一、常规文件访问
以 NSUserDefaults 为例,看下传统文件读写流程。
1、NSUserDefaults 基本使用
1 | NSUserDefaults *defaults = [NSUserDefaults standardUserDefaults]; |
iOS 还提供了强制同步的 API:
1 | [[NSUserDefaults standardUserDefaults] synchronize]; |
在早期的 API 中,往往需要开发者会主动调用 synchronize 以确保同步。但 Apple 当前文档已经提示,不要再调用该 API:
1 | Waits for any pending asynchronous updates to the defaults database and returns; this method is unnecessary and shouldn't be used. |
原因是 iOS 已经提供了更智能和高效的机制来自动管理 NSUserDefaults 数据的持久化,系统会在以下几个时机进行数据同步:
- 应用进入后台时。
- 应用即将终止时。
- 系统检测到内存压力时。
而开发者主动调用 synchronize 可能会带来一系列问题,如阻塞主线程、数据冲突等。
2、NSUserDefaults 读、写流程
(1) 写流程
NSUserDefaults 在调用类似 setObject:forKey: 写 API 后,数据同步时内部实际上是通过调用 writeToFile:options:error: 将数据写入磁盘的。writeToFile:options:error: 的内部实现会使用 open、write 和 close 系统调用来实现数据持久化:
- 打开文件(
open):- 创建一个文件描述符,用于写操作。
int fd = open(filePath, O_WRONLY | O_CREAT | O_TRUNC, 0644);
- 写入数据(
write):- 将序列化的 plist 数据写入文件。
ssize_t bytesWritten = write(fd, serializedData, length);
- 关闭文件(
close):- 关闭文件描述符,保存更改。
close(fd);
写主要流程总结:
- 在
open系统调用时,就从用户空间切换到了内核空间,在内核空间获取到文件描述符fd后再返回给用户空间。即执行完open之后,就回到了用户空间。write也是系统调用,也会导致从用户空间切换到内核空间,在内核空间中,操作系统执行实际的数据写操作,其主要流程如下:- 内核从用户空间缓冲区读取数据,并暂时存储到内核缓冲区(页缓存)。
- 内核将数据从内核缓冲区写入到磁盘。
- 如果缓存写(write-back)机制启用,数据写入到内核的缓存区后,不会立即写入到磁盘,当缓存区达到一定条件时再批量写入。
- 数据写完成后,使用
close系统调用关闭文件描述符,释放资源。- 内核会从进程的文件描述符表中移除对应条目,使该文件描述符变得无效。
- 内核会减少与文件描述符关联的文件对象的引用计数,如果减少后的引用计数为零,表示没有其他进程或文件描述符引用该文件对象,内核会释放与文件对象相关的所有资源。
- 内核更新文件的访问时间和修改时间,并将这些元数据和缓存的数据写入磁盘,以确保文件系统的一致性。
其中:
- 内核缓冲区
- 内核缓冲区是操作系统内核用来暂时存储数据的内存区域,是物理内存中的一部分。它们位于内核空间,用户态程序无法直接访问,前述的文件读取时,内核缓冲区指的是页缓存(page cache)。
- 用户空间缓冲区
- 用户空间缓冲区是由用户态程序分配并使用的内存区域,也是物理内存的一部分。它们位于用户空间,程序可以直接访问和操作这些区域。
(2) 读流程
当使用 NSUserDefaults 的 objectForKey 方法来读取数据时,底层流程如下:
- 读取内存缓存:
- 调用
objectForKey:方法时,NSUserDefaults首先尝试从内存中的字典(缓存)中读取数据。 NSString *value = [[NSUserDefaults standardUserDefaults] objectForKey:@"exampleKey"];
- 调用
- 缓存未命中,读取文件:
- 如果数据不在内存缓存中,则
NSUserDefaults从磁盘的 plist 文件中读取数据。
- 如果数据不在内存缓存中,则
- 打开文件(
open):- 使用 open 系统调用以只读模式打开 plist 文件。
int fd = open("/path/to/plist", O_RDONLY);
- 读取数据(
read):- 使用
read系统调用将文件内容读入内存缓冲区。 ssize_t bytesRead = read(fd, buffer, bufferSize);
- 使用
- 关闭文件(
close):- 数据读取完成后,使用
close系统调用关闭文件描述符,释放资源。 close(fd);
- 数据读取完成后,使用
- 反序列化数据:
- 将从文件中读取的 plist 数据反序列化,并存入内存缓存,供后续读取。
读主要流程总结:
- 在
open系统调用时,就从用户空间切换到了内核空间,在内核空间获取到文件描述符fd后再返回给用户空间。即执行完open之后,就回到了用户空间。 read也是系统调用,也会导致从用户空间切换到内核空间,在内核空间中,操作系统执行实际的数据读取操作,并返回结果给用户空间,其主要流程如下:- 由于系统调用
read,CPU 切换到内核态,操作系统内核接管控制。 - 内核通过已打开的文件描述符找到对应的文件,先检查内核缓冲区是否已经缓存了所需的文件数据。
- 如果内核缓冲区命中缓存,则将缓存拷贝至用户缓冲区。
- 如果内核缓冲区没有命中缓存,则先从磁盘读取数据到内核缓冲区,再将内核缓冲区缓存拷贝至用户空间缓冲区。
- 将用户空间缓冲区中的内容返回。
- 因为用户态进程只能访问用户空间的内容。
- 由于系统调用
- 数据读取完成后,使用
close系统调用关闭文件描述符,释放资源。
(3) 简单总结
由前述的读写流程可知,读写的核心操作,分别是 read、write 两个系统调用。
对于上述 read、write 系统调用的主要流程,可用下图表示: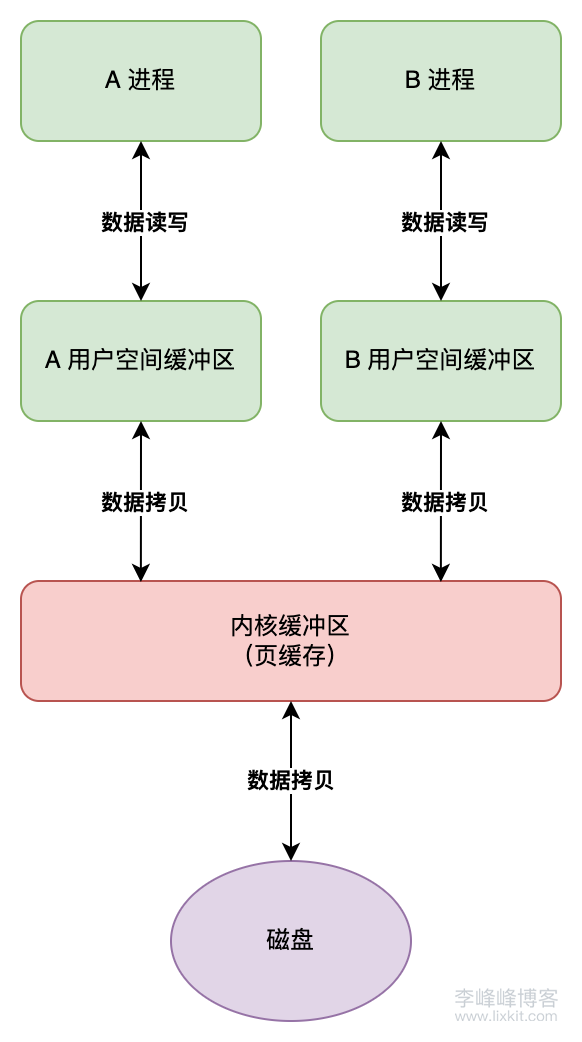
由此可知,传统文件读写,存在下面两个对性能影响较大的操作:
- 至少两次数据的拷贝。
- 需要将文件内容拷贝到用户空间缓冲区,增加内存占用。
- 将
read、write系统调用时参数指定大小的内容拷贝到用户空间缓冲区。
- 将
二、mmap
1、基本使用
mmap 是一个系统调用,它会从用户空间切换到内核空间执行相关操作,然后再返回到用户空间。它用于将文件映射到进程的虚拟内存,使得文件内容可以像内存一样被访问。
mmap 函数原型如下:
1 | void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); |
参数:
addr:请求映射的虚拟地址,如果设置为 NULL,则由系统决定地址。length:映射的字节数。prot:映射的保护标志,指定页面的可访问性(如 PROT_READ, PROT_WRITE)。fd:要映射的文件描述符。offset:文件中开始映射的偏移量。
使用示例:
1 |
|
上述使用总结:
读文件
- 打开文件 (
open):- 调用
open系统调用以只读模式打开文件,获得文件描述符。 - 示例:
int fd = open("example.txt", O_RDONLY);
- 调用
- 获取文件大小 (
fstat):- 调用
fstat获取文件的大小,以确定映射的长度。 - 示例:
struct stat sb; fstat(fd, &sb); size_t filesize = sb.st_size;
- 调用
- 映射文件 (
mmap):- 调用
mmap将文件映射到内存,指定映射区域的保护标志为只读。 - 示例:
char *mapped = mmap(NULL, filesize, PROT_READ, MAP_SHARED, fd, 0);
- 调用
- 读取数据:
- 通过访问映射的内存区域读取文件内容。
- 示例:
printf("File content: %s", mapped);
- 取消映射 (
munmap):- 调用
munmap取消内存映射,释放映射区域。 - 示例:
munmap(mapped, filesize);
- 调用
- 关闭文件 (
close):- 关闭文件描述符。
- 示例:
close(fd);
- 打开文件 (
写文件
- 打开文件 (
open):- 调用
open系统调用以读写模式打开文件,获得文件描述符。 - 示例:
int fd = open("example.txt", O_RDWR);
- 调用
- 获取文件大小 (
fstat):- 调用
fstat获取文件的大小,以确定映射的长度。 - 示例:
struct stat sb; fstat(fd, &sb); size_t filesize = sb.st_size;
- 调用
- 映射文件 (
mmap):- 调用
mmap将文件映射到内存,指定映射区域的保护标志为读写。 - 示例:
char *mapped = mmap(NULL, filesize, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
- 调用
- 修改数据:
- 通过访问映射的内存区域修改文件内容。
- 示例:
memcpy(mapped, "New content", strlen("New content"));
- 同步修改 (
msync):- 调用
msync将修改同步到磁盘。 - 示例:
msync(mapped, filesize, MS_SYNC);
- 调用
- 取消映射 (
munmap):- 调用
munmap取消内存映射,释放映射区域。 - 示例:
munmap(mapped, filesize);
- 调用
- 关闭文件 (
close):- 关闭文件描述符。
- 示例:
close(fd);
- 打开文件 (
2、mmap 原理
(1) 读
操作系统为每个进程分配了虚拟内存,mmap 则是将文件映射到进程的虚拟内存,使得文件内容可以像内存一样被访问。
注意,这里仅是映射,文件的内容并不会立即被拷贝到用户空间的虚拟内存中。mmap 只是将文件与进程的虚拟地址空间关联起来。映射区域的页面在物理内存中并不会马上被分配,文件的实际数据仍然驻留在磁盘上。
当首次访问进行虚拟内存映射区域时,操作系统通过缺页中断将需要的文件页面从磁盘加载到物理内存中。
该主要流程如下:
- 映射文件到虚拟内存
- 使用
mmap系统调用将文件映射到进程的虚拟地址空间。此时,文件的内容还没有实际加载到物理内存中,只有一个虚拟内存区域被分配。
- 使用
- 访问映射的虚拟内存地址
- 应用程序尝试访问映射的虚拟内存地址。这种访问通常包括读取操作。
- 缺页中断
- MMU 将虚拟地址转换为物理地址时,发现该页不在物理内存中,产生一个缺页中断(Page Fault)。
- 内核处理缺页中断
- 内核捕获缺页中断,并检查相应的虚拟内存页表项。它会发现该页是映射的文件的一部分,而实际数据尚未加载。
- 加载页面
- 内核从磁盘读取对应的文件内容,将其加载到物理内存中。通常,这个操作会将整个页(通常是 4KB)读取到物理内存中。
- 更新页表
- 内核更新进程的页表,将虚拟地址映射到新的物理内存地址,并设置相应的权限(只读或读写等)。
- 继续执行
- 缺页中断处理完成后,进程重新开始执行,并继续访问已加载到内存中的数据。
该流程可用下图表示: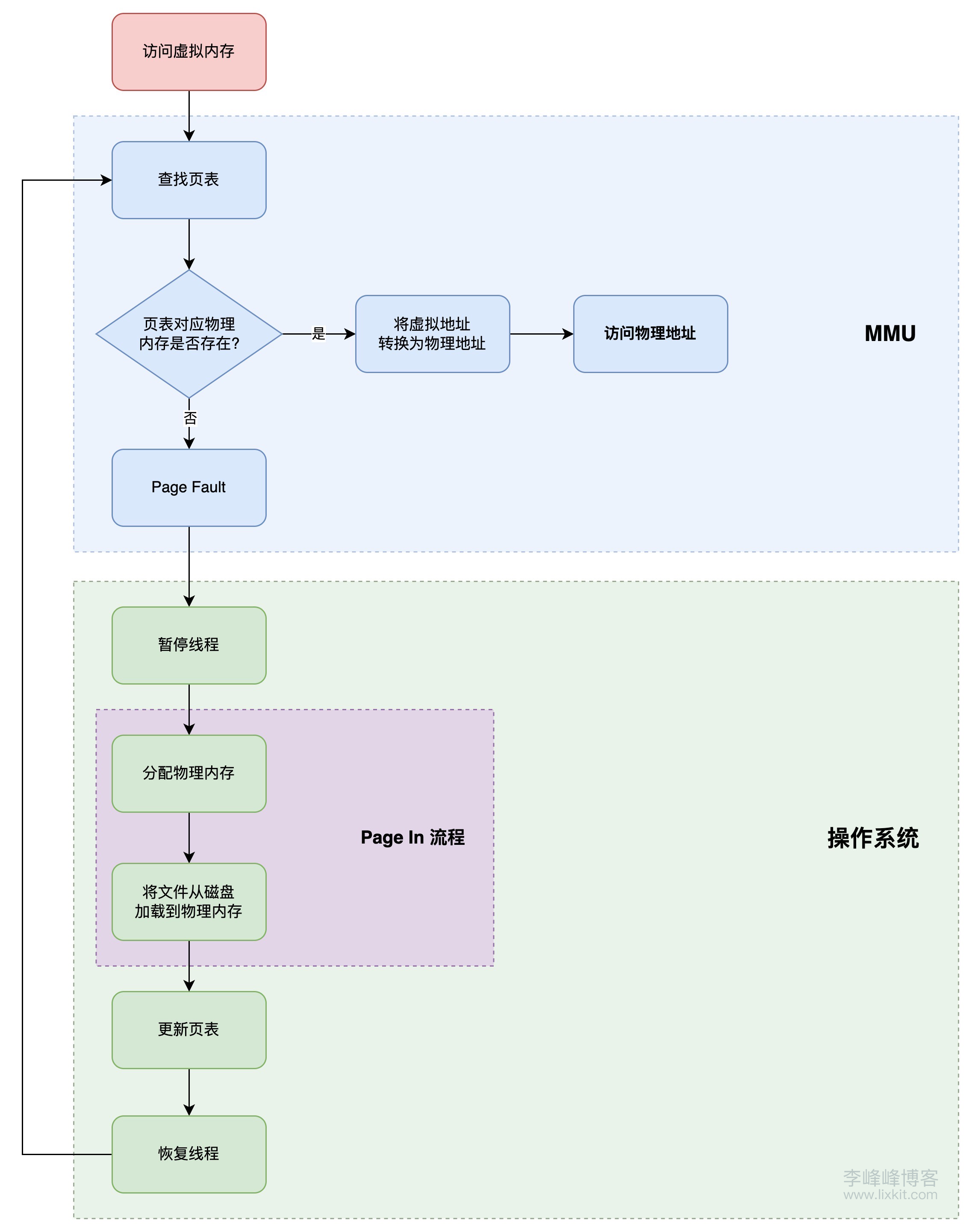
相关更多内容可参考我的另一篇博客: 《APP 启动优化 3-二进制重排》
(2) 写
写主要流程如下:
- 映射文件到虚拟内存
- 与读流程相同,使用
mmap系统调用将文件映射到进程的虚拟地址空间。
- 与读流程相同,使用
- 访问映射的虚拟内存地址
- 应用程序尝试写入映射的虚拟内存地址。这可能会触发缺页中断,如果该页尚未加载到物理内存中。
- 缺页中断
- 如果写入的页尚未在物理内存中,则会触发缺页中断,内核开始处理。
- 加载页面
- 内核从磁盘读取对应的文件内容,并将其加载到物理内存中。这通常是为了保持文件的一致性,即使是在写操作时。
- 更新页表
- 内核更新页表,将虚拟地址映射到物理内存中的副本页,并设置相应的权限(读写)。
- 写入数据
- 应用程序将数据写入物理内存。
- 脏页标记
- 修改的页被标记为脏页,表示内存中的数据与磁盘上的数据不同步。
- 同步到磁盘
- 内核的页回写机制负责将脏页的数据写回到磁盘。这个过程可以通过
msync系统调用手动触发,也可以通过内核定期的页面回收机制自动进行。
- 内核的页回写机制负责将脏页的数据写回到磁盘。这个过程可以通过
- 清除脏页标记
- 一旦数据写回到磁盘,脏页标记被清除,表示内存和磁盘数据再次同步。
操作系统内核并不会立刻把 mmap 映射的页缓存同步到磁盘,同步内存到磁盘有 4 个时机:
- 调用
msync函数主动进行数据同步。 - 调用
munmap函数对文件进行解除映射关系时。 - 进程退出时。
- 系统关机时。
对于“进程退出时”、“系统关机时”两个时机,由操作系统自动完成,操作系统在对应时机自动完成同步到磁盘的工作。也就是说,一旦将内容写入到物理内存后,即使 APP 发生 Crash,操作系统也可以将这些数据写入到磁盘。
(3) 简单总结
使用 mmap 读写文件时,mmap 会在磁盘、进程虚拟内存之间建立内存映射关系。当进程读写文件时,是针对虚拟内存进行读写的,当 MMU 检测到物理内存中并不存在虚拟内存对应的内容时,会触发缺页中断,将文件内容拷贝到物理内存中。后续再对访问虚拟内存中的内容时,在 MMU 的配合下,就访问操作物理内存中对应的内容了。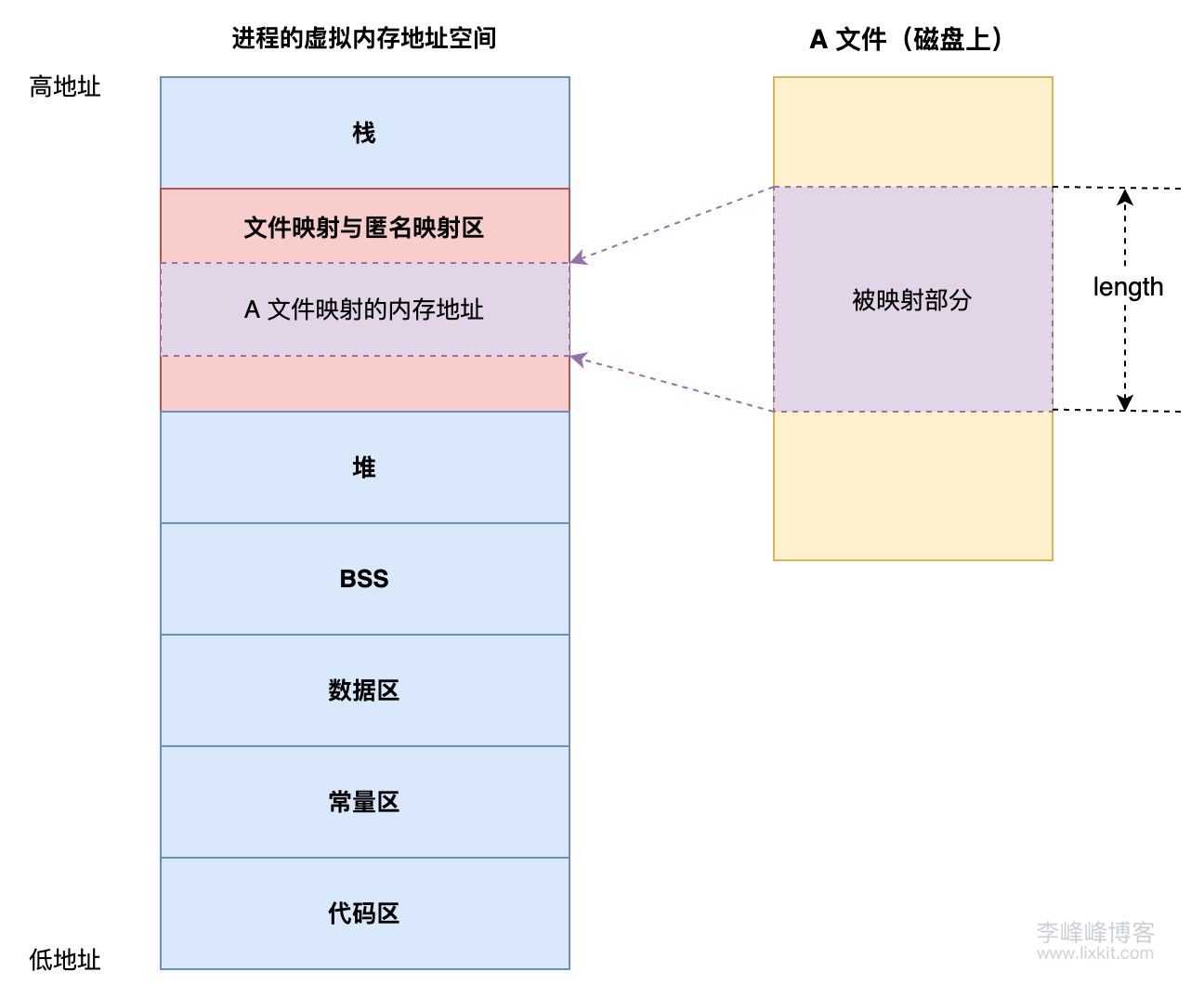
注意,虚拟内存地址空间实际上是一个映射表,指向物理内存中的实际数据,虚拟内存并不直接存储数据。进程访问虚拟内存时,是通过虚拟内存地址空间的映射关系,直接访问物理内存中的数据。所以访问虚拟内存时,并不涉及往虚拟内存的数据拷贝,只是地址的映射和访问。也就是说,文件内容会存在于两个地方:物理内存、磁盘。
该过程可以用下图表示: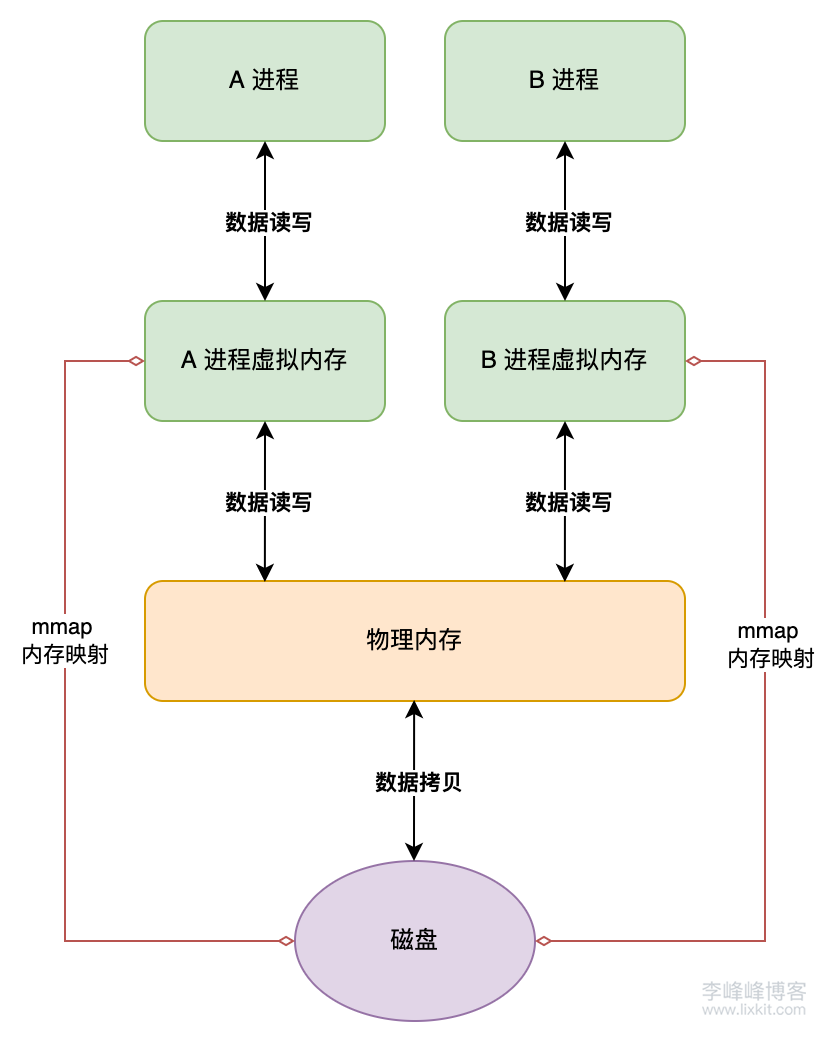
mmap 相较于传统文件读写方式,主要区别如下:
- 文件内容拷贝次数不同
- 传统方式需要两次拷贝:磁盘 -> 内核缓冲区 -> 用户空间缓冲区
- 因为进程只能访问自己用户空间缓冲区,不能访问内核缓冲区,所以必须把内容拷贝到用户空间缓冲区才能访问。
- 内核缓冲区、用户空间缓冲区都是物理内存的一部分,所以同一份内容,会在物理内存中存在两份。
mmap方式仅需一次拷贝:磁盘 -> 物理内存- 由于
mmap有更少的数据拷贝次数,所以在效率更高、内存占用更少
- 由于
- 传统方式需要两次拷贝:磁盘 -> 内核缓冲区 -> 用户空间缓冲区
- 文件内容加载时机不同
- 传统方式:直接将文件内容加载到了物理内存。
mmap方式:访问具体内容时才会加载到物理内存。- 因为文件数据在访问时才被加载到内存中。相较于直接读取文件到内存缓冲区,
mmap不需要一次性加载整个文件,降低了内存使用的峰值。
- 因为文件数据在访问时才被加载到内存中。相较于直接读取文件到内存缓冲区,
- 写入时机不同
- 传统方式:需要进程显式同步,进程如果发生 Crash,数据可能无法及时写入到磁盘。
mmap方式:操作系统可以自动完成,可以不需要进程参与。操作系统的页面缓存机制可以提高写入的可靠性,减少了数据丢失的风险。
三、MMKV 与 mmap
MMKV 是腾讯开源的高性能 Key/Value 存储库,MMKV 使用 mmap 进行文件读写,数据序列化使用的是 protobuf 协议,其性能比传统文件读写方式更好。
其中 Protobuf(Protocol Buffers)是由 Google 开发的一种序列化数据格式,广泛用于数据的高效序列化和反序列化。Protobuf 提供了一种结构化数据的描述语言(.proto 文件),能够生成高效的二进制序列化代码,并支持多种编程语言。
.proto 后缀的文件(person.proto)消息结构示例:
1 | syntax = "proto3"; |
Protobuf(Protocol Buffers)是一种轻量级、跨平台的序列化数据格式,常用于前后端或服务之间的数据交换。其通信流程通常包括以下步骤:
- 定义消息结构(.proto 文件)
- 开发者首先在 .proto 文件中定义数据结构,包括消息类型、字段类型和字段编号。
- Protobuf 建议在修改 .proto 文件时,不要删除或更改已有字段的编号或类型,而是通过添加新字段的方式进行扩展。这样可以确保旧版本和新版本之间的兼容性。
- 生成代码
- 使用 protoc 编译器根据 .proto 文件生成客户端和服务端对应语言的代码(如 Java、Python、Objective-C 等)。这些代码包含了序列化和反序列化功能。
- 也就是说,各端使用相同或兼容的 .proto 文件生成代码。
- 序列化(客户端或服务端)
- 客户端或服务端将需要发送的数据对象序列化为 Protobuf 二进制格式。序列化是将数据结构按照字段编号和类型编码成紧凑的二进制数据。
- Protobuf 消息的每个字段,都有一个编号,例如前面
Person的id编号为 1、name编号为 2,在序列化为二进制时,字段名并不参与序列化,而是使用编号代替字段名。所以只要前、后端字段编号一样即可,字段名无须保持一致。
- Protobuf 消息的每个字段,都有一个编号,例如前面
- 客户端或服务端将需要发送的数据对象序列化为 Protobuf 二进制格式。序列化是将数据结构按照字段编号和类型编码成紧凑的二进制数据。
- 数据传输
- 序列化后的二进制数据通过网络传输到另一端。由于 Protobuf 数据非常紧凑,传输效率较高。
- 反序列化(客户端或服务端)
- 接收端收到二进制数据后,使用生成的代码进行反序列化,将二进制数据转换回原始的对象结构(
Model),供应用程序使用。
- 接收端收到二进制数据后,使用生成的代码进行反序列化,将二进制数据转换回原始的对象结构(
该过程可用下图表示: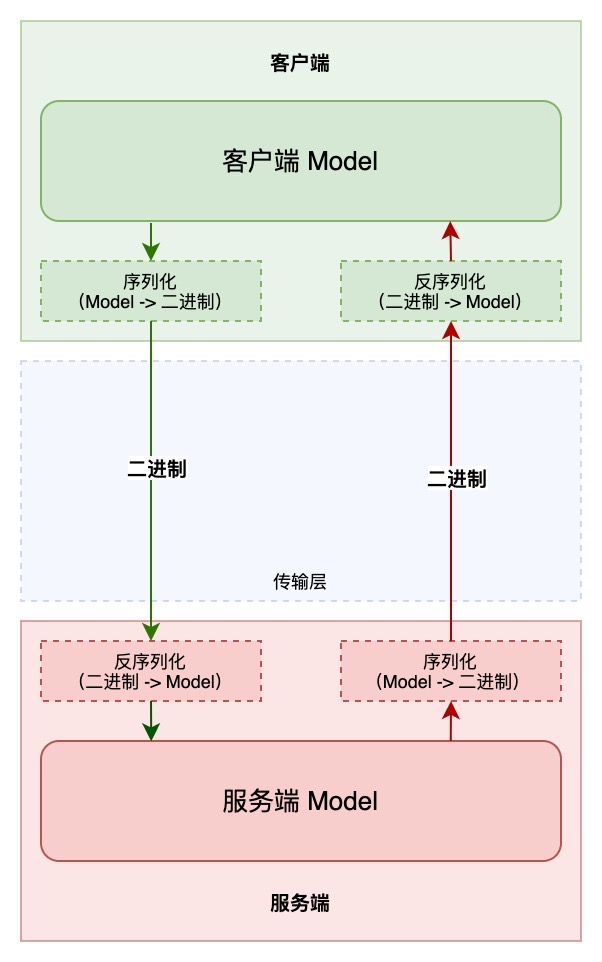
MMKV 的 key 限定 string 字符串类型,而 value 则多种多样(int/bool/double 等),MMKV 先将 value 通过 protobuf 协议序列化成统一的内存块(buffer),确保无论 value 是什么类型,存储使用的类型都是统一的,最后再将这些 KV 对象使用 protobuf 序列化并写入内存中。
该过程伪代码如下:
1 | message KV { |
标准 protobuf 不提供增量更新的能力,每次写入都必须全量写入。考虑到主要使用场景是频繁地进行写入更新,MMKV 需要有增量更新的能力:将增量 kv 对象序列化后,直接 append 到内存末尾;这样同一个 key 会有新旧若干份数据,最新的数据在最后;那么只需在程序启动第一次打开 MMKV 时,不断用后读入的 value 替换之前的值,就可以保证数据是最新有效的。
使用 append 实现增量更新带来了一个新的问题,就是不断 append 的话,文件大小会增长得不可控。例如同一个 key 不断更新的话,是可能耗尽几百 M 甚至上 G 空间,而事实上整个 kv 文件就这一个 key,不到 1k 空间就存得下。这明显是不可取的。我们需要在性能和空间上做个折中:以内存 pagesize 为单位申请空间,在空间用尽之前都是 append 模式;当 append 到文件末尾时,进行文件重整、key 排重,尝试序列化保存排重结果;排重后空间还是不够用的话,将文件扩大一倍,直到空间足够。
该过程伪代码如下:
1 | - (BOOL)append:(NSData*)data { |
-

- 本文章采用 知识共享署名 4.0 国际许可协议 进行许可,完整转载、部分转载、图片转载时均请注明原文链接。