1、NSObject 对象的内存占用 首先,我们知道,在 32 位系统中,指针占用 4 个字节;在 64 位系统中,指针占用 8 个字节。这里,我们只考虑 64 位情况。
对于 NSObject 对象, 其实现如下:
1 2 3 4 5 struct NSObject_IMPL { Class isa; }; typedef struct objc_class *Class;
一个指针占用 8 个字节,而 Class 又是指向 objc_class 结构体的指针,那么是否意味着 NSObject 对象占用 8 个字节内存空间呢?我们可以验证一下。
可以使用如下方法获取创建一个实例对象,所分配的内存大小:
1 2 #import <malloc/malloc.h> malloc_size((__bridge const void *)obj);
如下:
1 2 NSObject *obj = [[NSObject alloc] init];NSLog (@"%zd" , malloc_size((__bridge const void *)obj));
打印结果:
那么问题来了,为什么不是 8 个字节而是 16 个字节?
我们可以去 https://opensource.apple.com/tarballs/objc4/ 下载 Apple 提供 OC 的实现源码,直接 Xcode 打开,看下创建实例对象时内存是如何分配的,以下是从源码中拿出的关键部分代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 + (id )allocWithZone:(struct _NSZone *)zone { return _objc_rootAllocWithZone(self , (malloc_zone_t *)zone); } id _objc_rootAllocWithZone(Class cls, malloc_zone_t *zone){ id obj; #if __OBJC2__ (void )zone; obj = class_createInstance(cls, 0 ); #else if (!zone) { obj = class_createInstance(cls, 0 ); } else { obj = class_createInstanceFromZone(cls, 0 , zone); } #endif if (slowpath(!obj)) obj = callBadAllocHandler(cls); return obj; } id class_createInstance(Class cls, size_t extraBytes) { return _class_createInstanceFromZone(cls, extraBytes, nil ); } id _class_createInstanceFromZone(Class cls, size_t extraBytes, void *zone, bool cxxConstruct = true , size_t *outAllocatedSize = nil ) { if (!cls) return nil ; assert(cls->isRealized()); bool hasCxxCtor = cls->hasCxxCtor(); bool hasCxxDtor = cls->hasCxxDtor(); bool fast = cls->canAllocNonpointer(); size_t size = cls->instanceSize(extraBytes); if (outAllocatedSize) *outAllocatedSize = size; id obj; if (!zone && fast) { obj = (id )calloc(1 , size); if (!obj) return nil ; obj->initInstanceIsa(cls, hasCxxDtor); } else { if (zone) { obj = (id )malloc_zone_calloc ((malloc_zone_t *)zone, 1 , size); } else { obj = (id )calloc(1 , size); } if (!obj) return nil ; obj->initIsa(cls); } if (cxxConstruct && hasCxxCtor) { obj = _objc_constructOrFree(obj, cls); } return obj; }
从 _class_createInstanceFromZone 方法实现可以看出,创建实例对象所分配的内存由以下代码决定:
1 size_t size = cls->instanceSize(extraBytes);
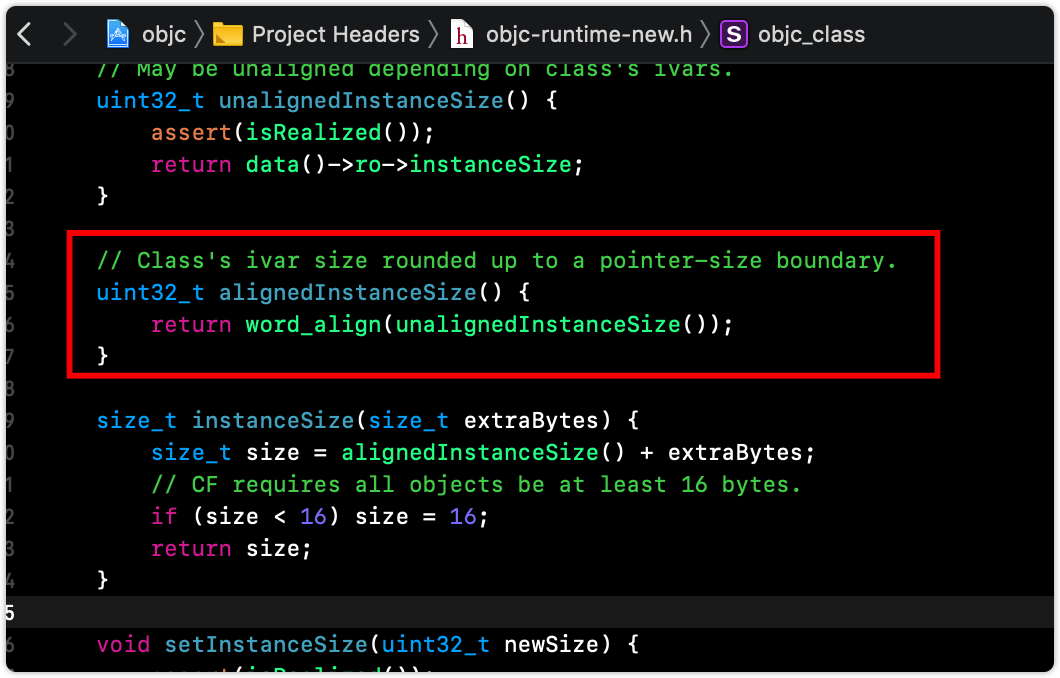
instanceSize 方法实现源码如下:
1 2 3 4 5 6 size_t instanceSize(size_t extraBytes) { size_t size = alignedInstanceSize() + extraBytes; if (size < 16 ) size = 16 ; return size; }
创建对象时候,如果对象占用内存小于 16 字节,就会分配 16 字节内存 (除了这个原因外,内存对齐也会对最终分配的内存有影响,内存对齐后续会介绍)。
所以,NSObject 对象虽然只占用 8 个字节内存,实际上会分配 16 字节。
注意,在 runtime 中,还有下面这个获取对象所占用内存的方法:
1 2 #import <objc/runtime.h> class_getInstanceSize([NSObject class ]);
如果用该方法获取 NSObject 对象所占用内存大小时,该方法将会返回 8 而不是 16,以下是从 Apple 提供的源码相关代码:
1 2 3 4 5 6 7 8 9 10 11 12 size_t class_getInstanceSize(Class cls) { if (!cls) return 0 ; return cls->alignedInstanceSize(); } uint32_t alignedInstanceSize() { return word_align(unalignedInstanceSize()); }
class_getInstanceSize 获取到的大小, 是内存对齐之后的大小,这实际上是获取对象成员变量所占用的内存大小。 所以可以理解为是创建对象至少所需要的内存大小。由于 NSObject 对象中只有一个 isa 成员变量,所以使用该方法获取到的大小为 8,由于小于最低 16 字节,所以会直接分配 16 字节内存,也就意味着有 8 字节目前是空着还没有利用的。
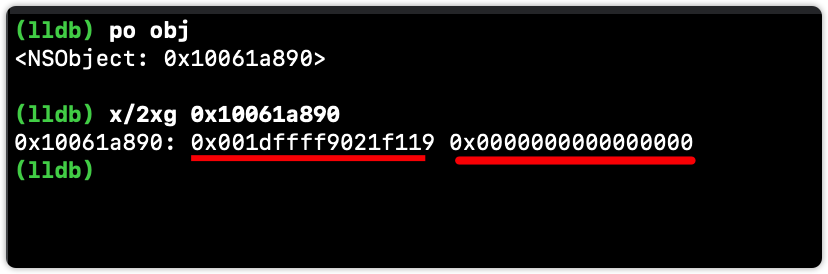
也可以借助 LLDB 如下命令获取内存分布情况:x/数量格式字节数 内存地址
【格式】 【字节大小】
例如:x/2xg 内存地址
2xg 代表打印 2 段,每段都是 16 进制格式显示,每段都是 8 个字节。
通过该命令再看下 NSObject 对象的内存分布:
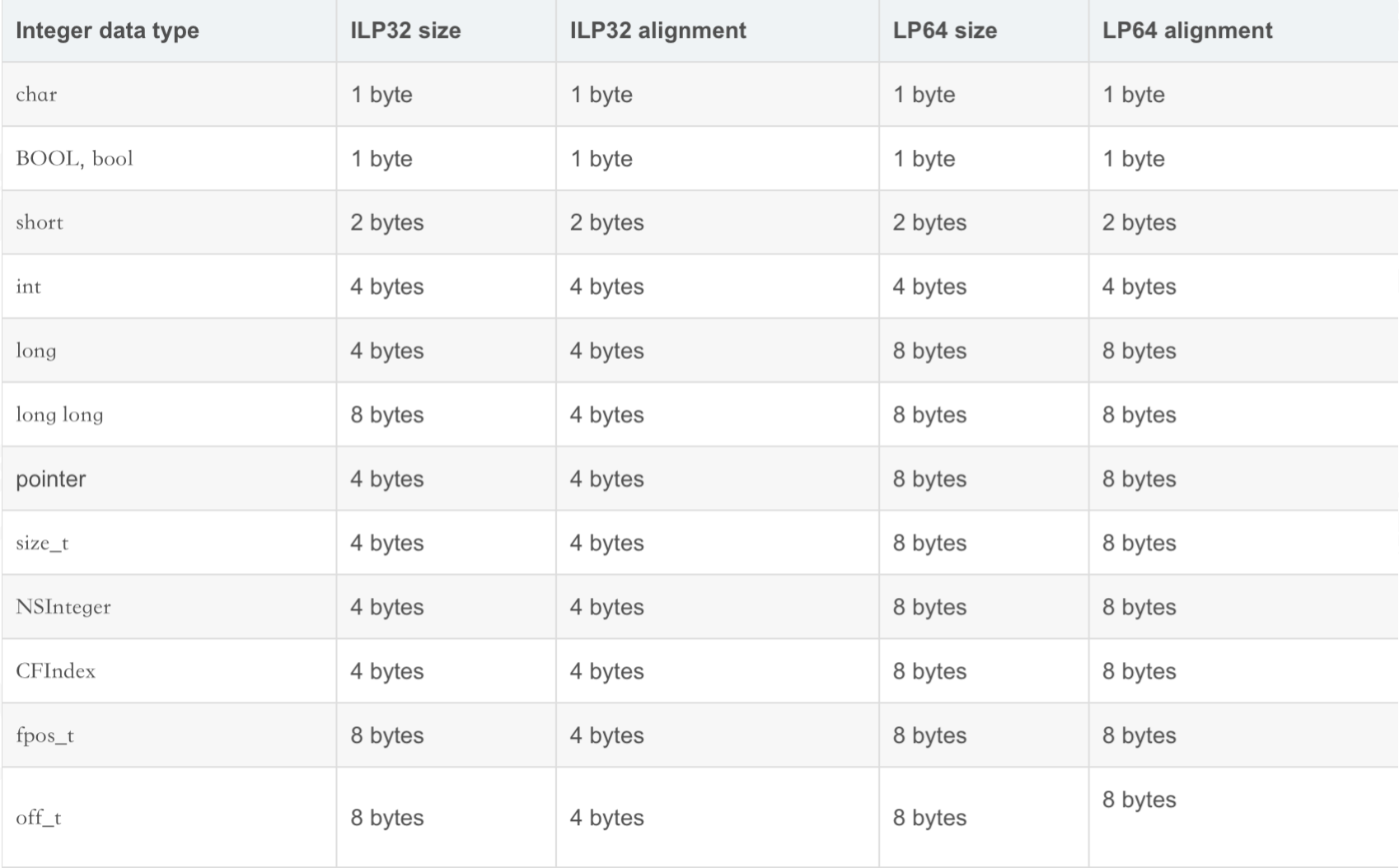
2、自定义对象的内存占用 各数据类型占用内存大小:
1 2 3 4 5 6 7 8 9 10 11 @interface Student : NSObject @public int _no; int _age; } @end @implementation Student @end
那么这个 Student 对象占用多大内存?
1 xcrun -sdk iphoneos clang -arch arm64 -rewrite-objc OC源文件 -o 输出的CPP文件
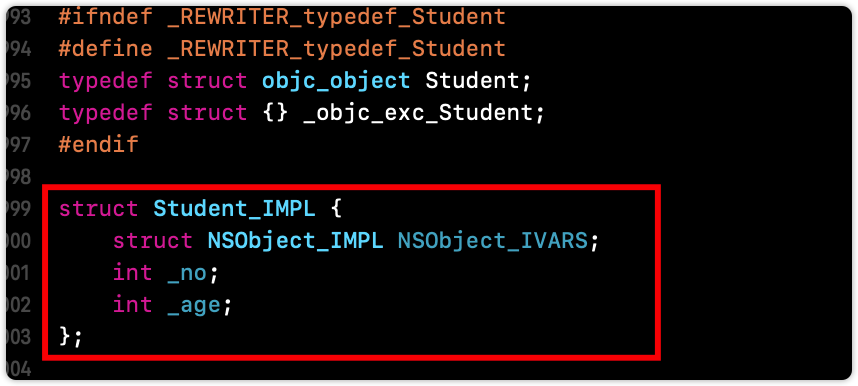
在生成的 C/C++ 代码可以找到 Student 的实现:
1 2 3 4 5 struct Student_IMPL { struct NSObject_IMPL NSObject_IVARS ; int _no; int _age; };
1 2 3 struct NSObject_IMPL { Class isa; };
也就是说,Student_IMPL 实际上可以认为是:
1 2 3 4 5 struct Student_IMPL { Class isa; int _no; int _age; };
所以,可以确定 Student 的实例对象会占用 16 字节内存,可以验证确认一下:
1 2 3 4 5 Student *stu = [[Student alloc] init]; stu->_no = 101 ; stu->_age = 18 ; NSLog (@"stu size:%zd" , malloc_size((__bridge const void *)stu));
打印结果:stu size:16
而且,在内存中,三个成员 isa、_no、_age 的内存地址也是连续的。stu 的内存地址和第一个成员 isa 的地址是一样的。
3、内存对齐 先看一个内存对齐的例子,假设有 StudentOne、StudentTwo 两个结构体,它们的成员完全一样的,只是把 a、b 两个成员换个顺序,然后使用 sizeof 获取结构体所占用内存大小:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct StudentOne { char a; double b; int c; short d; } StuStruct1; struct StudentTwo { double b; char a; short d; int c; } StuStruct2; NSLog (@"StuStruct1 size:%lu,StuStruct2 size:%lu" , sizeof (StuStruct1), sizeof (StuStruct2));
打印结果:StuStruct1 size:24,StuStruct2 size:16
结果就是成员一样的两个结构体所占用内存的大小却不一样,这就是内存对齐的结果。
关于 sizeof
1 2 3 sizeof (int ) = 4 sizeof ([NSObject class ])) = 8 sizeof ([[MyNSObject alloc]init]) = 8
sizeof 只会计算类型所占用的内存大小,不会关心具体的对象的内存布局。所以自定义一个 NSObject 对象,无论该对象生命多少个成员变量,最后得到的内存大小都是 8 个字节。
对齐系数:
内存对齐的原则
数据成员对齐规则:(Struct 或者 Union 的数据成员)第一个数据成员放在偏移为 0 的位置。以后每个数据成员的位置为 min(对齐系数,自身长度) 的整数倍,下个位置不为本数据的整数倍位置的自动补齐。
数据成员为结构体:该数据成员内的最大长度的整数倍的位置开始存储。
收尾工作:结构体的总大小,也就是 sizeof 的结果,对齐原则是 min(对齐系数,最大成员长度) 的整数倍,不足的要补⻬。
再回头看下 StudentOne 和 StudentTwo 两个结构体:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 struct StudentOne { char a; char _pad0[7 ]; double b; int c; short d; char _pad1[2 ]; } struct StudentTwo { double b; char a; char _pad0[1 ]; short d; int c; } StuStruct2;
所以 StudentOne 占用 24 字节内存,StudentTwo 占用 16 字节内存。
如果在代码执行前加一句 #pragma pack(1) 时就代表不进行内存对齐,上述结构体打印大小的结果就都为 16。
需要内存对齐原因
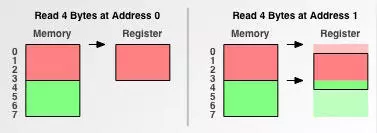
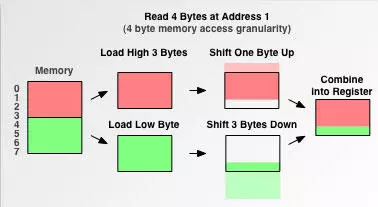
为了说明内存对齐背后的原理,我们通过一个例子来说明从未地址与对齐地址读取数据的差异。这个例子很简单:在一个存取粒度为 4 字节的内存中,先从地址 0 读取 4 个字节到寄存器,然后从地址 1 读取 4 个字节到寄存器。
当从地址 0 开始读取数据时,是读取对齐地址的数据,直接通过一次读取就能完成。当从地址 1 读取数据时读取的是非对齐地址的数据。需要读取两次数据才能完成。
4、calloc 分析 先看一个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #import <Foundation/Foundation.h> #import <malloc/malloc.h> #import <objc/runtime.h> @interface Student : NSObject int _age; int _height; } @end @implementation Student @end int main(int argc, const char * argv[]) { @autoreleasepool { Student *stu = [[Student alloc] init]; NSLog (@"\nclass_getInstanceSize=%zd\nmalloc_size=%zd" , class_getInstanceSize([Student class ]), malloc_size((__bridge const void *)(stu))); } return 0 ; }
打印结果:
1 2 class_getInstanceSize=16 malloc_size=16
从以上结果可以看出,Student 有 2 个自定义的成员变量,内存对齐后所需大小为 16 字节,实际分配了 16 字节,满足预期结果。
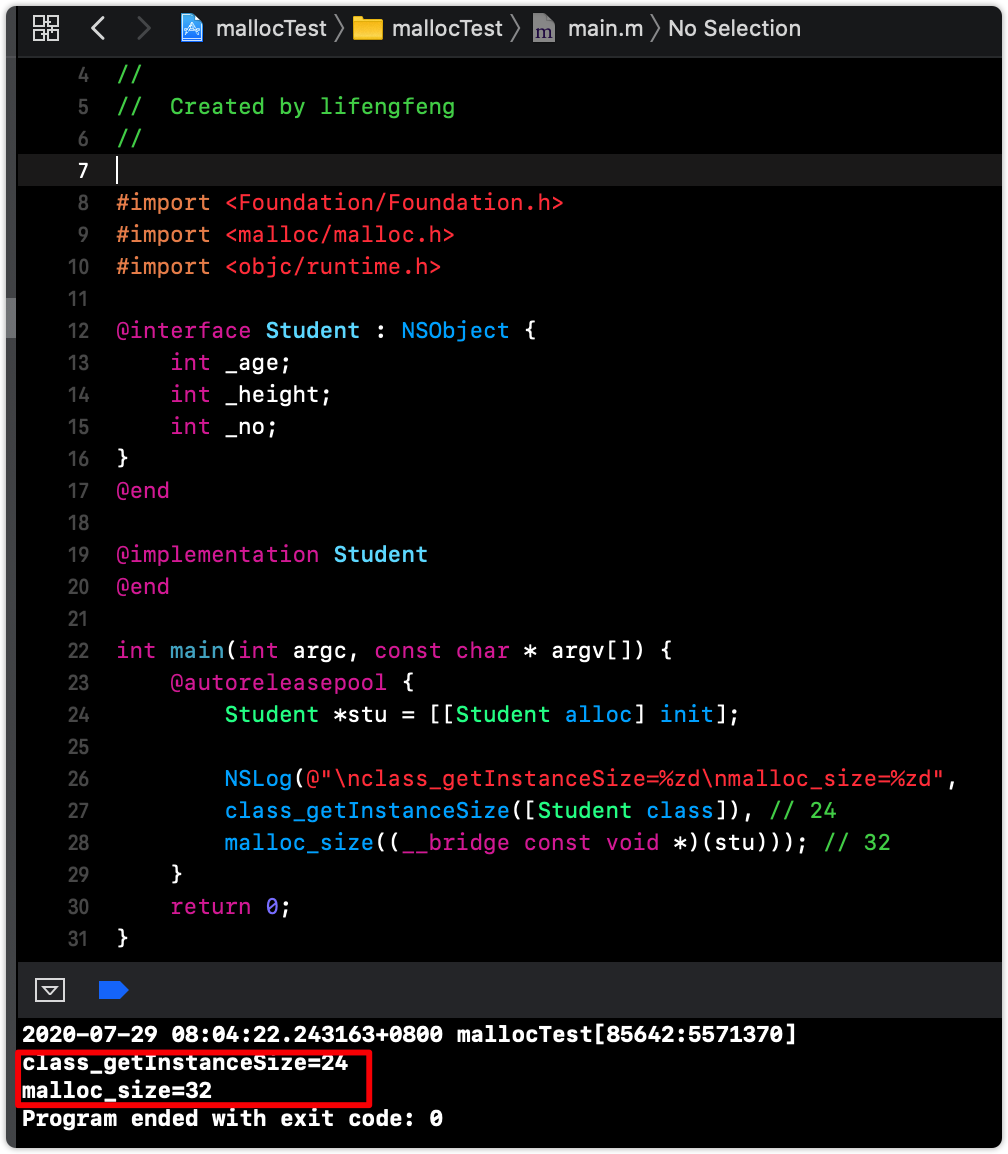
那么再给 Student 增加一个成员变量,打印结果将会是多少呢:
1 2 3 4 5 6 @interface Student : NSObject int _age; int _height; int _no; } @end
先从内存对齐的角度计算下:
1 2 3 4 5 6 struct Student_IMPL { Class isa; int _age; int _height; int _no; };
从结果可以猜测打印结果可能是下面这样:
1 2 class_getInstanceSize=24 malloc_size=24
运行代码看下结果是否符合预期,运行代码打印结果:
1 2 class_getInstanceSize=24 malloc_size=32
下面是前面提到的创建实例对象时内存分配相关源码中的部分逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 id _class_createInstanceFromZone(Class cls, size_t extraBytes, void *zone, bool cxxConstruct = true , size_t *outAllocatedSize = nil ) { if (!cls) return nil ; ... size_t size = cls->instanceSize(extraBytes); if (outAllocatedSize) *outAllocatedSize = size; id obj; if (!zone && fast) { ... } else { if (zone) { ... } else { obj = (id )calloc(1 , size); } ... } ... return obj; } size_t instanceSize(size_t extraBytes) { size_t size = alignedInstanceSize() + extraBytes; if (size < 16 ) size = 16 ; return size; }
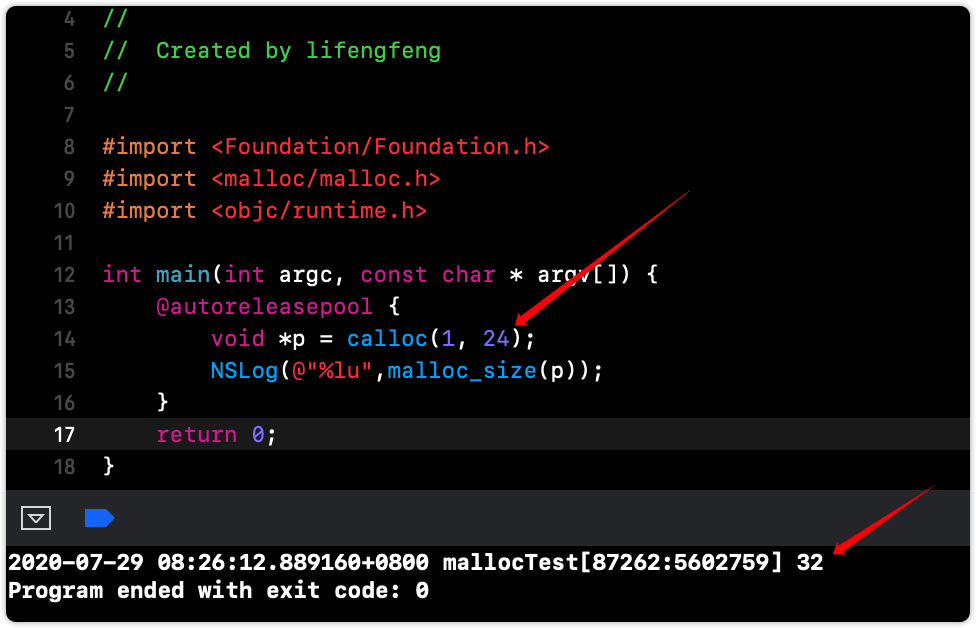
可以看出,创建实例对象的时候,我们传给 calloc 的是内存对齐后的大小 24,但是 calloc 中实际分配了 32,可以验证一下:
1 2 void *p = calloc(1 , 24 );NSLog (@"%lu" ,malloc_size(p));
打印结果:32
1 2 3 4 5 6 7 8 9 10 void *calloc(size_t num_items, size_t size) { void *retval; retval = malloc_zone_calloc(default_zone, num_items, size); if (retval == NULL ) { errno = ENOMEM; } return retval; }
可以看到 calloc 里主要调用了 malloc_zone_calloc:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 void *malloc_zone_calloc(malloc_zone_t *zone, size_t num_items, size_t size) { MALLOC_TRACE(TRACE_calloc | DBG_FUNC_START, (uintptr_t)zone, num_items, size, 0 ); void *ptr; if (malloc_check_start && (malloc_check_counter++ >= malloc_check_start)) { internal_check(); } ptr = zone->calloc(zone, num_items, size); if (malloc_logger) { malloc_logger(MALLOC_LOG_TYPE_ALLOCATE | MALLOC_LOG_TYPE_HAS_ZONE | MALLOC_LOG_TYPE_CLEARED, (uintptr_t)zone, (uintptr_t)(num_items * size), 0 , (uintptr_t)ptr, 0 ); } MALLOC_TRACE(TRACE_calloc | DBG_FUNC_END, (uintptr_t)zone, num_items, size, (uintptr_t)ptr); return ptr; }
其中关键代码是 ptr = zone->calloc(zone, num_items, size); 到这里打断点调试看下:
根据 LLDB 打印结果可以确定调用的是 default_zone_calloc:
1 2 3 4 5 6 7 static void *default_zone_calloc(malloc_zone_t *zone, size_t num_items, size_t size) { zone = runtime_default_zone(); return zone->calloc(zone, num_items, size); }
这里再断点调试一下,可以确定调用的 naco_calloc。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static void *nano_calloc(nanozone_t *nanozone, size_t num_items, size_t size) { size_t total_bytes; if (calloc_get_size(num_items, size, 0 , &total_bytes)) { return NULL ; } if (total_bytes <= NANO_MAX_SIZE) { void *p = _nano_malloc_check_clear(nanozone, total_bytes, 1 ); if (p) { return p; } else { } } malloc_zone_t *zone = (malloc_zone_t *)(nanozone->helper_zone); return zone->calloc(zone, 1 , total_bytes); }
ANO_MAX_SIZE 为 256,此时 total_bytes 肯定小于 256,继续执行走到void *p = _nano_malloc_check_clear(nanozone, total_bytes, 1);
再来看下 _nano_malloc_check_clear 的实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 static void *_nano_malloc_check_clear(nanozone_t *nanozone, size_t size, boolean_t cleared_requested) { MALLOC_TRACE(TRACE_nano_malloc, (uintptr_t)nanozone, size, cleared_requested, 0 ); void *ptr; size_t slot_key; size_t slot_bytes = segregated_size_to_fit(nanozone, size, &slot_key); mag_index_t mag_index = nano_mag_index(nanozone); nano_meta_admin_t pMeta = &(nanozone->meta_data[mag_index][slot_key]); ptr = OSAtomicDequeue(&(pMeta->slot_LIFO), offsetof(struct chained_block_s, next)); if (ptr) { } else { ptr = segregated_next_block(nanozone, pMeta, slot_bytes, mag_index); } if (cleared_requested && ptr) { memset(ptr, 0 , slot_bytes); } return ptr; }
跟着断点继续往下走,执行到 segregated_size_to_fit(nanozone, size, &slot_key),segregated_size_to_fit 对应实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #define NANO_MAX_SIZE 256 #define SHIFT_NANO_QUANTUM 4 #define NANO_REGIME_QUANTA_SIZE (1 << SHIFT_NANO_QUANTUM) static MALLOC_INLINE size_tsegregated_size_to_fit(nanozone_t *nanozone, size_t size, size_t *pKey) { size_t k, slot_bytes; if (0 == size) { size = NANO_REGIME_QUANTA_SIZE; } k = (size + NANO_REGIME_QUANTA_SIZE - 1 ) >> SHIFT_NANO_QUANTUM; slot_bytes = k << SHIFT_NANO_QUANTUM; *pKey = k - 1 ; return slot_bytes; }
注意上面关键部分:
1 2 k = (size + NANO_REGIME_QUANTA_SIZE - 1 ) >> SHIFT_NANO_QUANTUM; slot_bytes = k << SHIFT_NANO_QUANTUM;
也就是:(size + 16 - 1) >> 4 << 4
我们可以知道,这实际上就是对 size 进行了 16 字节对齐。
而我们前面的 size 为 24,经过 16 字节对齐后正好是 32。
根据结果,可以总结出结论:在进行内存对齐时,对象的成员变量(结构体成员)是 8 字节对齐,对象本身是 16 字节对齐。
例如前面例子中 Student 对象的实现:
1 2 3 4 5 6 struct Student_IMPL { Class isa; int _age; int _height; int _no; };
Student_IMPL 结构体内存对齐前是 20 字节,内存对齐后是 24 字节,在创建 Student 实例对象的时候,虽然它只占用了 24 字节,但是 calloc 里在分配内存的时候会再次对实例对象进行 16 字节对齐,最终分配了 32 字节内存。
这里为什么要针对对象再进行 16 字节对齐呢?
【备注】 class_getInstanceSize、malloc_size、sizeof 的区别:
class_getInstanceSize:
malloc_size:
sizeof: