 在 1970 年代开发,旨在为 Unix 操作系统提供一个语法分析器生成工具。Yacc 的原始版本也是闭源的,但后来出现了多个开源实现,如 Bison,这是 GNU 项目提供的 Yacc 的开源替代品。
macOS 已经内置了 Flex 和 Bison:
1 | /usr/bin/flex |
/usr/bin 中同时还有 lex、yacc 两个工具,路径如下:
1 | /usr/bin/lex |
其本质也是 Flex 和 Bison:
Lex、Yacc 常用命令如下:
1 | lex test.l # 生成 lex.yy.c,该文件中实现了词法分析器函数 yylex() |
在 Xcode 中,也内置了 lex 和 yacc:
1 | /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/lex |
也就是说,Xcode 已经支持了 Lex、Yacc,可以自动将 Lex、Yacc 描述文件编译成分析器代码文件。
在编译流程中,Lex、Yacc 负责的工作如下:
- Lex
- 负责“词法分析”的工作。
- 负责“词法分析”的工作。
- Yacc
- 核心功能是“语法分析”。
- 还可以通过 Yacc 语义动作的扩展,使其承担更多工作:“语义分析”、“中间代码生成”。
- 这种方式在实际编译器实现中比较常见,在一个解析阶段中完成多个编译步骤,以提高编译效率。即:Yacc 同时负责“语法分析”、“语义分析”、“中间代码生成”的工作。
Lex 和 Yacc 在编译器构建过程中的协同工作主要流程如下: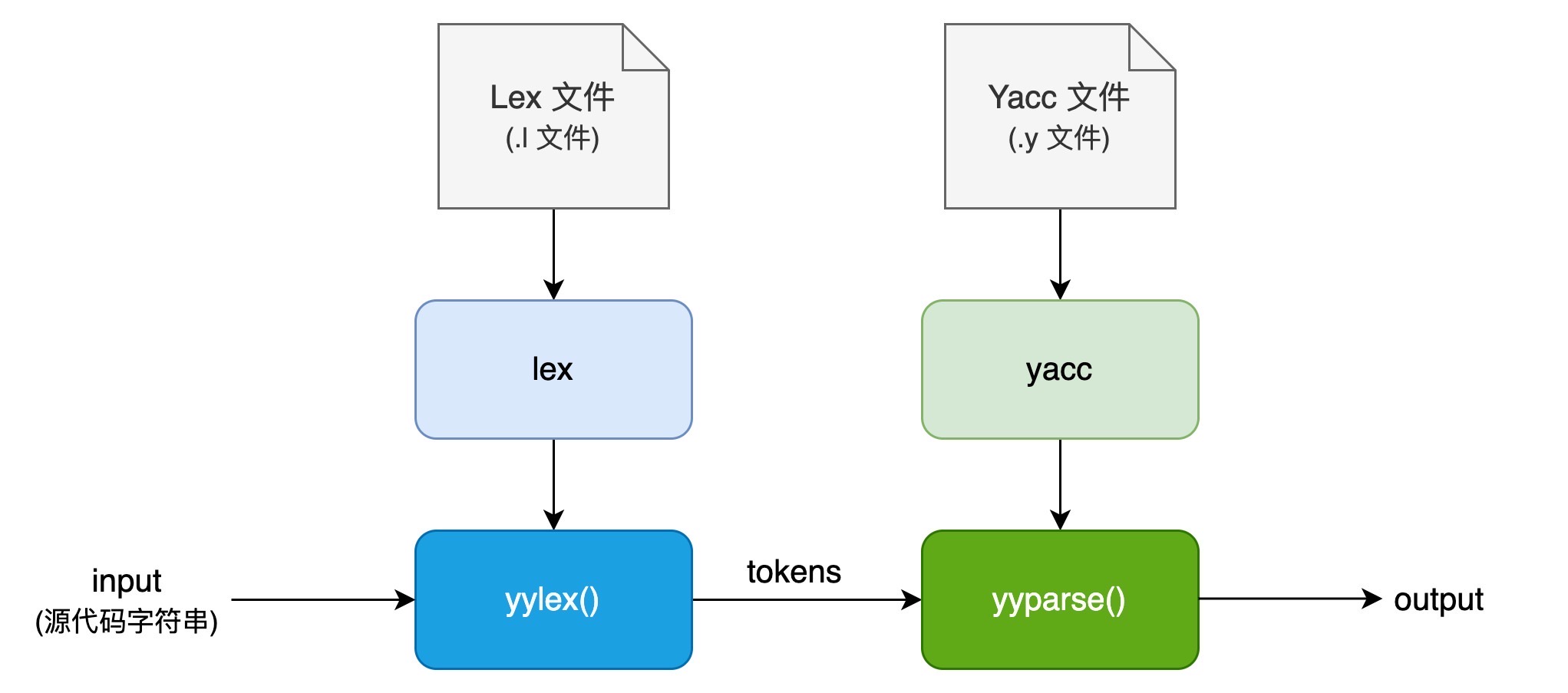
编写 Lex & Yacc 文件
- Lex 文件
- 定义词法分析规则的文件,包含正则表达式和相应的动作。
- Yacc 文件
- 定义语法分析规则的文件,包含语法规则和相应的语义动作。
- Lex 文件
生成分析器
- Lex
- 读取 Lex 文件,根据描述文件生成 C 语言实现的词法分析器代码文件 lex.yy.c,该文件中实现了词法分析器函数
yylex()。
- 读取 Lex 文件,根据描述文件生成 C 语言实现的词法分析器代码文件 lex.yy.c,该文件中实现了词法分析器函数
- Yacc
- 读取 Yacc 文件,根据描述文件生成 C 语言实现的语法分析器代码文件 y.tab.h 和 y.tab.c,该文件中实现了语法分析器函数
yyparse()。
- 读取 Yacc 文件,根据描述文件生成 C 语言实现的语法分析器代码文件 y.tab.h 和 y.tab.c,该文件中实现了语法分析器函数
- Lex
处理流程
词法分析(lex.yy.c)
- 输入源代码文件。
- 由
yylex()处理源代码,识别并生成词法单元(tokens)。
语法分析(y.tab.h、y.tab.c)
- 接受来自
yylex()的词法单元。 - 由
yyparse()处理词法单元,构建语法树或执行语义动作,最终生成输出。
- 接受来自
二、Lex
Lex 负责将输入的字符流分解成有意义的词法单元(token),Lex 文件通常使用 .l 扩展名,使用正则表达式来定义词法规则。
Lex 文件(example.l)内容示例如下:
1 | %{ |
生成词法分析器代码:
1 | lex example.l |
编译生成可执行文件:
1 | cc lex.yy.c -o lexer |
执行完上述两个命令之后,会生成文件名为 lexer 的可执行文件:
执行可执行文件,输入测试字符串,可以看到词法分析器输出内容:
生成的词法分析器实现代码在 lex.yy.c 中,lex.yy.c 中自动生成的主要函数如下:
yylex()- 主词法分析函数,它从输入中读取字符并尝试匹配定义的模式。
- 每次调用
yylex()时,它会扫描输入,找到最匹配的模式并执行相应的动作代码。 - 返回一个整数值,通常是匹配的模式的标识符(token)。
yywrap()- 在输入文件结束时调用,决定是否继续读取其他输入,返回
1表示输入结束,返回0表示继续。
- 在输入文件结束时调用,决定是否继续读取其他输入,返回
yytext- 全局字符数组或指针,存储当前匹配的文本。
- 每次
yylex()匹配到模式时,yytext包含匹配的字符串。 - 示例:
1
printf("Matched text: %s\n", yytext);
yyleng- 全局整数,表示
yytext中匹配文本的长度。
- 全局整数,表示
yyin- 文件指针,指向词法分析器的输入流。
- 默认情况下,
yyin指向stdin,可以重定向到其他文件。 - 示例:
1
yyin = fopen("input.txt", "r");
yyout- 文件指针,指向词法分析器的输出流(通常用于调试)。
- 默认情况下,
yyout指向stdout,可以重定向到其他文件。 - 示例:
1
yyout = fopen("output.txt", "w");
yyrestart(FILE *input_file)- 重置词法分析器的输入流。
- 可以在文件切换或重新开始分析时使用。
- 示例:
1
yyrestart(yyin);
yyset_in(FILE * _in_str)- 设置词法分析器的输入文件。
- 调用这个函数,可以动态地更改词法分析器的输入来源,而无需重新启动词法分析器。
- 示例:
1
2FILE *file = fopen("input.txt", "r");
yyset_in(file);
yylex_destroy()- 释放词法分析器使用的资源。
- 在程序结束时调用,以避免内存泄漏。
yy_scan_string(const char *str)- 从字符串而不是文件中读取输入。
- 适用于需要从内存中读取输入的场景。
- 示例:
1
yy_scan_string("example input");
yy_switch_to_buffer(YY_BUFFER_STATE new_buffer)- 切换词法分析器的输入缓冲区。
- 适用于需要在多个输入源之间切换的场景。
- 示例:
1
2YY_BUFFER_STATE buffer = yy_scan_string("example input");
yy_switch_to_buffer(buffer);
这些函数和变量共同构成了 Lex 词法分析器的核心功能,使其能够高效地处理输入、匹配模式并执行相应的动作。
Lex 文件内容结构如下:
1 | <定义> |
使用 %% 对不同的部分进行分隔,其主要包含三部分内容,分别是:
- 定义(可选)
- C 代码定义
- 命名正则表达式定义
- 指令定义
- 规则(必选)
- 模式:用于描述词法规则的正则表达式
- 动作:模式匹配时要执行的 C 代码
- 代码(可选)
- 辅助函数
- 也可以包含主程序的 main 函数
- 这部分代码会被直接拷贝进 lex.yy.c 中
1、定义
定义部分主要包含三部分内容:
- C 代码定义 (
%{和%}) - 命名正则表达式定义
- 指令定义(以
%开头的指令)
(1)C 代码定义 (%{ 和 %})
在定义部分中,可以包含直接嵌入到生成的 C 代码中的代码片段,这些代码会被直接拷贝到生成的 C 文件的开头部分。
示例:
1 | %{ |
在 %{ 和 %} 之间定义的 C 代码会被 Lex 工具直接拷贝到生成的词法分析器代码中。这通常用于定义变量、包含头文件、声明函数等。
(2)命名正则表达式定义
用来给常用的正则表达式定义名字,这样在规则部分可以复用这些命名的表达式。
基本格式:
1 | name expression |
示例:
1 | letter [a-zA-Z] |
命名正则表达式定义了表示某一类符号的正则表达式,这样可以在规则部分使用 {name} 来引用。
(3)指令定义
使用以 % 开头的指令来修改内置变量的默认值或设置词法分析器的配置。
常见指令:
%array和%pointer:控制yytext的类型。%array:yytext是一个字符数组(默认)。%pointer:yytext是一个字符指针。
%s STATE:定义一个状态,STATE 可以是任意字符串。- 词法分析器可以有多个状态,使用
%s来定义新的状态。
- 词法分析器可以有多个状态,使用
%e size:定义内置的NFA表项的数量。默认值是1000。%n size:定义内置的DFA表项的数量。默认值是500。%p size:定义内置的move表项的数量。默认值是2500。
2、规则
(1)规则的基本使用
规则部分主要包含三部分内容:
- 模式:用于描述词法规则的正则表达式
- 动作:模式匹配时要执行的 C 代码
规则部分是 Lex 文件的核心部分,也是 Lex 文件 中唯一必选部分,它定义了正则表达式模式及其对应的动作。当输入匹配某个模式时,执行相应的动作代码。
规则部分的基本结构
规则部分由一系列的规则组成,每条规则由一个正则表达式模式和一个动作代码块构成,格式如下:
1 | pattern { action } |
pattern:一个正则表达式,用于匹配输入文本。action:C 代码块,当输入文本与模式匹配时执行的动作。
示例:
1 | [a-zA-Z]+ { printf("Word: %s\n", yytext); } |
上述示例中,当正则匹配到对应字符串后,打印出对应的信息。
正则表达式匹配规则: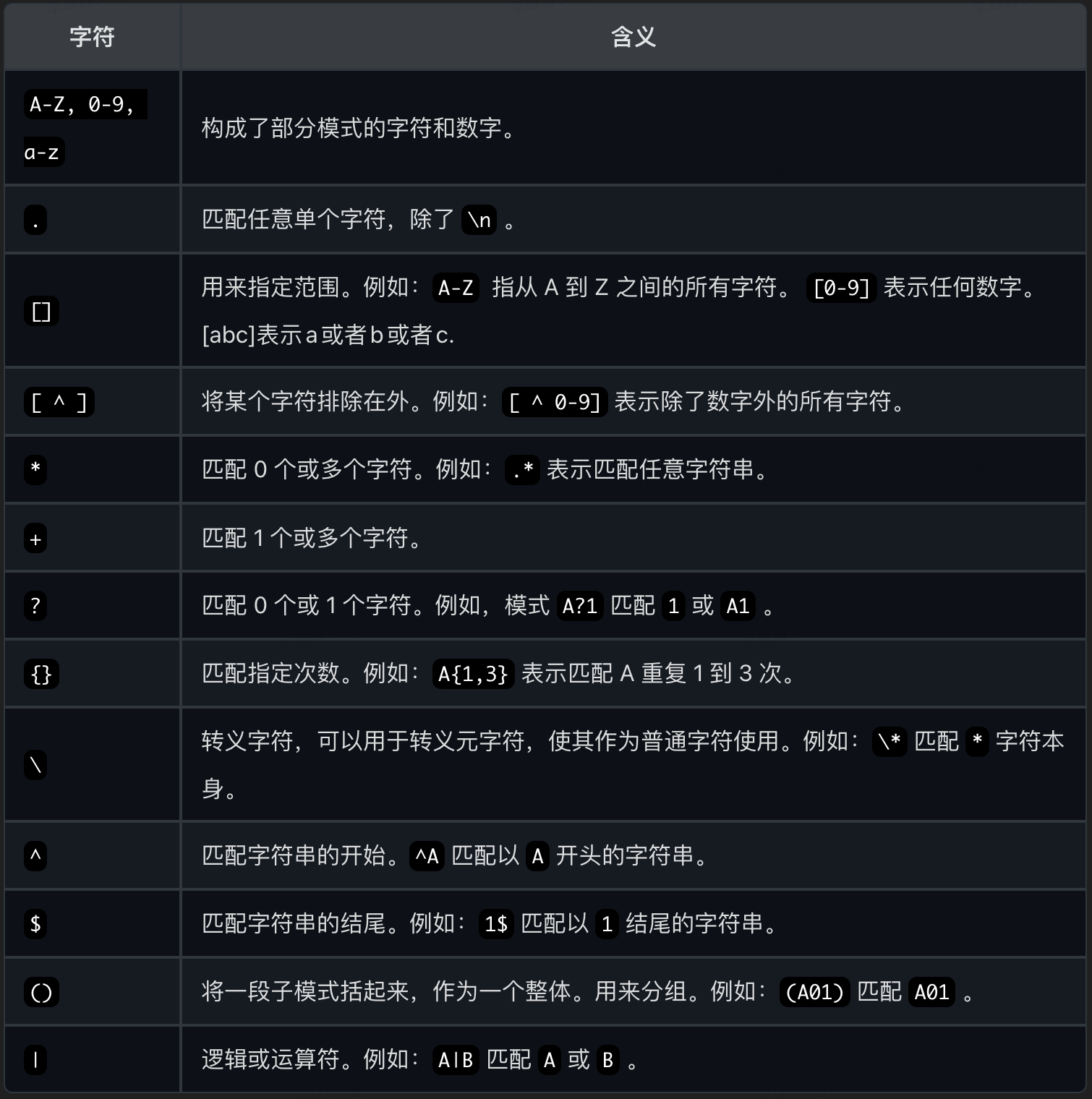
(2)使用状态的规则
在 Lex 中,可以使用状态来控制规则的应用范围。状态允许你在不同的上下文中应用不同的规则,使词法分析器能够处理更复杂的输入结构。
Lex 有三种定义状态的方式:
%s定义 Exclusive 状态- 仅在特定状态下匹配特定规则,其他状态下不匹配。
%x定义 Inclusive 状态- 在特定状态下优先匹配特定规则,但其他状态下的规则也可以匹配。
%start定义初始状态或多个状态- 声明初始状态或多个状态,可以与 BEGIN 宏结合使用来切换状态。
%s 定义 Exclusive 状态
在这种状态下,只有特定状态下定义的规则才会被匹配。当处于其他状态时,这些规则将不会被考虑。
示例:处理 C 风格注释
1 | %s COMMENT |
解释:
/*会将词法分析器的状态切换到COMMENT。- 在
COMMENT状态下,*/会将状态切换回初始状态INITIAL。 - 在
COMMENT状态下的规则仅在该状态下生效,而在其他状态下无效。
%x 定义 Inclusive 状态
在这种状态下,特定状态下的规则会优先匹配,但其他状态下的规则也可以被匹配。
示例:处理字符串字面量
1 | %x STRING |
解释:
\"会将词法分析器的状态切换到STRING。- 在
STRING状态下,\"会将状态切换回初始状态INITIAL。 - 在
STRING状态下的规则优先匹配,但其他状态下的规则也可以匹配。
%start 定义初始状态或多个状态
用于声明初始状态或多个状态,可以与 BEGIN 宏结合使用来切换状态。
示例:处理 C 和 C++ 风格注释
1 | %start C_COMMENT CC_COMMENT |
解释:
/*会将词法分析器的状态切换到C_COMMENT。- 在
C_COMMENT状态下,*/会将状态切换回初始状态INITIAL。 //会将词法分析器的状态切换到CC_COMMENT。- 在
CC_COMMENT状态下,\n会将状态切换回初始状态INITIAL。
3、代码
代码部分是 Lex 文件的最后一部分,位于第二个 %% 之后。这部分通常包含主函数 main() 和其他用户自定义的辅助函数。用户代码部分的主要作用是启动词法分析器并处理分析结果。
示例:
1 | %% |
三、Yacc
Yacc 负责根据上下文无关文法解析词法单元,生成语法树或执行相应的操作,Yacc 文件通常使用 .y 扩展名。
上下文无关文法在 Yacc 中起到了定义语法规则的作用,Yacc 使用上下文无关文法来描述编程语言的语法结构,并生成相应的解析器。
上下文无关文法(Context-Free Grammar, CFG)由诺姆·乔姆斯基(Noam Chomsky)在 1956 年提出,它是形式语言理论中的一种文法类型,用于定义编程语言的语法结构。
一个上下文无关文法由以下四个部分组成:
终结符集合(Terminal symbols)
- 表示语言中的基本符号,不能再被分解
- 例如:数字(如 123)、标识符(如 x、y)、运算符(如 +、-、*、/)、关键字(如
if、else、while)
- 例如:数字(如 123)、标识符(如 x、y)、运算符(如 +、-、*、/)、关键字(如
- 通常直接对应于词法分析器 Lex 生成的 token
- 表示语言中的基本符号,不能再被分解
非终结符集合(Non-terminal symbols)
- 表示语法结构,可以被分解为终结符或其他非终结符
- 例如:表达式(如
expression)、语句(如statement)、项(如term)、因子(如factor)
- 例如:表达式(如
- 表示语法结构,可以被分解为终结符或其他非终结符
生产规则集合(Production rules)
- 定义了如何将非终结符替换为终结符或其他非终结符
起始符(Start symbol)
- 一个特殊的非终结符,文法生成的语言的句子从这个符号开始
在 Yacc 文件中,对这四个部分的使用方式如下:
(1)终结符集合(Terminal symbols)
终结符是语言中的基本符号,不能再被分解。在 Yacc 中,终结符通过 %token 声明。例如:
1 | %token INTEGER |
这些声明表示 INTEGER、PLUS、MINUS、TIMES、DIVIDE、LPAREN 和 RPAREN 是终结符。
(2)非终结符集合(Non-terminal symbols)
非终结符表示语法结构,可以被分解为终结符或其他非终结符。在 Yacc 中,非终结符通过规则定义。例如:
1 | %type <ival> E T F |
这里的 E、T 和 F 是非终结符,表示表达式(Expression)、项(Term)和因子(Factor)。
(3)生产规则集合(Production rules)
生产规则定义了如何将非终结符替换为终结符或其他非终结符。在 Yacc 文件中,生产规则在 %% 符号之间定义。例如:
1 | %% |
这些规则描述了如何将非终结符 E、T 和 F 替换为其他非终结符和终结符的组合。
(4)起始符(Start symbol)
起始符是一个特殊的非终结符,文法生成的语言的句子从这个符号开始。在 Yacc 文件中,起始符是规则的第一个非终结符。例如,在上述规则中,E 是起始符,因为它是第一个定义的非终结符。
Yacc 通常与 Lex 配合使用,和 Lex 一样,Yacc 文件(example.y)内容示例如下:
1 | %{ |
生成语法分析器代码:
1 | yacc -d example.y |
执行完上述命令之后,就会生成 y.tab.h、y.tab.c 语法分析器代码实现文件,其中自动生成的主要函数如下:
yyparse()- 主语法分析函数,它从词法分析器获取 token 并尝试匹配定义的文法规则。
- 每次调用
yyparse()时,它会启动语法分析过程,直到输入结束或遇到错误。 - 返回一个整数值,通常是
0表示成功,1表示有语法错误。 - 示例:
1
int result = yyparse();
yyerror(const char *s)- 错误处理函数,当语法分析器遇到错误时调用。
- 通常用于打印错误信息或执行其他错误处理逻辑。
- 示例:
1
2
3void yyerror(const char *s) {
fprintf(stderr, "Error: %s\n", s);
}
yylval- 全局变量,用于存储词法分析器返回的 token 的值。
- 在词法分析器中设置
yylval,在语法分析器中使用。 - 默认为
int类型,实际开发中通常会将yylval配置成联合体,以支持存储更复杂的数据。- 可以使用
%union、%token、%type自定义yylval类型:%union来定义一个包含多种类型的联合体,该联合体就是 yylval 的实际类型。使用
%token声明 Lex 解析出的终结符 token 使用联合体哪个成员存储。使用
%type声明 Lex 解析出的非终结符 token 使用联合体哪个成员存储。示例:
1
2
3
4
5
6
7
8
9%union {
int ival;
float fval;
char *sval;
}
%token <ival> INTEGER
%token <fval> FLOAT
%token <sval> STRING
- 可以使用
yychar- 全局变量,存储当前解析的 token。
- 由
yyparse()使用,用于控制解析过程。 - 示例:
1
2
3if (yychar == SOME_TOKEN) {
// Do something
}
Yacc 文件内容结构与 Lex 完全一样,Yacc 内容结构如下:
1 | <定义> |
Yacc 文件也同样包含定义、规则、代码三部分内容:
- 定义(可选)
- token 定义
- 优先级与关联性定义
- C 代码定义
- 规则(必选)
- 定义了文法规则和对应的动作代码
- 规则名:一个非终结符
- 产生式:由终结符和非终结符组成的序列
- 动作:C 代码,当产生式匹配时执行
- 定义了文法规则和对应的动作代码
- 代码(可选)
- 辅助函数
- 也可以包含主程序的 main 函数
- 这部分代码会被直接拷贝进 y.tab.c 中
1、定义
定义是 Yacc 的第一部分,主要包含三部分内容:
- token 定义
- 优先级与关联性定义
- C 代码定义
(1) token 定义
Lex 词法分析器将源代码字符串识别成一个个的 token,Yacc 语法分析器则会将 token 进行分类处理,因此两者之间必须统一 token 的类型。
为了使词法分析器和语法分析器之间的 token 类型一致,通常在 Yacc 文件中定义 token 类型。使用 %token 指令定义 token,格式如下:
1 | %token name1 name2 name3 ... |
示例:
1 | %token NUMBER PLUS MINUS |
Yacc 会将 %token 指令转换为 C 语言的宏定义(#define)。
例如要解析一个简单的数学表达式,如 3 + 5,并计算其结果:
Lex 文件:
1 | %{ |
Yacc 文件:
1 | %{ |
上述示例中,Yacc 中定义了 INTEGER 和 PLUS 两个 Token,在 Lex 文件中使用了这两个 Token。
(2)优先级与关联性定义
在 Yacc 中,优先级和关联性定义用于解决语法分析中的歧义,特别是在处理运算符时。优先级决定了运算符的应用顺序,而关联性决定了相同优先级的运算符在表达式中的结合方向。
优先级
- 优先级用于确定运算符的应用顺序。例如,在表达式 3 + 4 * 5 中,乘法运算符 * 的优先级高于加法运算符 +,因此乘法会先于加法执行。
关联性
- 关联性用于确定相同优先级的运算符的结合方向。例如,在表达式 a - b - c 中,加法和减法都是左关联,即从左到右结合。而赋值运算符 = 是右关联,即从右到左结合。
Yacc 提供了以下指令来定义运算符的优先级和关联性:
%left- 左关联。先定义的优先级低于后定义的优先级
- 例如:算术运算符(+、-、*、/ 等)、比较运算符(<、>、<=、>= 等)
%right- 右关联,先定义的优先级高于后定义的优先级。
- 例如:赋值运算符(=、+=、-= 等)、条件运算符(?:)
%nonassoc- 无关联,用于定义不允许连续使用的运算符(如比较运算符)
- 例如:Python 中的逻辑运算符(and、or)
示例:
1 | %right '=' |
(3)C 代码定义
在 %{ 和 %} 之间可以定义 C 语言的变量和函数,这些定义会被直接拷贝到生成的 C 文件的开头部分。
示例:
1 | %{ |
2、规则
规则主要包含三部分内容:
- 规则名:一个非终结符
- 产生式:由终结符和非终结符组成的序列
- 动作:C 代码,当产生式匹配时执行
规则部分定义了一系列的语法规则。每条规则由一个非终结符和一个或多个产生式组成,每个产生式可以包含可选的语义动作。
基本格式:
1 | identifier : definition { action } |
identifier是非终结符,对应文法产生式的左部。definition是产生式,由终结符和非终结符组成,对应文法产生式的右部。{ action }是语义动作,当产生式匹配时执行的 C 代码。- 一般多个产生式对应一个
action,在action中,可以使用$获取产生式的值。$n获取第n个产生式的值。$$表示当前产生式左侧非终结符的值,即当前产生式的结果。
- 一般多个产生式对应一个
示例:
1 | expression: |
例如在上述示例中:
expression '+' expression是三个产生式:expression、'+'、expression$1、$3表示产生式的第一个expression、第二个expression的值$$表示产生式结果
默认情况下,规则部分定义的第一个非终结符为开始符号(Start Symbol)。可以使用 %start 指令自定义开始符号。
示例:
1 | %start my_start_symbol |
3、代码
代码 Yacc 文件的最后一部分,可以包含辅助函数和主程序的 main 函数。这部分代码会被直接拷贝到生成的 C 文件的末尾。
示例:
1 | // 定义,略 ... |
四、Lex、Yacc 完整示例及解读
使用 Lex、Yacc 实现一个简单的计算器。
在 Xcode 中新建一个 macOS 的 Command Line Tool 工程。
calc.l 文件内容:
1 | %{ |
calc.y 文件内容:
1 | %{ |
main.m 文件内容:
1 | // |
直接运行,打印如下:
1 | Yacc: Completed calculation with result: 14 |
因为 Xcode 内置了 Lex、Yacc 工具,所以可以直接编译运行。不同的是,Xcode 自动生成的词法分析代码文件为 Lex文件名.yy.c,例如上述示例生成的是 calc.yy.c。
在上述示例中,调用 Lex 词法分析器的 yyset_in(FILE * _in_str) 函数设置词法分析器的输入文件,然后调用 Yacc 语法分析器的 yyparse() 函数执行语法分析及后续流程。
yyparse() 是由 Yacc(或 Bison)自动生成的语法分析器的核心函数。它的主要任务是根据定义的语法规则解析输入,并执行相应的语义动作。
yyparse() 伪代码如下:
1 | int yyparse() { |
yyparse() 的主要逻辑如下:
- 初始化
- 初始化状态栈和符号栈。
- 设置初始状态为起始状态。
- 读取第一个词法单元(token)。
- 主循环
- 在一个循环中,不断读取下一个词法单元,直到到达输入的结尾或检测到语法错误。
- 状态转移
- 根据当前状态和当前词法单元,从语法表中查找下一步的动作:
- 移入(shift):将当前词法单元移入符号栈,并转移到新状态。
- 规约(reduce):使用一个产生式规则将栈顶的符号归约为非终结符,并转移到新状态。
- 接受(accept):解析成功,停止解析过程。
- 错误(error):检测到语法错误,调用错误处理函数。
- 根据当前状态和当前词法单元,从语法表中查找下一步的动作:
- 执行语义动作
- 在规约过程中,执行相应的语义动作,计算值或构建语法树。
所以,上述示例在解析表达式 2 + 3 * 4 时,yyparse() 按照以下步骤工作:
- 初始化
- 初始化状态和符号栈。
- 读取第一个词法单元 2。
- 状态转移和规约:
- 移入 2:
- 读取下一个词法单元 +。
- 移入 +:
- 读取下一个词法单元 3。
- 移入 3:
- 读取下一个词法单元 *。
- 移入 *:
- 读取下一个词法单元 4。
- 移入 4:
- 读取下一个词法单元 \n。
- 规约 3 * 4:
- 匹配规则 expression ‘*’ expression。
- 执行语义动作 $$ = $1 * $3 计算结果 12。
- 将结果 12 压入符号栈。
- 规约 2 + 12:
- 匹配规则 expression ‘+’ expression。
- 执行语义动作 $$ = $1 + $3 计算结果 14。
- 将结果 14 压入符号栈。
- 终止:读取到 \n 并匹配完成,解析成功,返回结果。
- 移入 2:
-

- 本文章采用 知识共享署名 4.0 国际许可协议 进行许可,完整转载、部分转载、图片转载时均请注明原文链接。